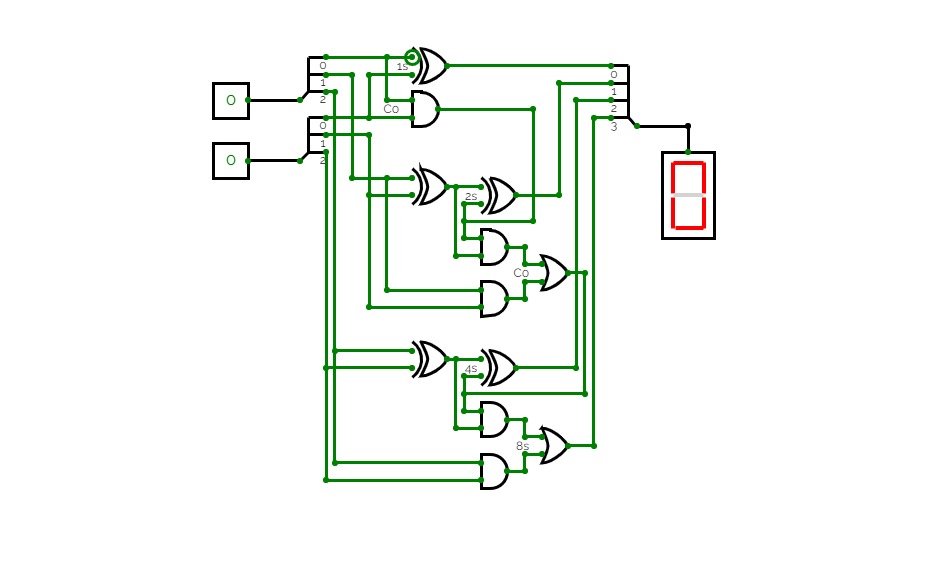
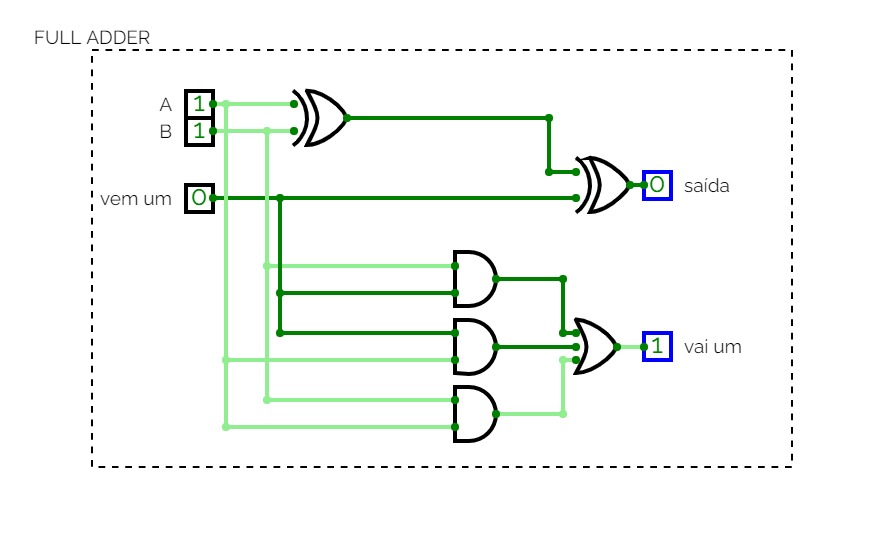
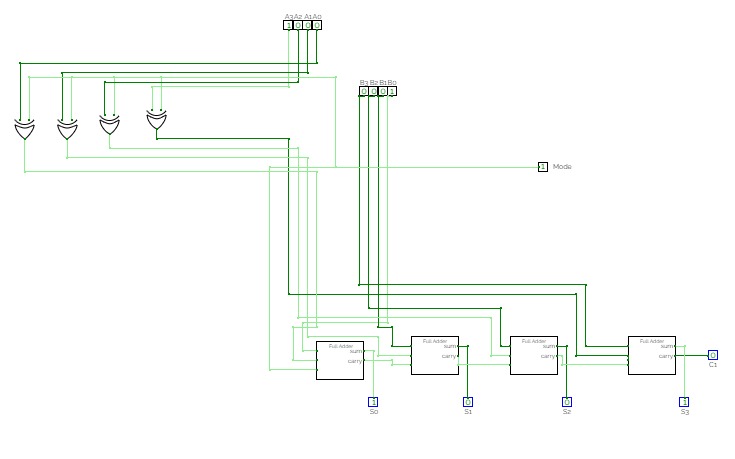
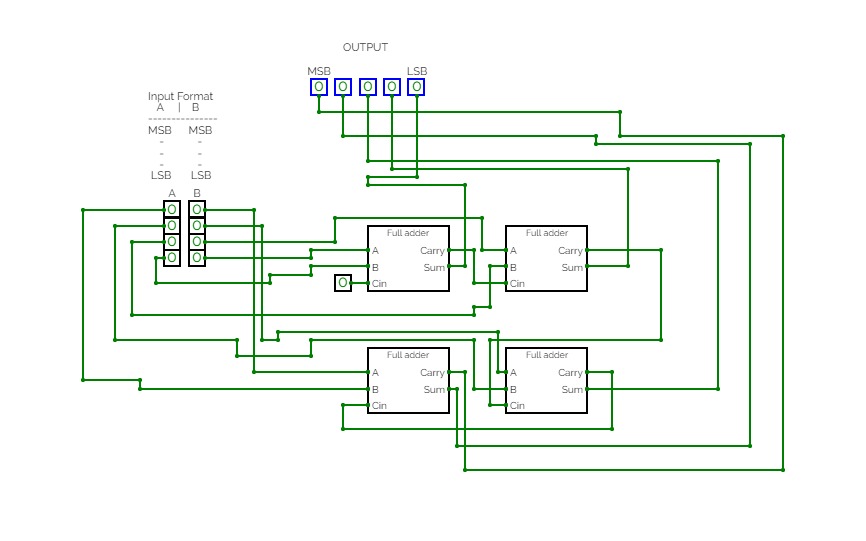
4-bit full adder
4-bit full addernand2tetrisPart1
nand2tetrisPart1Logic diagrams for nand2tetris part 1 (projects 1 to 6).
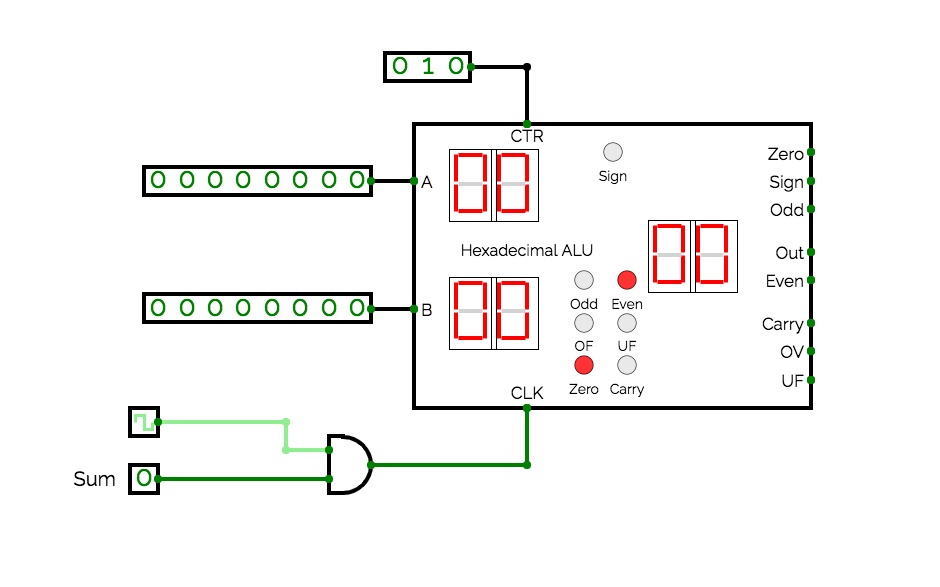
8 Bit CPU
8 Bit CPUThis is a CPU witch is capable of executing a lot of stuff in one clock cycle, and this CPU can shift left up to 7 times and shift right up to 7 times witch means that it is possible to multiply and divide in one clock cycle if you program a table in the program memory. it has a 32 bit instruction width and a 8 bit address. it also has
The ALU has the following operations:
- ADD
- SUBTRACT
- SHIFT_LEFT (up to 7 times per cycle 3 bit)
- SHIFT_RIGHT (up to 7 times per cycle 3 bit)
- XOR
- OR
- NOT
This Was made by miles
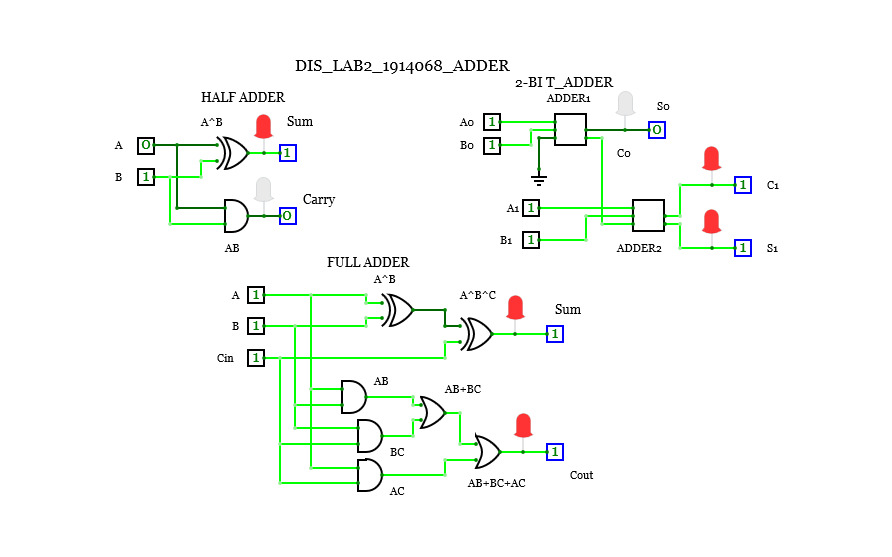
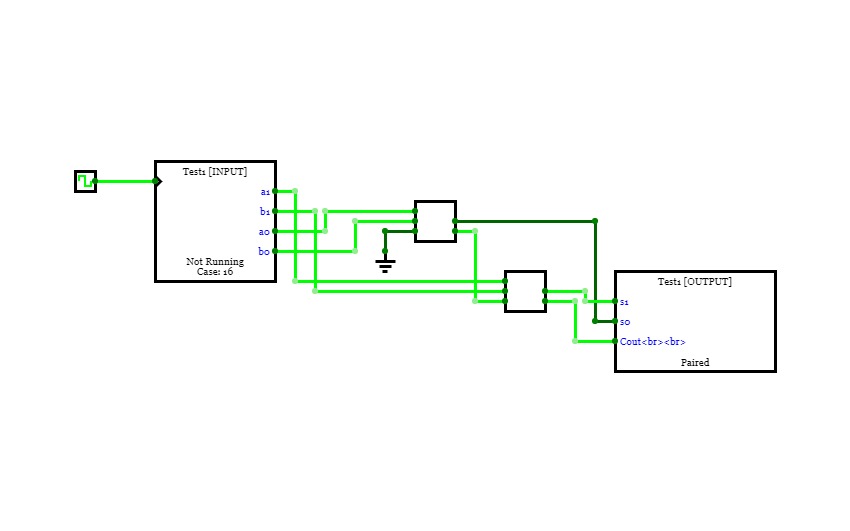

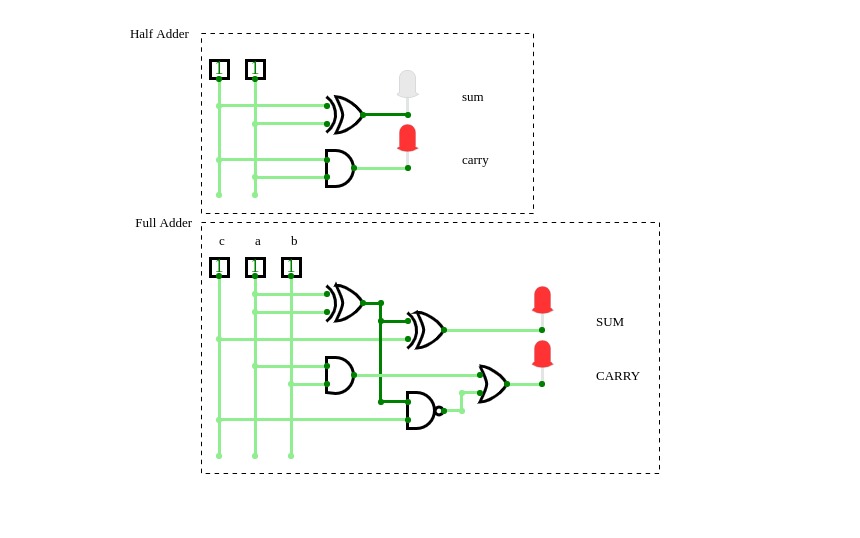
Adders
Adders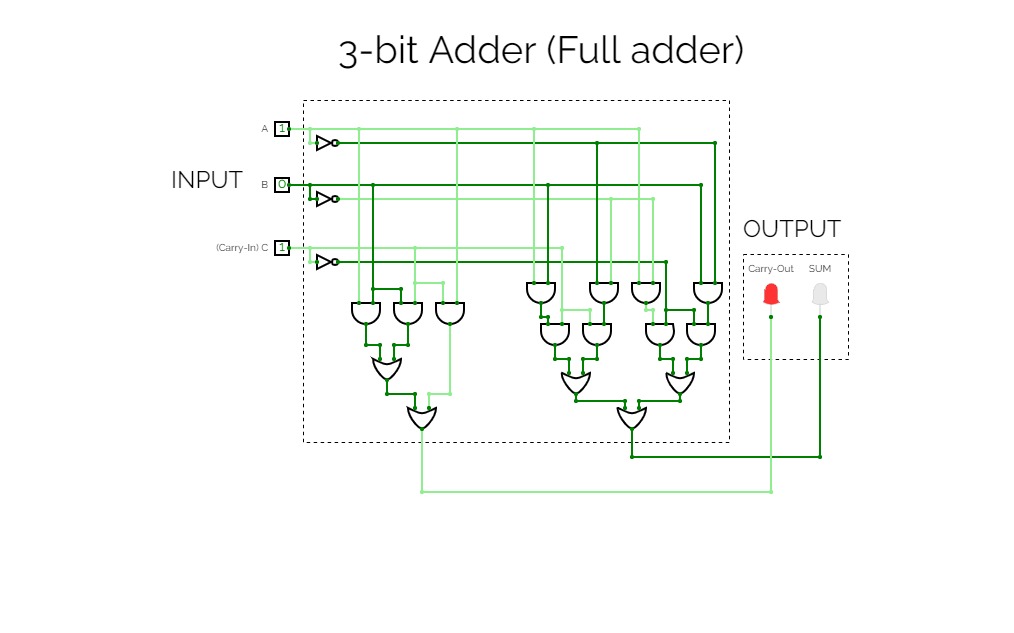
Full adder (3-bit adder)
Full adder (3-bit adder)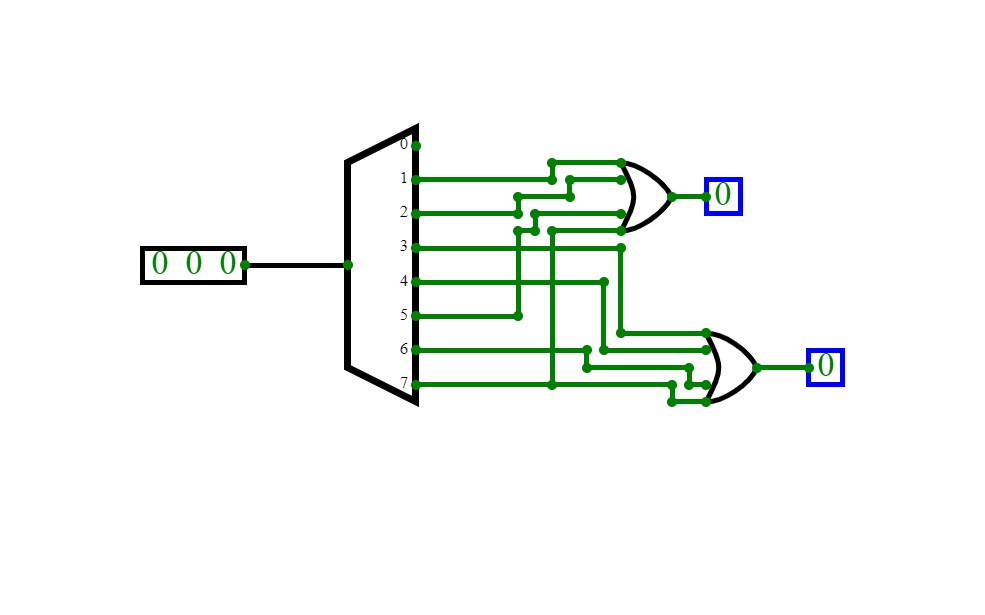
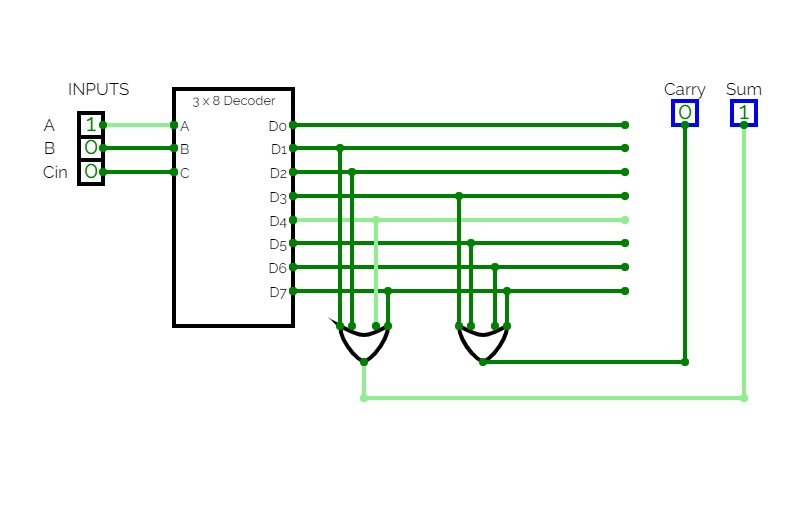
Full Adder Using Decoder IC 74138
Full Adder Using Decoder IC 74138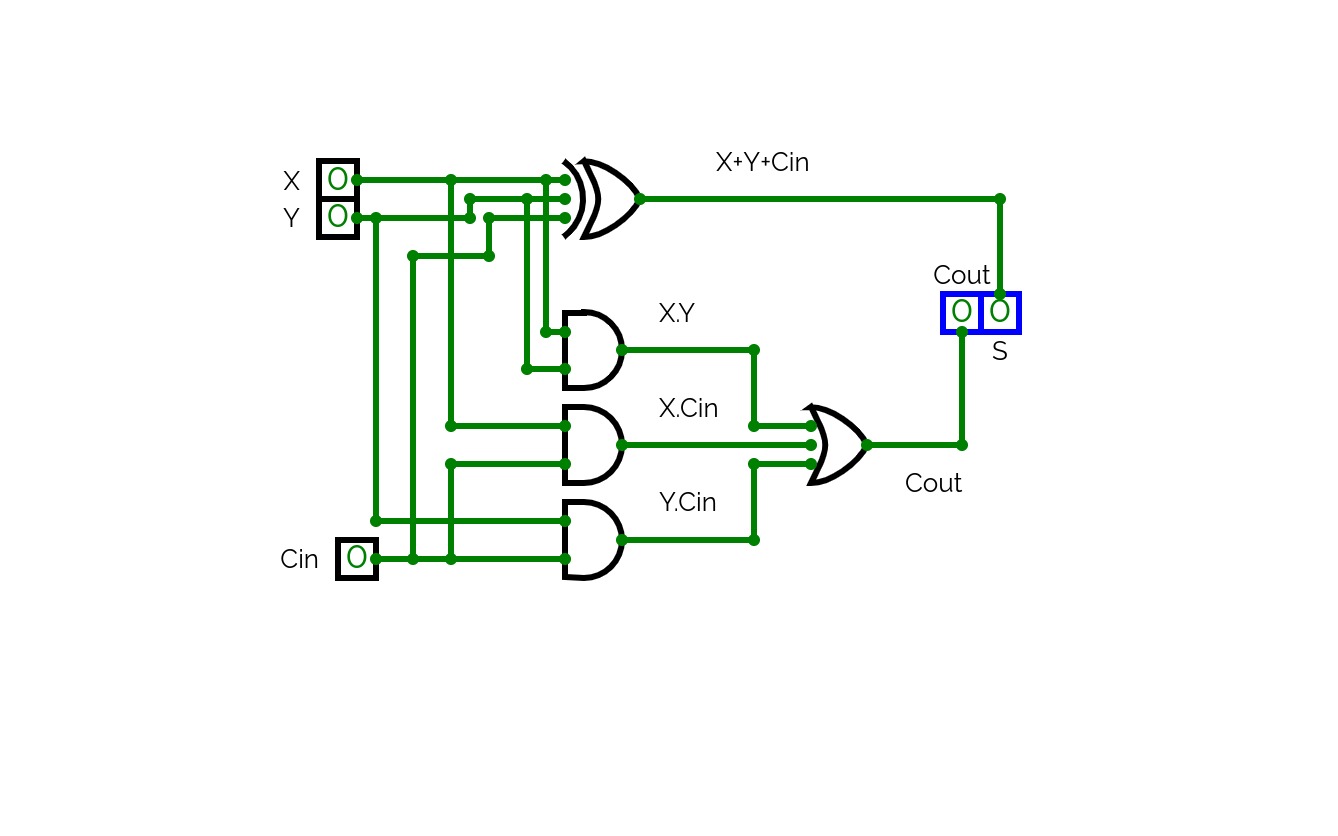


Computational logic
Computational logic1 bit full adder circuit with numerical output display
Half and Fulll Adder
Half and Fulll Adder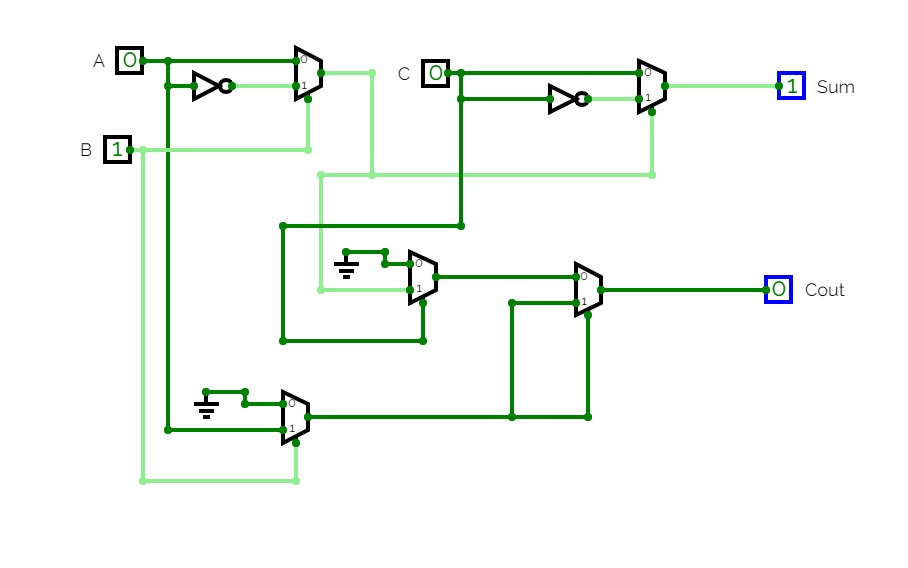
combination-circuit
combination-circuit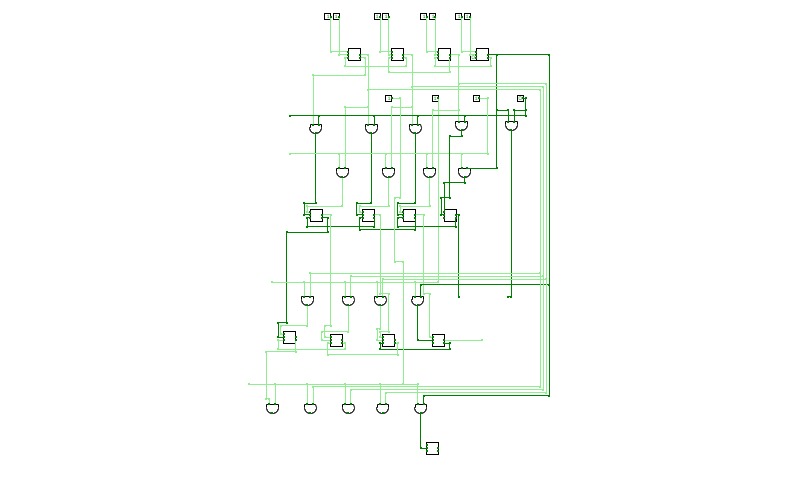

Full Adder
Full AdderFull Adder
Adder circuits
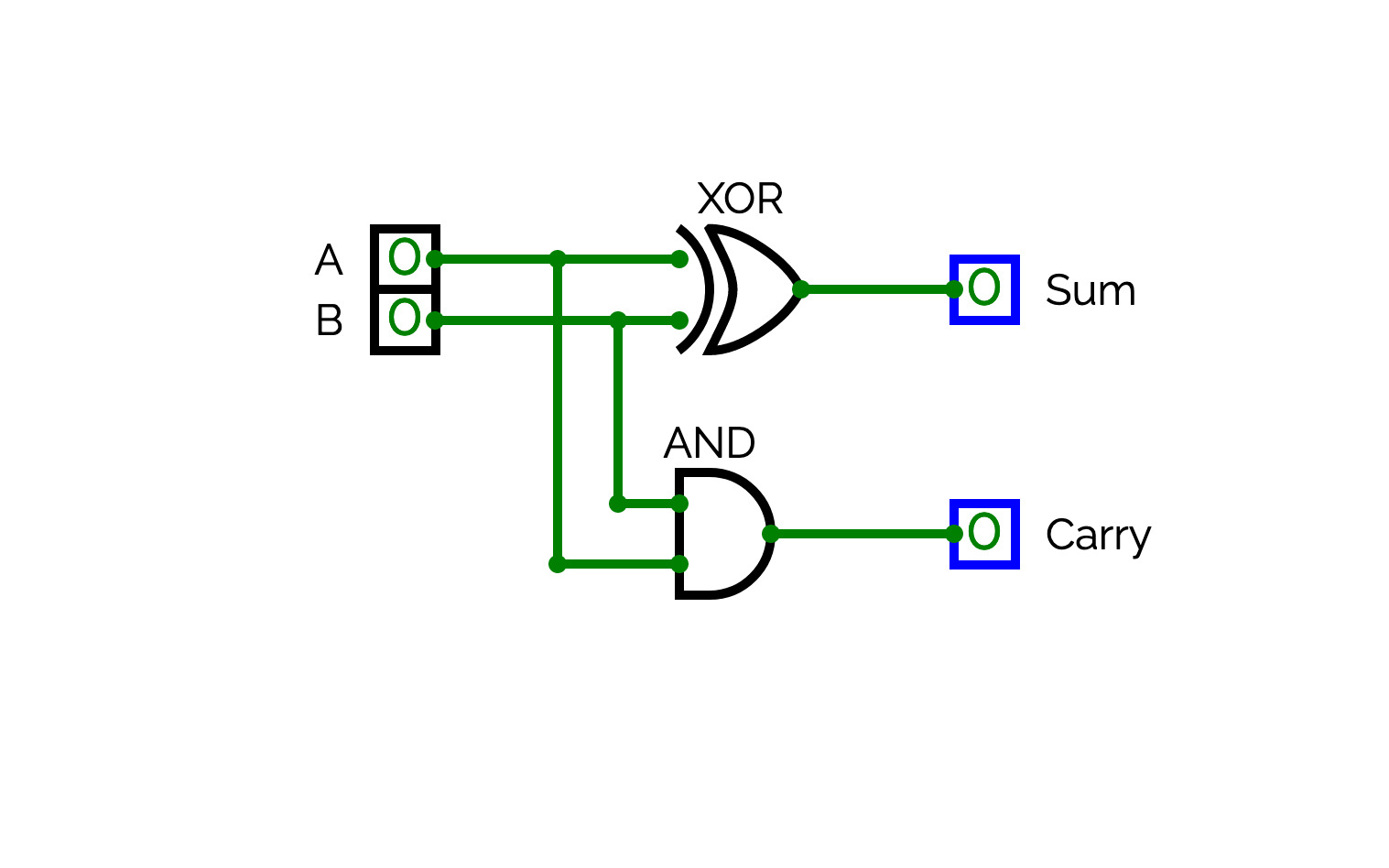
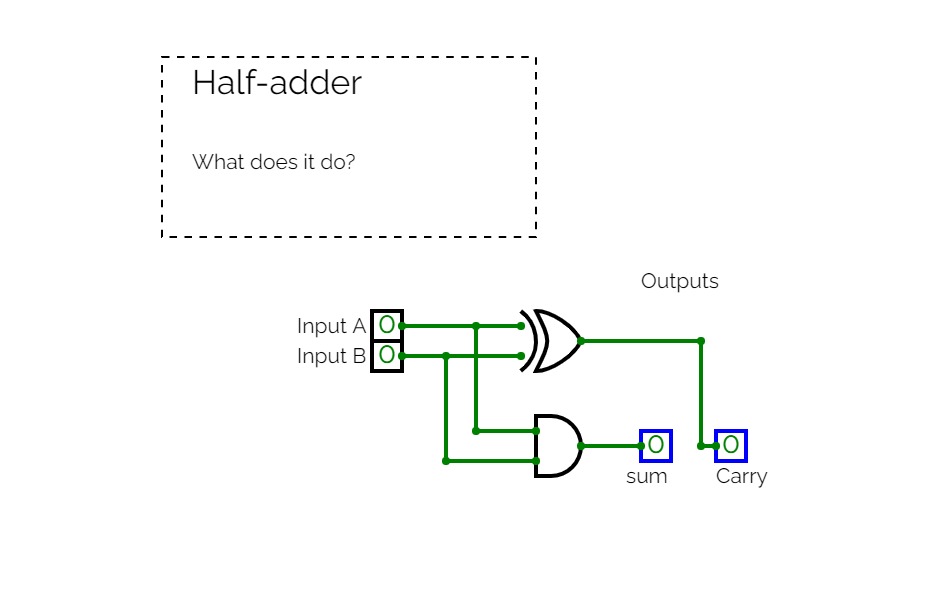
Adder circuitsThis is an half adder circuit, it takes two one bit binary digits and adds them to produce a sum bit and a carry bit, however this circuit is incapable of adding more than one bit binary digit hence it is known as the binary half adder

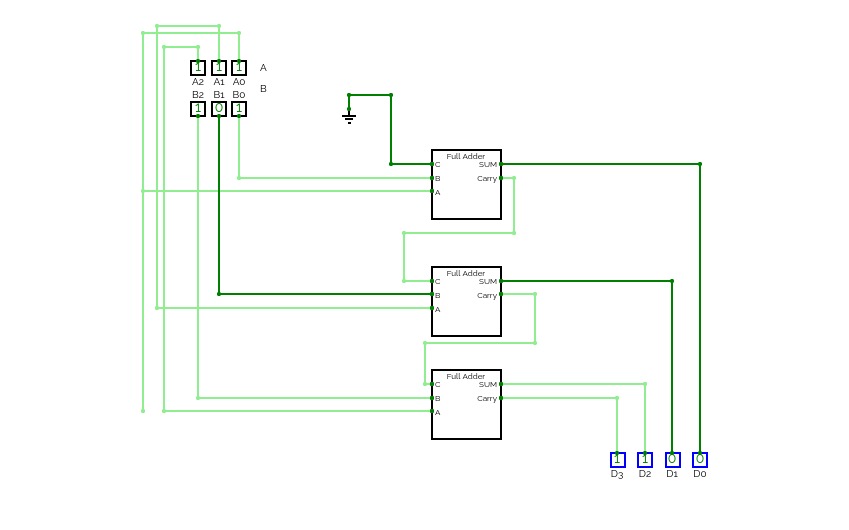
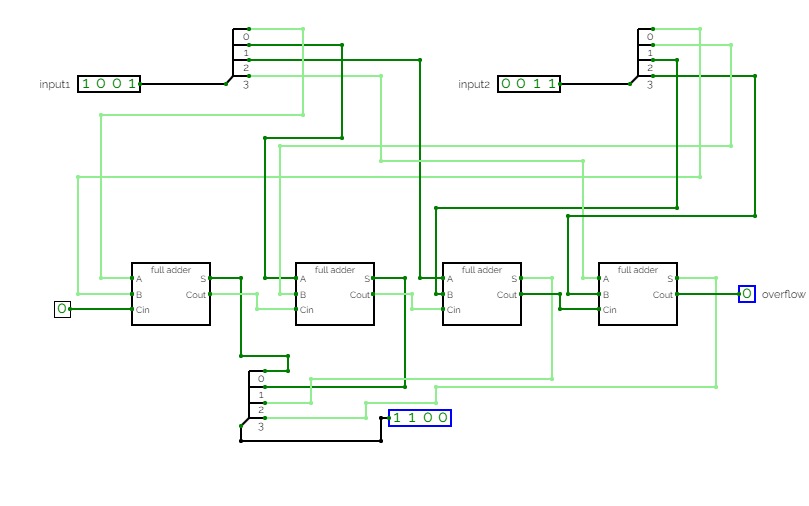
Two 3-bit number Adder
Two 3-bit number AdderA circuit that adds two 3-bit numbers using a half-adder and a full-adder.
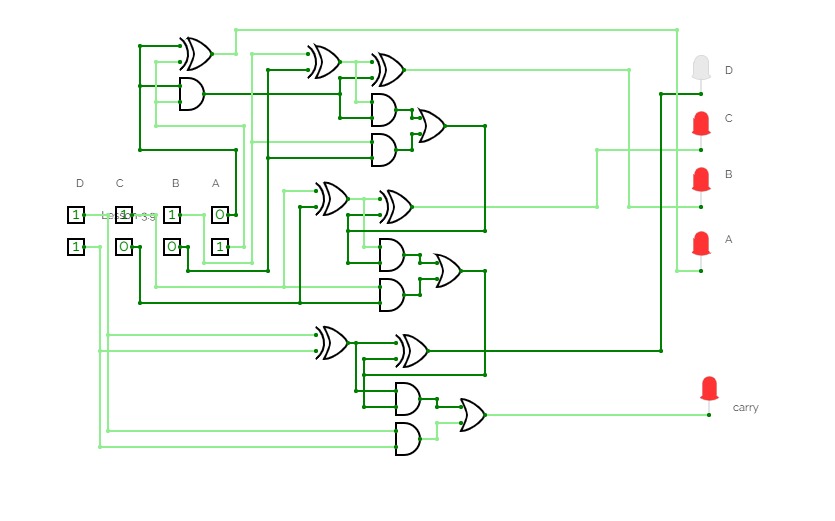
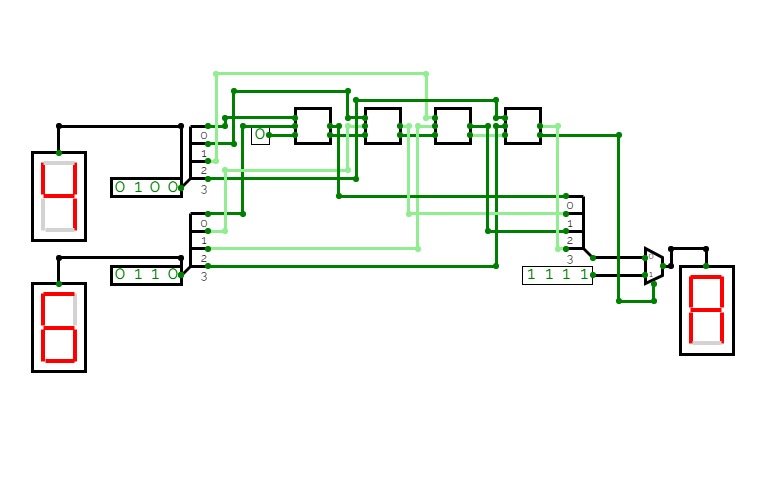
A circuit that takes two decimal numbers A and B as input and then splits in into their corresponding three bits using a splitter and then calculates their summation using XOR, AND and OR gates. This generates 4 output lines for 4 bits of the summation, and a reversed splitter is finally used to join the output lines to produce a 4-bit output and displayed using a Hex-Display.
This is a ripple-carry adder.
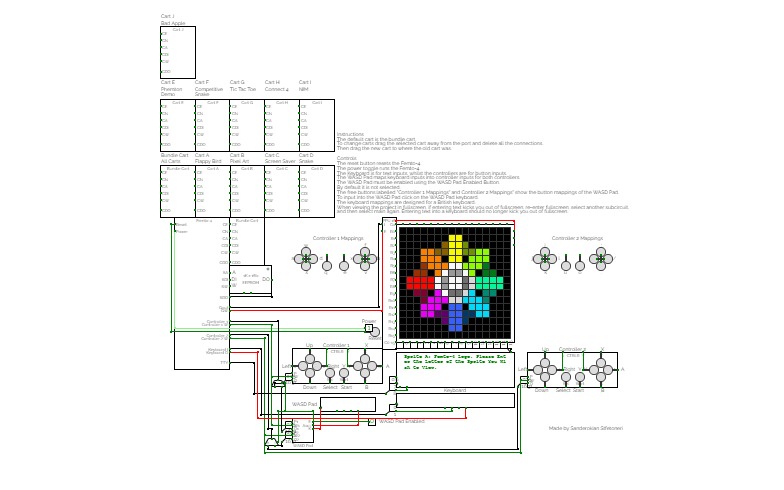

Femto-4v2.6 (Computer)
Femto-4v2.6 (Computer)A 16-bit computer/maybe console inspired thing, the Femto-4. This will be the main branch and backups will be forks from it. This project was started around November 2020.
Currently runs:
- Cart A: Flappy Bird
- Cart B: Some Pixel Art
- Cart C: Screensaver
- Cart D: Snake
- Cart E: Phemton Demonstrations
- Cart F: Competitive Snake
- Cart G: Tic Tac Toe
- Cart H: Connect 4
- Cart I: NIM
- Cart J: Bad Apple
- Bundle Cart: All carts in one
- Cart 2A: 32x32 Snake
- Cart 2B: 32x32 Competitive Snake
- Cart 2C: 32x32 Pixel Art
- Cart 2D: 32x32 Bad Apple
- Bundle Cart 2: All 32x32 carts in one
Assembler:
Compiler:
- https://github.com/Comerstar/PhemtonCompiler/blob/main/PhemtonLiteCompiler/PhemtonDeveloperGuide.txt
The 256-Series:
Full screen Notes:
For some reason, the Femto-4v2.6 only is having issues around caching previous subcircuits. Should you need to use something to unbind key entries from the full screen button, toggle the clock. Previous versions are completely unaffected.
Cart Notes:
Cart A:
- The first cart written for the Femto-4.
Cart B:
- The sprites in the cart are:
- A: Femto-4 Logo.
- B: Madeline from Celeste.
- C: Madeline from Celeste (again).
- D: Part of you aka Badeline from Celeste.
- E: A strawberry from Celeste.
- F: Standing Mario from Super Mario Bros.
- G: Jumping Mario from Super Mario Bros.
- H: Standing Mario from Super Mario Bros 3.
- I: Running Mario from Super Mario Bros 3.
- J: Sanderokian (my own character).
Cart C:
- Enter anything into the keyboard to randomise the colours.
- Enter r into the keyboard to reset the colours.
Cart D:
- WASD Pad is recommended.
- Game settings (enter the letter before starting the game to use the setting):
- e: toggle whether crashing into the edges results in a game over.
- The two modes (with/without edge collisions) have two separate high scores.
- w: change the snake's colour scheme to white.
- r: change the snake's colour scheme to red.
- y: change the snake's colour scheme to yellow.
- o: change the snake's colour scheme to orange.
- p: change the snake's colour scheme to purple.
- a: change the snake's colour scheme to aqua.
- g: change the snake's colour scheme to green.
- b: change the snake's colour scheme to blue.
- m: change the snake's colour scheme to magenta.
- 1: change the snake's colour scheme to pink.
- 2: change the snake's colour scheme to light blue.
- 3: change the snake's colour scheme to the challenge colour scheme with an invisible body.
- 0: randomise the snake's colour scheme.
Cart E:
- The test codes in the cart are:
- 1: Hello World.
- 2: Single Operator Calculator.
- 3: Exponentiation Calculator.
- 4: Fibonacci Calculator.
- 5: Keyboard to TTY Test.
- 6: Keyboard to TTY LDI LID Test.
- 7: Keyboard to TTY LII Test.
- 8: Keyboard to TTY LIA Test.
Cart F:
- WASD Pad is essentially required.
- Game settings (enter the letter before starting the game to use the setting):
- e: toggle whether crashing into the edges results in a game over.
- w: toggle whether the number of wins each player has is tracked.
- s: toggle whether the total score each player has scored is tracked.
- d: display the total wins and total scored.
- r: reset the tracked statistics.
Cart G:
- The small light in the corner indicates which player's turn it is.
- When it is dimmed, it means that the computer is processing that player's turn.
- Game settings (enter the letter before starting the game to use the setting):
- w: toggle whether the number of wins each player has is tracked.
- s: toggle automatic start player swapping. d: display the wins each player has.
- r: reset the wins each player has.
Cart H:
- The bar at the top indicates which player's turn it is.
- When it is dimmed, it means that the computer is processing that player's turn.
- Game settings (enter the letter before starting the game to use the setting):
- w: toggle whether the number of wins each player has is tracked.
- s: toggle automatic start player swapping.
- d: display the wins each player has.
- r: reset the wins each player has.
Cart I:
- Game settings (enter the letter before starting the game to use the setting):
- w: toggle whether the number of wins each player has is tracked.
- s: toggle automatic start player swapping.
- d: display the wins each player has.
- r: reset the wins each player has.
- i: display the game instructions.
- c: toggle the whether player 2 is played by the computer.
Cart J:
- Plays Bad Apple
- There are no further controls
Cart 2A:
- The options are the same as Cart D.
Cart 2B:
- The options are the same as Cart F.
Cart 2C:
- The sprites in the cart are:
- A: Femto-4 Logo.
- B: Sanderokian (my own character).
- C: Alstran (my own character).
Cart 2D:
- Plays Bad Apple on the larger screen
- There are no further controls
Features:
- Immediate, direct, & indirect memory access.
- Jumps & conditional jumps.
- 16-bit address space.
- Switchable memory banks, allowing for a standard cart to hold up to 1MB of data.
- An ALU capable of logical operators, addition, subtraction, shift left, shift right, multiplying, dividing, & other specialised functions.
- Fast execution - can run more than one instruction per clock cycle.
- 16x16 pixel display with 32 sprites and 15-bit direct colour.
- 32x32 pixel display with 32 sprites which can have up to 18-bit direct colour.
- Two controllers, a keyboard mapping for the controllers, & a keyboard for text inputs.
- RNG, TTY, stack, & save memory.
- Von Neumann Architecture.
- Assembler & compiler (written in Python).
- Twelve pre-written carts to play with.
Updates:
v1.0:
- Finished the project and added Cart A.
v1.1:
- Added Cart B, some Pixel Art.
- Fixed GRF, & AXR instructions.
- Made Bootloader clear TTY, Keyboard, & Controller Pushed.
- Updated Cart A & Cart B to make use of AXR instructions.
v1.2:
- Added Cart C, a Screensaver.
- Updated Cart B to respond to the start button on both controllers.
v1.3:
- Added Cart D, Snake.
- Moved to new project to fix issues around searching for projects branched from private projects.
- Removed unnecessary EEPROM banks and write lines from all carts.
- Made Reset clear WRAM and the General Registers.
v1.4:
- Fixed Keyboard.
- Added a Bundle Cart that allows you to view all the carts without changing carts (you must reset the console to view another cart).
- Fixed bug in the standard bank design which wrote data to incorrect addresses.
- Fixed contention issue in Mult.
- Added Annotations to the In Debug.
v1.5:
- Added Snake Player.
- Added Reset & Power labels to the relevant buttons.
v2.0:
- Further optimisation to reduce lag/increase execution speed.
- Added more memory access options.
v2.1:
- Further optimisation of the CU.
- Added a keyboard to controller mapping.
v2.2:
- Continued optimisation and overhaul of the CU.
- Removed old CU & compare circuits.
- Added additional stack access instructions.
- Updated the debug versions with the changes, as well as fixing bugs in the debug versions.
- Designed a Logo for the Femto-4.
- Rewrote Cart C to allow the sprites to be viewed in any order, and added the logo to it.
v2.3:
- Introducing Phemton Lite, the first version of the Femto-4's high level languages.
- Added a link to Phemton Lite's compiler.
- Added Cart E to demonstrate code written in Phemton Lite.
- Combined SpecialD & ROMD1, and removed SpecialD & ROMDB.
- Updated Snake code & Bundle code to match the new addresses.
- Added Cart F, a competitive version of Snake.
- Added an additional sprite into Cart B.
- Fixed issues with LII, LXA & LXP instructions.
v2.4:
- Fixed alignment of the upper carts.
- Added Cart G & Cart H, Tic Tac Toe & Connect 4 written in Phemton Lite.
- Added progress lights to Cart G & Cart H.
- Reworked bundle cart to make the code shorter and more efficient for large numbers of carts.
- Made Cart G & Cart H faster.
- Reshuffled Cart E test codes and added 2 Cart E test codes, exponentiation & Fibonacci calculation.
- Added game options to Cart D, Cart F, Cart G, & Cart H.
- Updated Cart C to allow the colours to be randomised.
- Added optional colour schemes for Cart D.
- Fixed Snake Player.
- Remade the multiply and divide circuits to take advantage of the inbuilt adders.
- Removed old MultM and DivM circuits.
v2.5:
- Further optimisation of the CU.
- Optimisation of the fast execution clocks for the computer, the graphics, & the WASD Pad.
- Fixed debug versions' issues with Phemton conditionals and added optimisations to the debug versions.
- Added 32x32 screen PPU.
- Added Cart 2A, Cart 2B, & Cart 2C, 32x32 versions of Snake, Competitive Snake, & Pixel Art.
- Added Cart I, NIM written in Phemton Lite.
v2.6
- Added the ability to directly write sprites to the PPU during execution.
- Significantly optimised the CU by removing unnecessary subcircuits.
- Introduced significant quantities of lazy evaluation to further improve performance.
- Added Cart J, and Cart 2D, which both play Bad Apple.
- The Femto-4 can now be added to the set of things that plays Bad Apple.
Future Updates:
- More pre-written carts.
- Bug fixes.
- Adding an optimiser to the compiler.
- Phemton Full.
- Phemton Plus.
Do fork the project and write your own code for it! If you want more information on how to do so read the Developer Guide in the assembler.
Note: The Flappy Bird high score and the Snake high score are mine. If you want to save your own scores permanently you will have to fork the project.
The Femto-4

General Architecture: The Femto-4 is a 16-bit, Von Neumann architecture computer with variable length instructions that are comprised of multiple 16-bit words. It has many features associated with CISCs, such as variable length instructions, and multicycle indirect loads, however operates like a RISC, with each instruction taking exactly 1 clock cycle. This was done to give the Femto-4 power whilst keeping its construction simple. First the OP code of the instruction is read, and then depending on the OP code, additional pieces of data may be read for the operands. This allows execution to become incorrectly offset, which can lead to the execution of garbage if the PC is jumped to an incorrect address. This is usually fine, since the OP code space is so empty that the data will likely be passed one at a time until the next valid instruction. Instructions are read from main memory, making this architecture a Von Neumann architecture as opposed to a Harvard architecture. The MAR always specifies the address being read to or written from, whilst the MDR always holds the data being written. Data from the data out bus can be written to most special registers during the instruction. OP codes and operands are all 16-bits. The large OP code size was chosen due to the high number of ALU instructions. There are approximately 500 interpretable OP codes that the computer can handle.
Memory Mapping: The 16-bit address space of the Femto-4 is memory mapped, with all data being stored somewhere in the address space. The last 48kx16b of memory (all addresses starting with 0b01, 0b10, or 0b11) are dedicated to the cart memory. This is where the interchangeable program would be stored, allowing programs to be easily changed by changing carts. The carts have 32 16kx16b EEPROM/RAM chips, which can be switched between during execution by writing to address 0x00cc. This gives each cart 512kx16b of memory to play with. In theory, additional memory can be added in a cart by creating a similar system on the inside of the cart, which would allow it to swap between even more EEPROM/RAM chips. The initial 16kx16b are therefore mapped to everything else, including a fixed WRAM chip that cannot be switched out, the bootloader, the PPU data, general registers, the stack, inputs, outputs, and a few special registers, such as the protect, mode, and flag registers.
Fast Execution: Execution at the fastest clock speed (one pulse every 100ms, or 10Hz, which is defined as the clock changing state every 50ms, or at a rate of 20Hz) is terribly slow, and would make reasonable graphics effectively impossible. Due to this, the Femto-4 includes several execution modes that allow the computer to run much faster. There are two registers involved in this, address 0x00ca, the mode register, and address 0x00cb, the protect register. When the two least significant bits of the mode register are low, the computer runs normally, executing 1 instruction per clock pulse. When bit 0 is set high, the computer enters fast execution on the rising edge, where it executes multiple instructions per clock pulse. This is achieved by looping an inverter into itself, producing a loop that will pulse indefinitely until the looping line is stopped by some external factor. Stopping the loop is critical since leaving the loop running will stop CircuitVerse's execution, due to it going over the stack limit of the execution. Fast execution is always paused by a 0x0000 and 0x0001 OP Code. Bit 2 enables falling edge fast execution, which can be done with rising edge fast execution producing dual edge fast execution. Setting the third bit of the mode register high will enable protection. This will ensure that computer only executes as many instructions as the value in the protect register. This protects execution by ensuring that the loop will always pause before the cycle limit is reached. Since some operations are far more complex than other operations, the maximum number of instructions per clock pulse is variable, and testing should always be conducted to ensure that the limit is not reached. Due to this, for games that need regular graphics updates, it is recommended that protection is not used, and instead the pauses are fully code controlled. On the other end of the mode register are the graphics mode. The highest two bits give the graphics update mode, 0b00 for falling edge only (normal speed), 0b01 for dual edge (double speed), 0b10 for every other clock pulse (half speed), and 0b11 for code controlled, where the 0x0001OP Code is required to update the graphics. The third most significant bit is the graphics disable bit. Setting it high stops updating the graphics, reducing lag by prevent the graphics fast execution loop from running. The mode and protection values are only updated on the rising edge of the clock pulse, and therefore there should always be pauses before and after any execution mode or protection change. By default, the Femto-4 executes with a protection value of 16, to allow the carts to run smoothly, however, depending on the instructions being used, that number can be raised to 64.
Graphics (16x16): The Femto-4 is capable of driving a 16x16 15-bit direct colour screen. It has space for 32 sprites which are rectangles with an assigned colour. All the sprites are drawn to the screen whenever a graphics update occurs, depending on the graphics mode. When using dual-edge fast execution, the falling edge should only be used to execute game code, since writing graphics data as the screen is being drawn may mess up the graphics. These 32 sprites have their data stored in the PPU RAM in the following format: The first 16 bits are the corners of the rectangle, with each coordinate being 4 bits. The coordinates are ordered x coordinate 1 (4), x coordinate 2 (4), y coordinate 1 (4), y coordinate 2 (4). The second coordinates are offset up by 1, to allow the full screen to be drawn to, such that the dimensions of the rectangle are (x2 - x1) + 1 and (y2 - y1) + 1. The next 16 bits are the sprites colour, with the first 15 bits being used for 15-bit direct colour, and the last bit being used to enable or disable drawing the sprite. The last bit is important to ensure that blank sprites are not drawn to the screen. Since the screen is not wiped every time it is refreshed, the background must be a sprite to ensure that the screen is fully wiped before the rest of the sprites are drawn on. Control of this allows carts to draw a single frame over multiple updates, allowing the 32-sprite limit to be bypassed (see how Snake works). The sprites are drawn in memory order, with the sprite with the largest address always being drawn last and therefore on top, of all other sprites. This is achieved by using the exact same system as fast execution, which reads off all the sprite data and draws them to the screen in a single clock pulse. This can loop more times safely than the main CPU since it has less dependencies which dramatically decreases the simulation's stack usage.
Graphics (32x32): The Femto-4 can also drive a 32x32 screen, with sprites able to be drawn through 3 different modes. The 32x32 screen PPU treats the addresses as one combined 32-bit value, with the value with the smaller address going first. The first 3 bits of the 32 bits define the mode. Only the values 1, 2, 3, correspond to actual sprites, whilst the rest are not drawn to the screen. Mode 1 splits the remaining 29-bit space as the following: unused (1), x coordinate (5), y coordinate (5), red (6), green (6), blue (6). Mode 2 splits the 29-bit space in the following way: x coordinate 1 (5), x coordinate 2 (5), y coordinate 1 (5), y coordinate 2 (5), red (3), green (3), blue (3). Mode 3 splits the 29-bit space in the following way: unused (3), x coordinate (5), y coordinate (5), red (5), green (5), blue (5), alpha/transparency (1). As with the 16x16 screen, Mode 2's second coordinates are offset by 1 resulting in rectangles having the dimensions of (x1 - x2) + 1 and (y1 - y2) + 1. Mode 3 is designed to allow the colours used in the 16x16 screen to be the same, making converting code between the two versions easier. The update mechanism is the same as 16x16 screen.
ALU: The basic ALU was inspired by the ALU-74LS181. It was designed to flexibly change between various operations by changing an additional piece of data which is bundled in the OP code. This allows a single ALU to handle all the required processes, such as the basic binary logic operations, shift left, adding, and subtracting, reducing the number of circuits required, as well as the logic required to decide which instruction to use. The Femto-4 also can multiply, divide, shift right, shift left/right by a specified number of bits, and perform operations designed to work with the computer's graphics data.
Conditional Jumps: The Femto-4 can perform immediate and direct jumps depending on the flags, a specified bit of the accumulator, and the clock. The flag jumps allow for comparisons to be made. There are three flags, the carry, the most significant bit in the accumulator, and if the accumulator value is 0, the equals flag. By performing A-B, we can compare A and B by looking at the flags. If the equals flag is true, then A=B, since A-B = 0. If the most significant bit is 0, then the number is positive or 0 (by two's complement) and therefore A>=B. The comparison is not entirely correct for numbers in two's complement (a large positive number and a large negative number when subtracted can yield a positive number), but for small values it works well. Whilst we cannot directly check A<=B using A-B in this design, we can simply flip the subtraction to B-A to do so. The accumulator bit testing is mainly used to check for controller inputs. Since each button in the controller is mapped to one bit, bit testing that bit effectively allows us to check if a button has been pressed. A similar test could be performed using an AND instruction, and checking if the result is equal to 0 or not. Bit testing is most useful for testing an input from both controllers, since it can cut out an additional instruction. The jump on clock is there to ensure that we can jump execution on the right clock pulse, which ensures that graphics can be updated on the edge of execution.
Timing: The computer is timed using several standard delay chips. The pulse length running in to the computer is about 10k units long. Therefore, different parts an instruction are separated by 20k unit delays. Further control of timings inside these periods is achieved through 1k "On Delays", which have a 1k delay turning on, but a 0k delay turning off, ensuring that pulses do not bleed into the next pulse. These pulses can tell registers to write and what source to write from, enable the read and write lines, update the ALU, and update the stack Each instruction is separate by 600k of delay in fast execution. For more information on how delay works see here: https://circuitverse.org/users/4699/projects/circuitverse-delay-introduction.
Keyboard Mapping: The Femto-4's keyboard controller mapping was created using a specialised chip. This chip used the fast execution loop to take 15 inputs from a keyboard and map the inputs to button presses on the controllers. Since the buttons are updated several times in a clock pulse, the keyboard controller cannot handle held buttons. The keyboard mapping is designed to work with both controllers, allowing two player games to be feasible on the computer.
Assembly: The Femto-4 has an assembler that converts assembly written in a .txt into hex values in a .txt that can be copied and loaded into the EEPROM banks for storage. The assembler can handle symbol assignment, as well as assigning addresses in the code symbols to make handling jumps easier. For full details on the Femto-4's assembly language view the assembly developer guide.
Phemton: Phemton is the Femto-4's high level language, with a compiler to compile it's code into Femto-4 assembly. Phemton handles variable memory assignment, basic array assignment, if, elif, else statments, while loops, for loops, and functions. Phemton Lite is the only compiler complete, and lacks an optimiser. Phemton Lite has the concept of local scope only when compiling. All uniquely identified variables are given a global address. This reduces the runtime load since the computer does not need to decide where the variables need to go during run time. Future planned additions include generated code optimisations and optimisers, Phemton Full, which has dynamic memory assignment, and Phemton Plus, which adds additional types for floats and longs. For more details view Phemton's developer guide.
Other Notes: The memory wrappers allow external chips to interact with the main data control system, in this case used for RNG, controllers, the keyboard, and driving the text output. This makes it easy to additional chips to the computer. All assembly and Phemton code can be found in the project for the Femto-4's assembler and compiler respectively. The save data cart must be located outside of the Femto-4 circuit to ensure that its contents are automatically saved. Sorry about all the copies of this computer clogging up the top of the search results.
For more information, please read the developer guide found in the Femto-4's Assembler, or just post a comment and ask me.
This is a secret to everybody, unless you found it.
half_adder
half_adder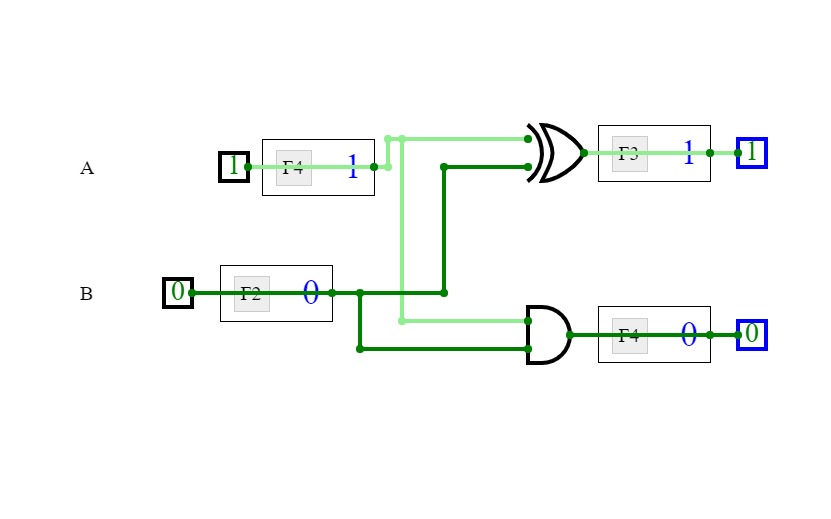
full adder
full adder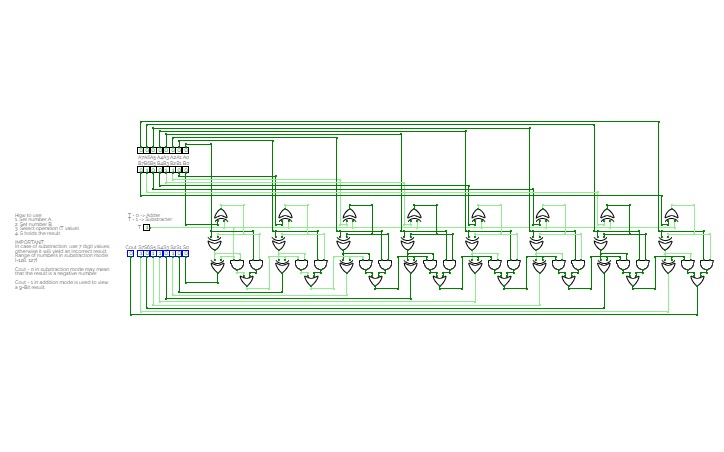
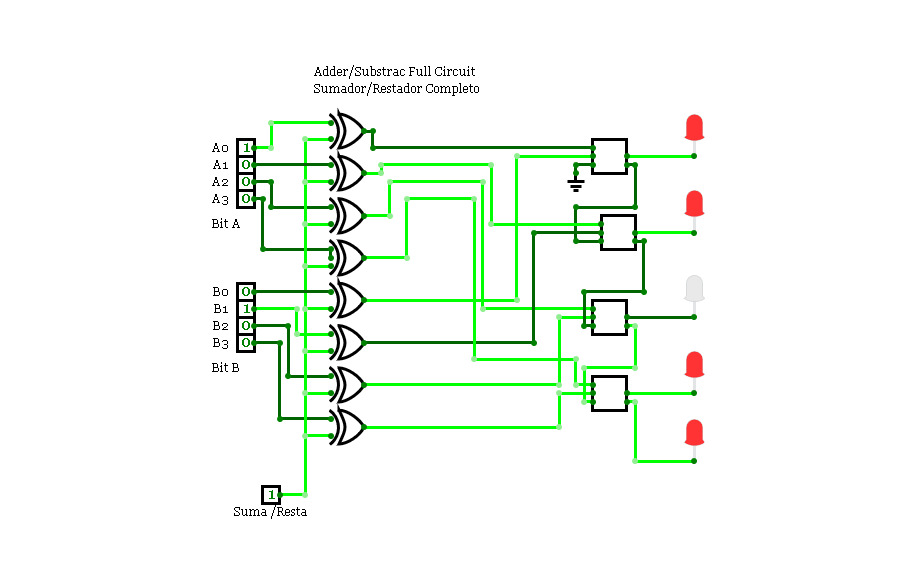
8-bit full adder
8-bit full adderA simple 8-bit full adder / substractor.
S will compute the result of A + B or A - B
Use 7 bit numbers in subtraction mode (at least for B, to prevent an overflow).

8-Adder
8-AdderAn adder complex(?) that I constructed with 8 full adders.
Here's the video I used as a guide.
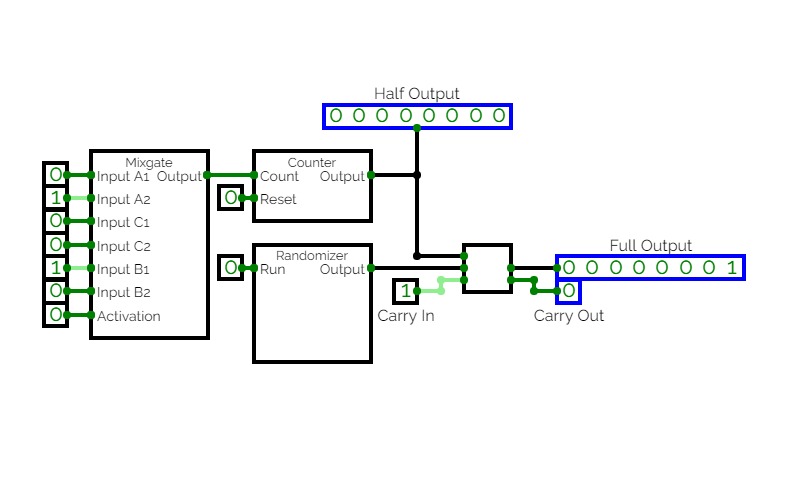
Subcircuit Test
Subcircuit TestMy first experiment with Subcircuits.
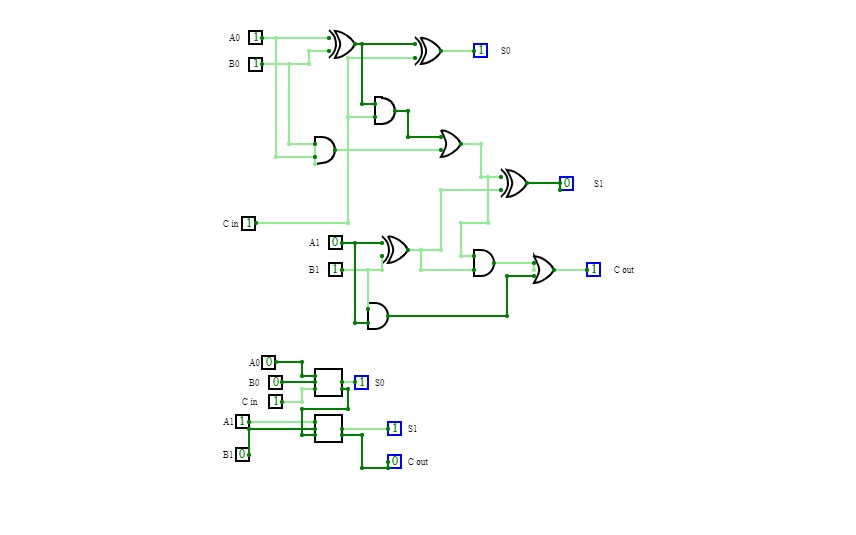
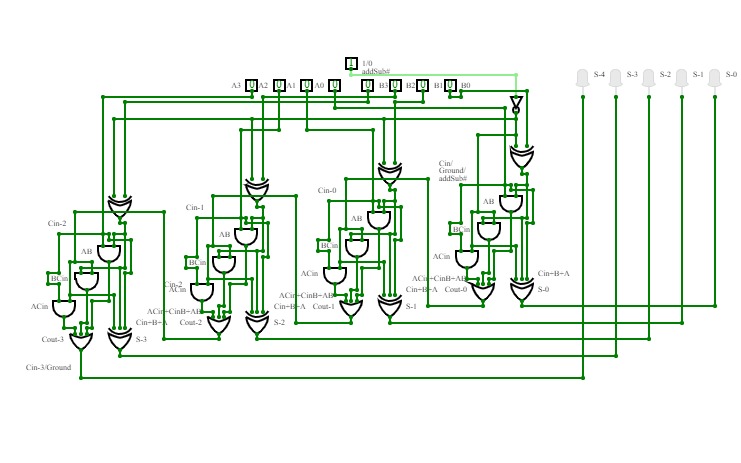
addSub#
addSub#An adder and subtractor circuit! Try it out!

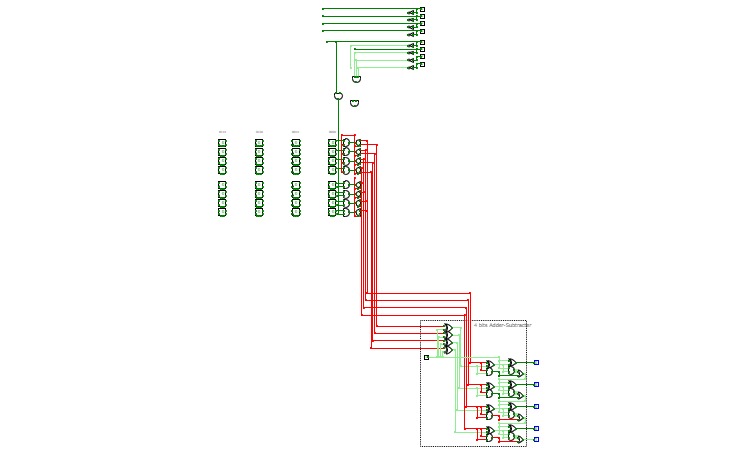
Halka TD4
Halka TD4Based on TD4, a 4 bit CPU.
Pre-design for Minecraft.

A 20bit processor
Done:
In progress:
-Alu
Yet to be done:
-Ram
-Ram address decode logic (Internal, External)
-Interrupts
-Registers
-Resets
-Instruction decode logic
-Transfer hub
-Other stuff
.
.
.
Instruction information:
.
Memory layout:
00000-9ffff: App rom
a0000-ff86e: GP ram
ff86f-ff999: Video ram
ffa00-ffeff: The stack
Notes:
Uses empty stack convention
Uses ascending stack convention
Parameters should be pushed onto the stack before calling the function
Status register goes as following (MSB first): OW, Z, N, E, IntterruptProgress (4bit), ResetProgress (4bit), InterruptAvailable, ResetAvailable, 0b000000
Every mention of "address" refers to the 6-nibble value with address configuration concatenated before the actual memory reference/data
ra1/ra2/ra3 refers to a register or address. The number is to distinguish between different arguments for instructions.
Registers:
Stack Pointer
Instruction
Address
SUM
Status
Instruction step
A
B
Register ids:
Stack Pointer: 0
Instruction: <INTERNAL>
Address: <INTERNAL>
SUM: 1
Status: 2
Instruction step: <INTERNAL>
A: 3
B: 4
fpA: 8
fpB: 9
fpC: a
fpD: b
fpS: c
-Address configuration is concatenated after reg id. Immeadiates and stack pointer indexes are not supported. e.g. 71 is data at B register, 32 is using SUM register as a xxxxx to use $?xxxxx on it.
-fpA through fpD &fpS are floating point registers. Bit functionality is as follows (MSB first): S, EXP (6bit), MAN (13 bit). To calculate the value: (1 + (1-(1/MAN))) * 2^(EXP - 63). -fpA-fpD & fps are incompatible with iadd/isub/idiv/imul/iinc/idec. fpadd/fpfpsub/fpmul/fpdiv/fpinc/fpdec work only on fp registers. They add the actual values, not bits.
-bor/band/bxor do operations on bits, not fpti values, still store binary result in S register.
Register addresses:
Memory page 0: fff00
Memory page 1: fff01
Memory page 2: fff02
Memory page 3: fff03
Address configuration:
-When using on registers, 0x8 as added onto the config
Immeadiate: $#xxxxx (0xxxxx) (Uses data xxxxx)
Address: $@xxxxx (1xxxxx) (Uses data at address xxxxx)
Pointer: $?xxxxx (2xxxxx) (Uses data at address xxxxx and uses $@***** on it)
Stack pointer index: $-xxxxx(%sp) (3xxxxx) (Subtracts xxxxx from stack pointer and uses $?***** on it)
.
.INSTRUCTIONS:
.
mov ra1, ra2:
Stores ra1 into ra2 address (000(ra1)(ra2))
fpti ra1, ra2:
Transfers data at ra1 to ra2 (not bits, value. kinda like "(int) float" in c) (ra1 is encoded in floating point. requires ra1 to be using a fpr or fp address) (001(ra1)(ra2))
itfp (r, fpR), ($Xxxxxx, fpR):
Transfers data at ra1 to ra2 (not bits, value. kinda like "(float) int" in c) (ra1 is encoded in floating point. requires ra2 to be using a fpr or fp address) (002(ra1)(ra2))
bor (ra1,ra2), (ra1, ra2, ra3):
Ors ra1 and ra2 registers, stores result in S register. Updates OW, Z, and N flags in status register (003(r1ID)(r2ID))
Ors ra1 and ra2 registers, stores result in ra3. Updates OW, Z, and N flags in status register (004(r1ID)(r2ID)(r3))
band (ra1, ra2), (ra1, ra2, ra3):
Ands ra1 and ra2, stores result in S register. Updates OW, Z, and N flags in status register (005(r1ID)(r2ID))
Ands ra1 and ra2, stores result in ra3 register. Updates OW, Z and N flags in status register (006(r1ID)$Xxxxxx)
bxor (,r1,r2), (,r1,$Xxxxxx), ($Xxxxxx,r2), ($Xxxxxx,$Yyyyyy):
Xors ra1 and ra2, stores result in S register. Updates OW, Z, and N flags in status register (007(r1ID)(r2ID))
Xors ra1 and ra2, stores result in ra3 register. Updates OW, Z and N flags in status register (008(r1ID)$Xxxxxx)
iadd (,r1,r2), (,r1,$Xxxxxx), ($Xxxxxx,r2), ($Xxxxxx,$Yyyyyy):
Adds r1 and r2 registers, stores result in S register. Updates OW, Z, and N flags in status register (013(r1ID)(r2ID))
Adds r1 register and $xxxxx address, stores result in S register. Updates OW, Z and N flags in status register (014(r1ID)$Xxxxxx)
Adds $xxxxx address and r2 register, stores result in S register. Updates OW, Z and N flags in status register (015$Xxxxxx(r2ID))
Adds $xxxxx and $yyyyy addresses, stores result in S register. Updates OW, Z and N flags in status register (016$XxxxxxYyyyyy)
isub (,r1,r2), (,r1,$Xxxxxx), ($Xxxxxx,r2), ($Xxxxxx,$Yyyyyy):
Subtracts r2 from r1, stores result in S register. Updates OW, Z and N flags in status register (017(r1ID)(r2ID))
Subtracts $xxxxx from r1, stores result in S register. Updates OW, Z and N flags in status register (018(r1ID)$Xxxxxx)
Subtracts r2 from $xxxxx, stores result in S register. Updates OW, Z and N flags in status register (019$Xxxxxx(r2ID))
Subtracts $yyyyy from $xxxxx, stores result in S register. Updates OW, Z and N flags in status register (01a$XxxxxxYyyyyy)
imul (,r1,r2), (,r1,$Xxxxxx), ($Xxxxxx,r2), ($Xxxxxx,$Yyyyyy):
Multiplyes r1 and r2 registers, stores result in S register. Updates OW, Z and N flags in status register (01b(r1ID)(r2ID))
Multiplyes r1 register and $xxxxx address, stores result in S register. Updates OW, Z and N flags in status register (01c(r1ID)$Xxxxxx)
Multiplyes $xxxxx address and r2 register, stores result in S register. Updates OW, Z and N flags in status register (01d$Xxxxxx(r2ID))
Multiplyes $xxxxx and $yyyyy addresses, stores result in S register. Updates OW, Z and N flags in status register (01e$XxxxxxYyyyyy)
idiv (,r1,r2), (,r1,$Xxxxxx), ($Xxxxxx,r2), ($Xxxxxx,$Yyyyyy):
Divides r1 by r2, stores result in S register. Updates E, Z and N flags in status register (01f(r1ID)(r2ID))
Divides r1 by $xxxxx, stores result in S register. Updates E, Z and N flags in status register (020(r1ID)$Xxxxxx)
Divides $xxxxx by r2, stores result in S register. Updates E, Z and N flags in status register (021$Xxxxxx(r2ID))
Divides $xxxxx by $yyyyy, stores result in S register. Updates E, Z and N flags in status register (022$XxxxxxYyyyyy)
iinc $Xxxxxx, r:
Increments address xxxxx (023$Xxxxxx)
Increments register r (024(rID))
idec $Xxxxxx, r:
Decrements address XXXXX (025Xxxxxx)
Decrements register r (026(rID))
fpadd r1,r2:
Adds r1 and r2 registers, stores result in fpS register. Updates OW, Z, and N flags in status register (027(r1ID)(r2ID))
fpsub r1,r2:
Subtracts r2 from r1, stores result in fpS register. Updates OW, Z and N flags in status register (028(r1ID)(r2ID))
fpmul r1,r2:
Multiplyes r1 and r2 registers, stores result in fpS register. Updates OW, Z and N flags in status register (029(r1ID)(r2ID))
fpdiv r1,r2:
Divides r1 by r2, stores result in fpS register. Updates E, Z and N flags in status register (02a(r1ID)(r2ID))
fpinc r:
Increments register r (02b(rID))
fpdec r:
Decrements register r (02c(rID))
phb $Xxxxxx, r:
Increments stack register and sets $-00000(%sp) to $xxxxx (02d)
Increments stack register and sets $-00000(%sp) to r register (02e)
plb $Xxxxxx, r:
Decrements stack register and sets $xxxxx register to $-00000(%sp) (02f)
Decrements stack register and sets r register to $-00000(%sp) (030)
jmp $Xxxxxx, r:
Jumps to $xxxxx address(031Xxxxxx)
Jumps to r register (032(rID))
jow $Xxxxxx, r:
Jumps to $xxxxx address if OW bit is set (033Xxxxxx)
Jumps to r register if OW bit is set (034(rID))
jnow $Xxxxxx, r:
Jumps to $xxxxx address if OW bit is clear (035Xxxxxx)
Jumps to r register if OW is clear (036(rID))
jz $Xxxxxx, r:
Jumps to $xxxxx address if Z bit is set (037Xxxxxx)
Jumps to r register if Z bit is set (038(rID))
jnz $Xxxxxx, r:
Jumps to $xxxxx address if Z bit is clear (039Xxxxxx)
Jumps to r register if Z bit is clear(03a(rID))
jn $Xxxxxx, r:
Jumps to $xxxxx address if N bit is set (03bXxxxxx)
Jumps to r register if N bit is set (03c(rID))
jnn $Xxxxxx, r:
Jumps to $xxxxx address if N bit is clear (03dXxxxxx)
Jumps to r register if N bit is clear(03e(rID))
je $Xxxxxx, r:
Jumps to $xxxxx address if E bit is set (03fXxxxxx)
Jumps to r register if E bit is set(040(rID))
jne $Xxxxxx, r:
Jumps to $xxxxx address if E bit is clear (041Xxxxxx)
Jumps to r register if E bit is clear(042(rID))
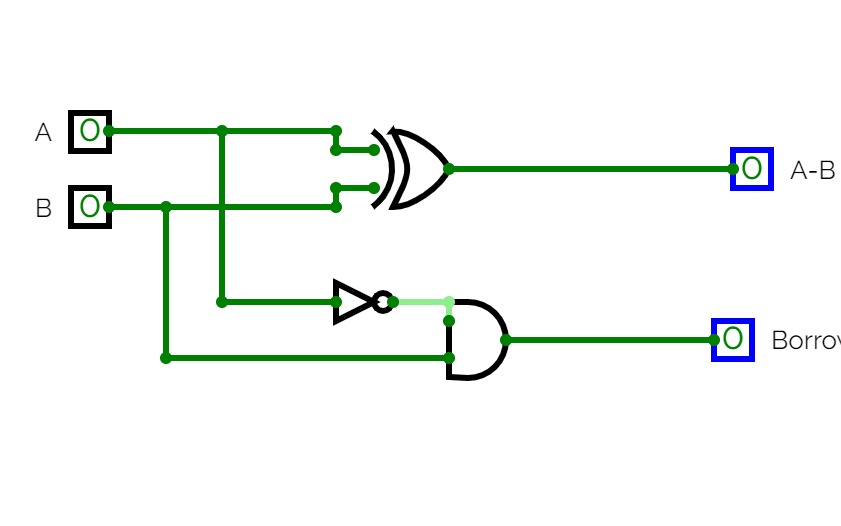
4 operations
4 operations
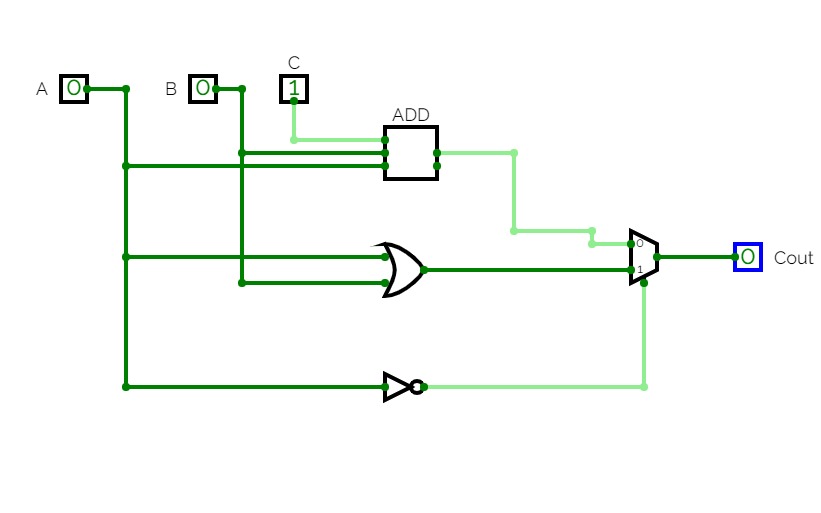
adder and subtractors
adder and subtractors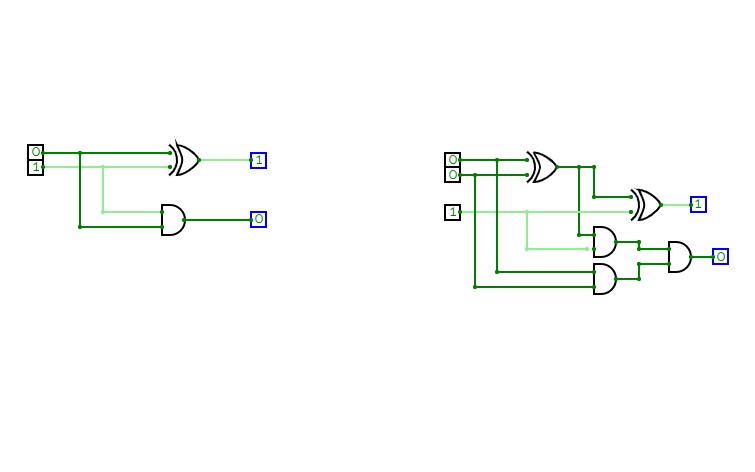
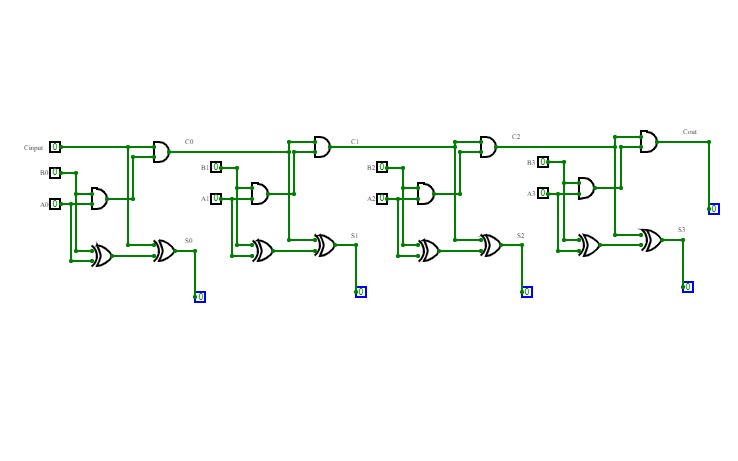
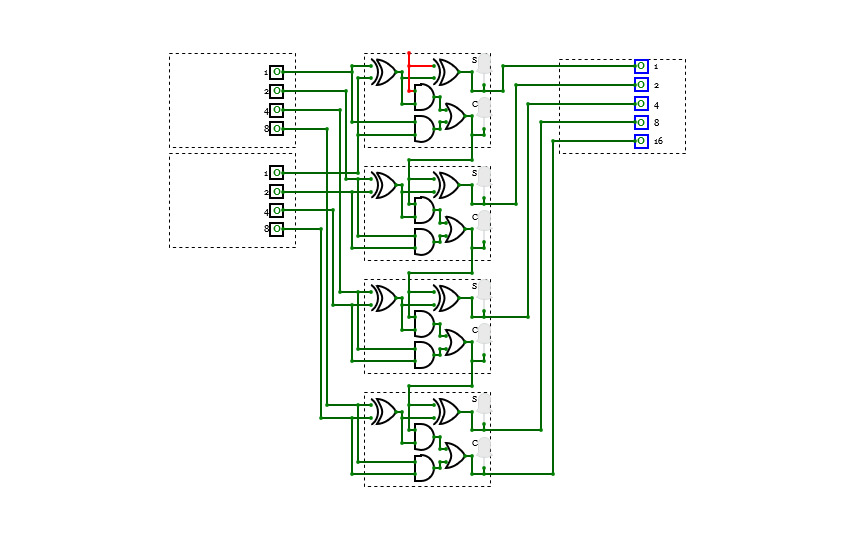
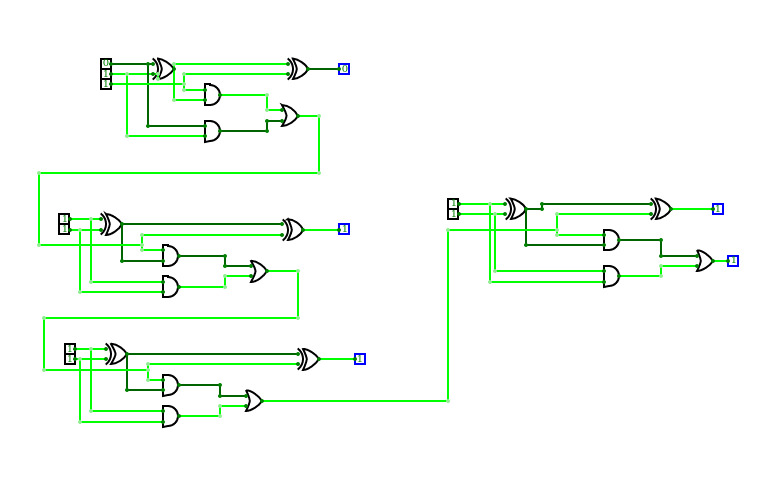
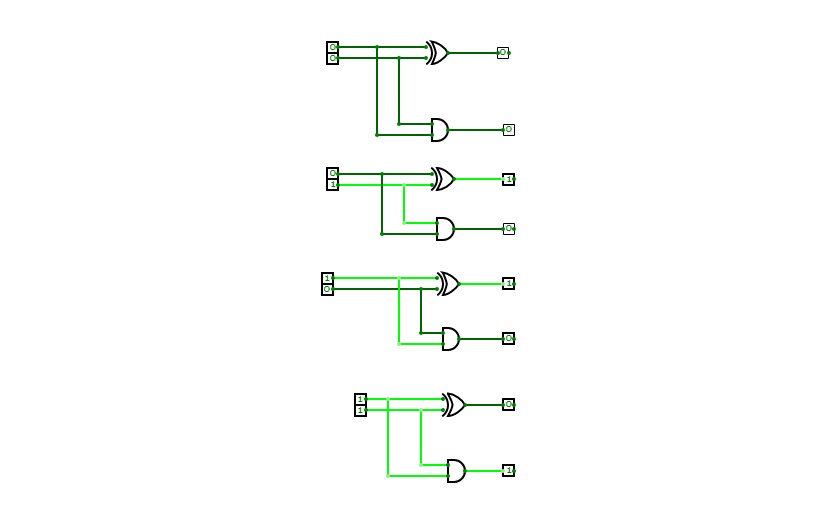
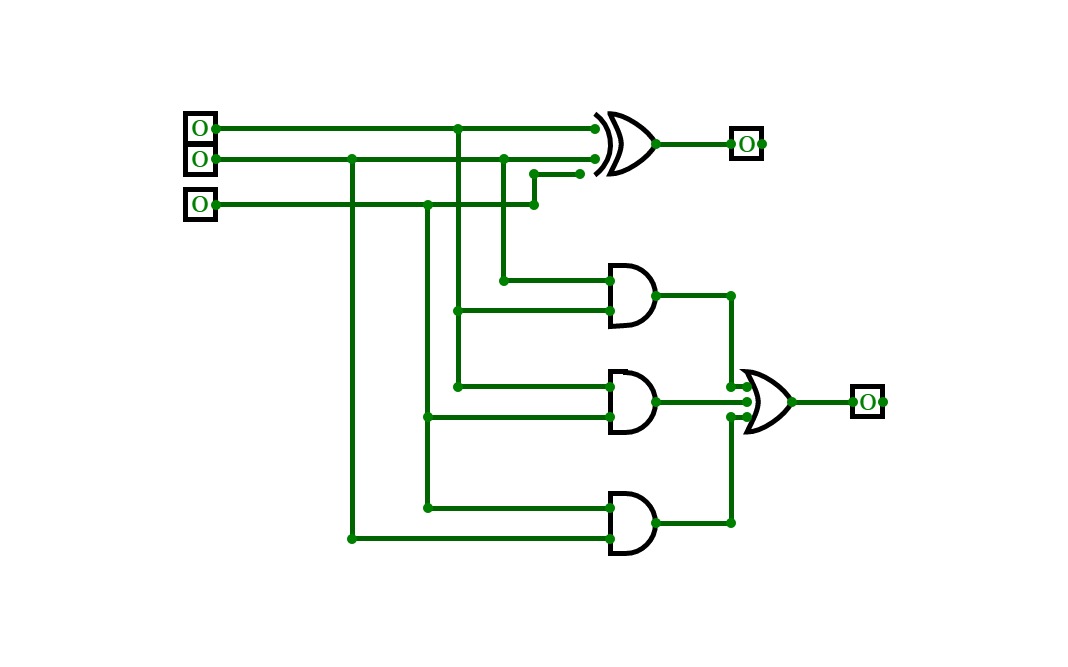
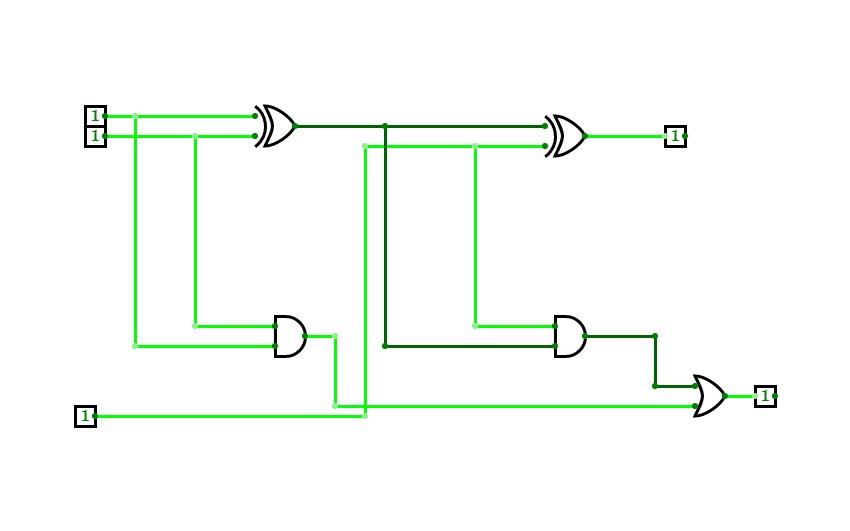
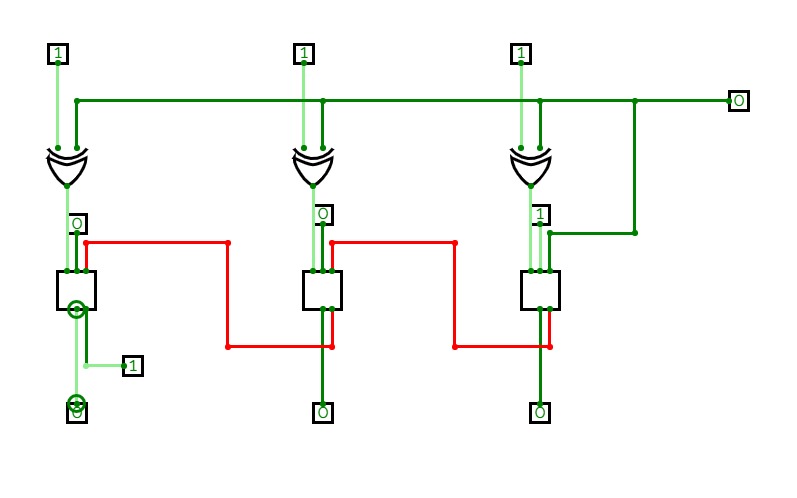
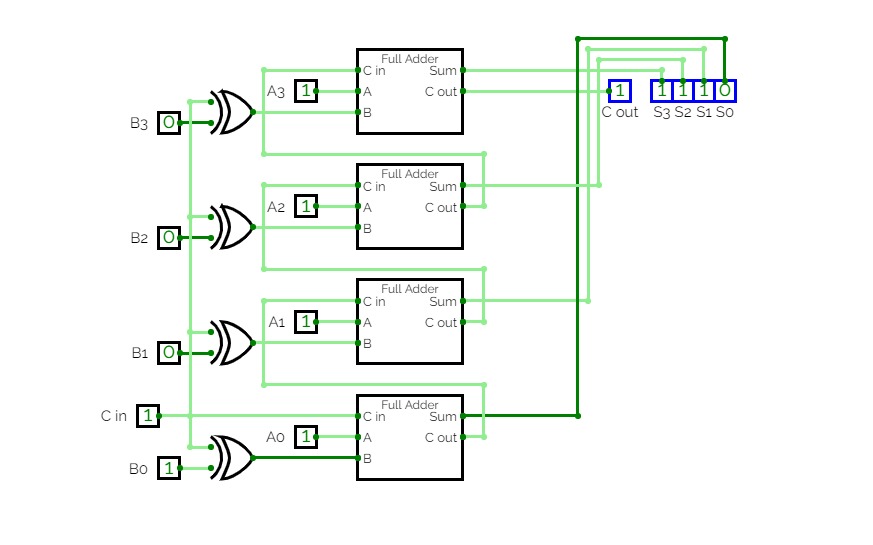
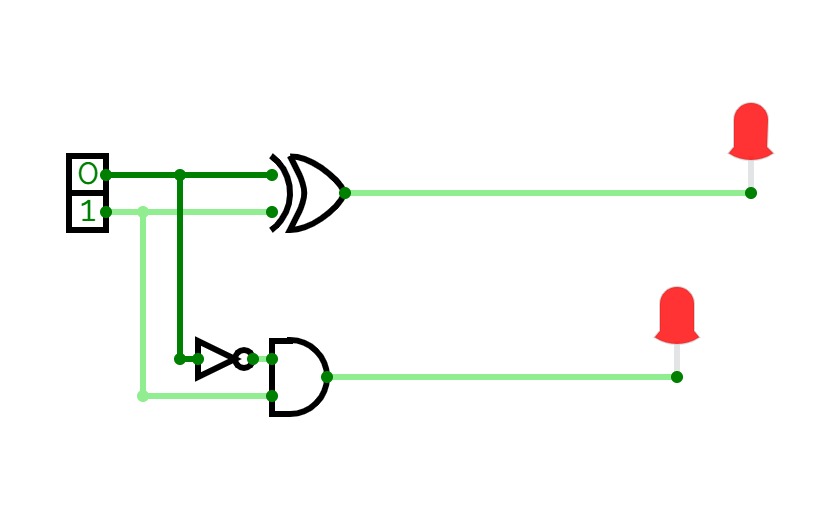
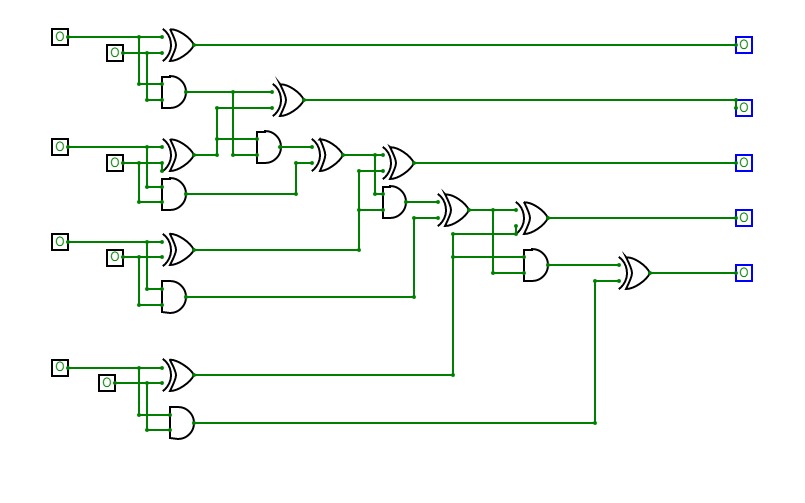
4-bit full adder
4-bit full adderI'm a beginner, and this is my first circuit. it is 4-bit full adder, which is used to add 3 4-bit input and producing 4-bit or 5-bit output. it is implemented by using XOR gate, AND gate, and OR gate.
A multiplication circuit designed to multiply two 8-bit numbers, creating a 16-bit output. The values are unsigned, and input into two locations in a currently unconventional way. The output is stored in the flip-flop array to the right. The button at the top starts or resets the program.

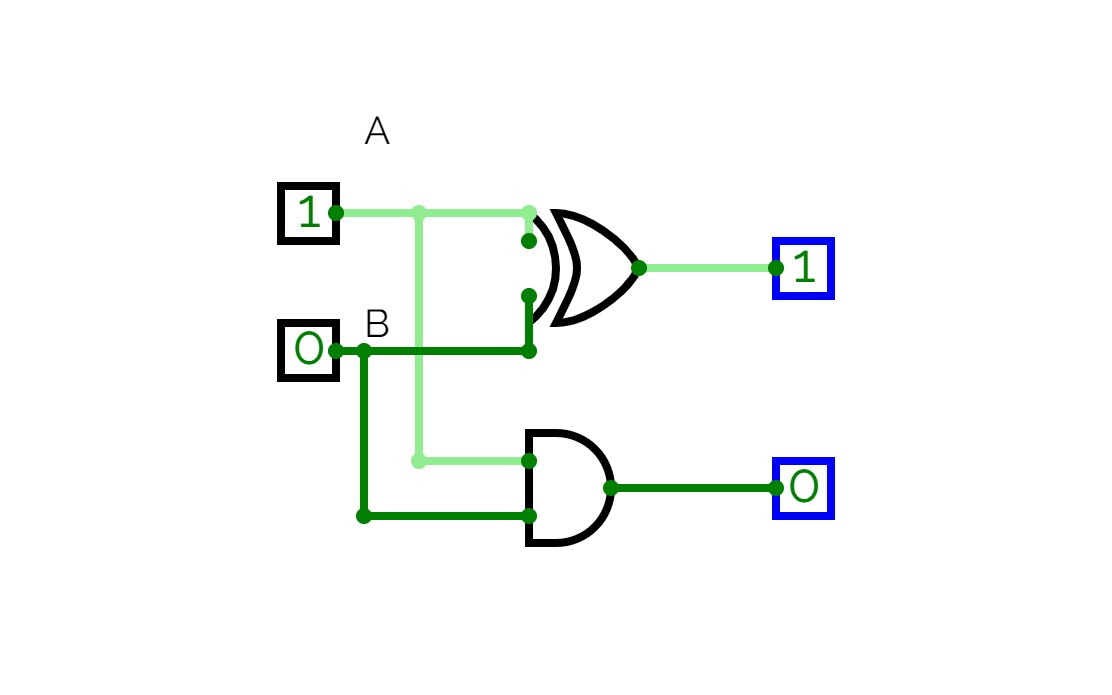
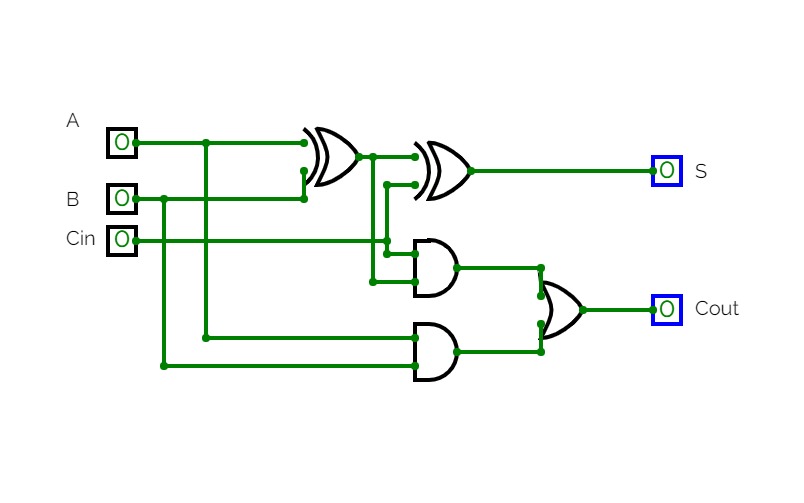
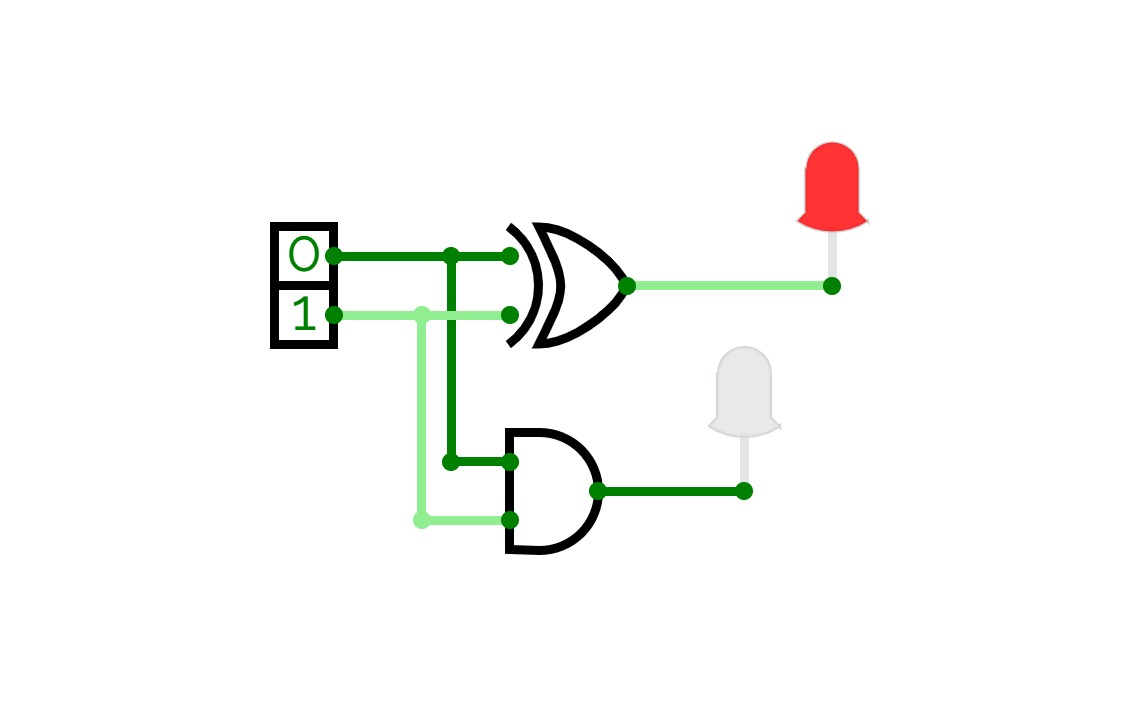

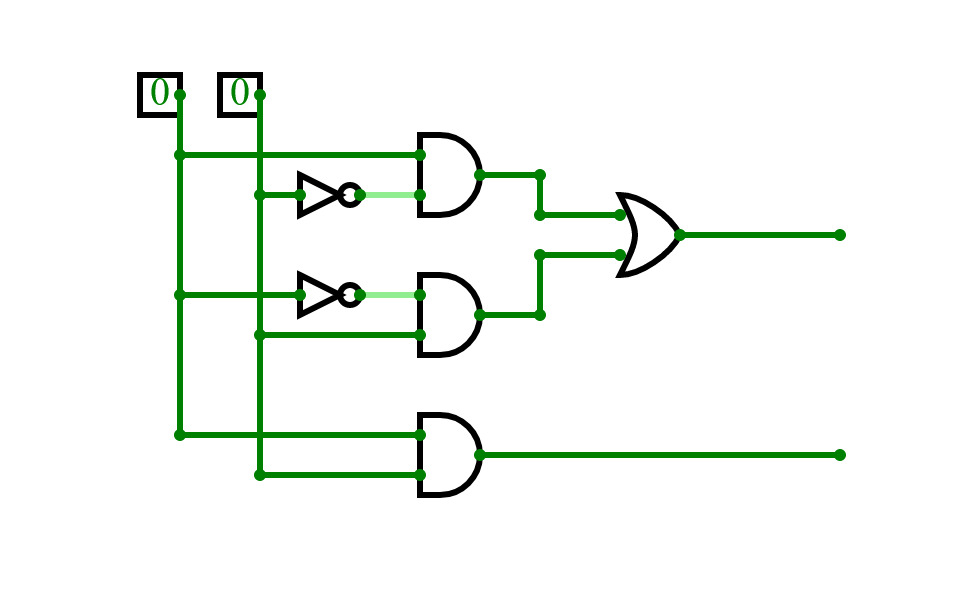
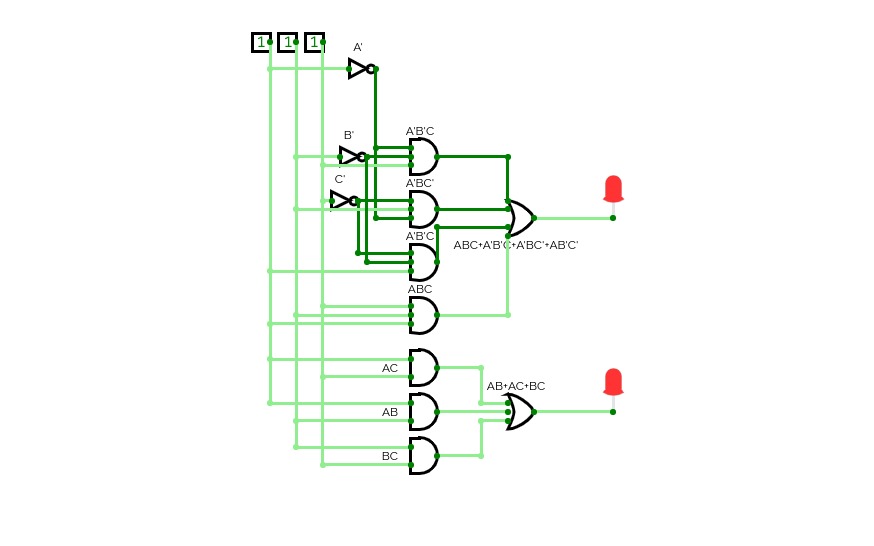
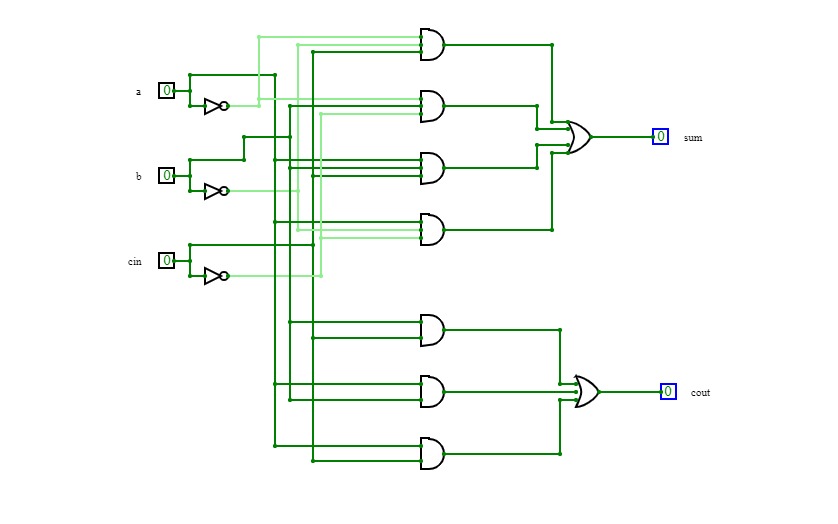
Full Adder
Full Adder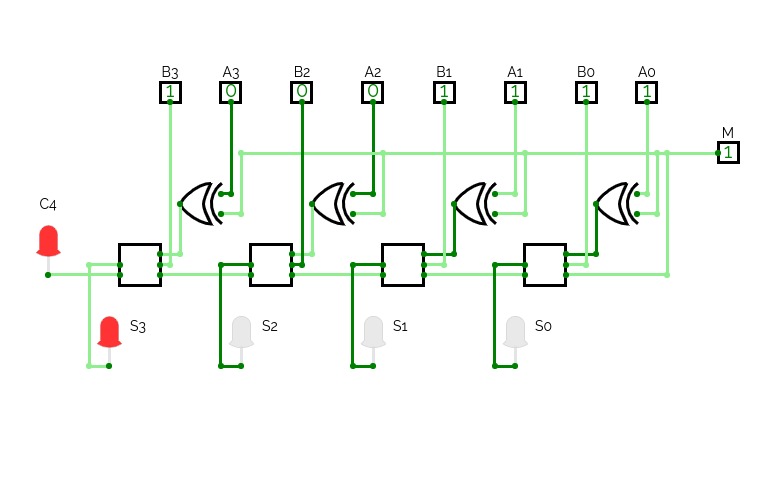
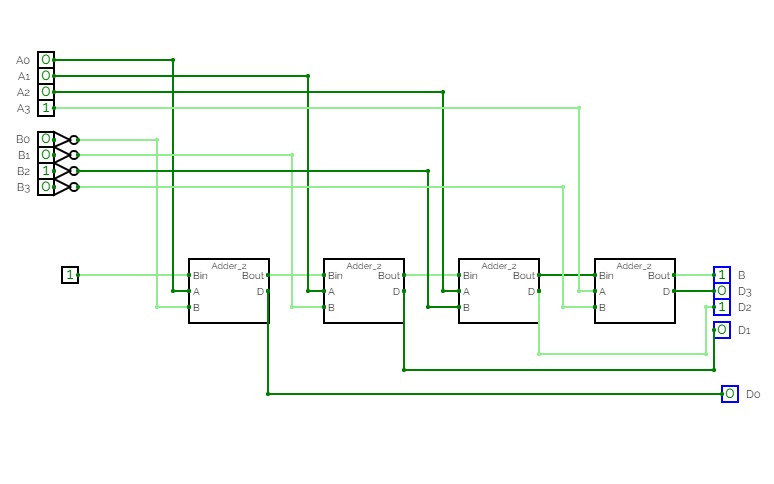
4 Bit Adder
4 Bit Adder

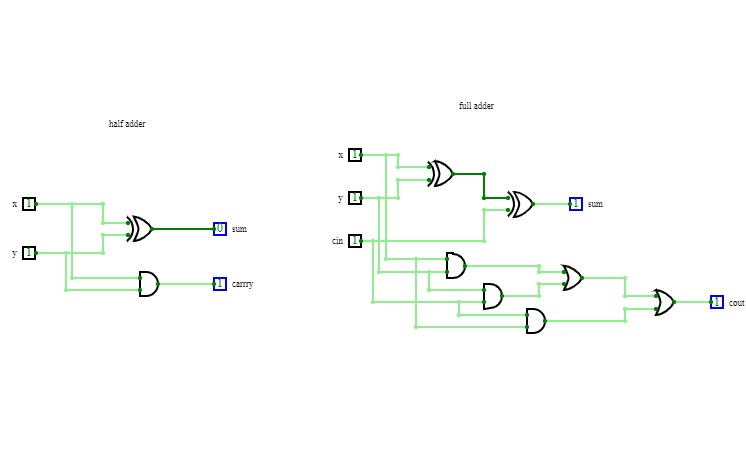
half adder and full adder
half adder and full adder.
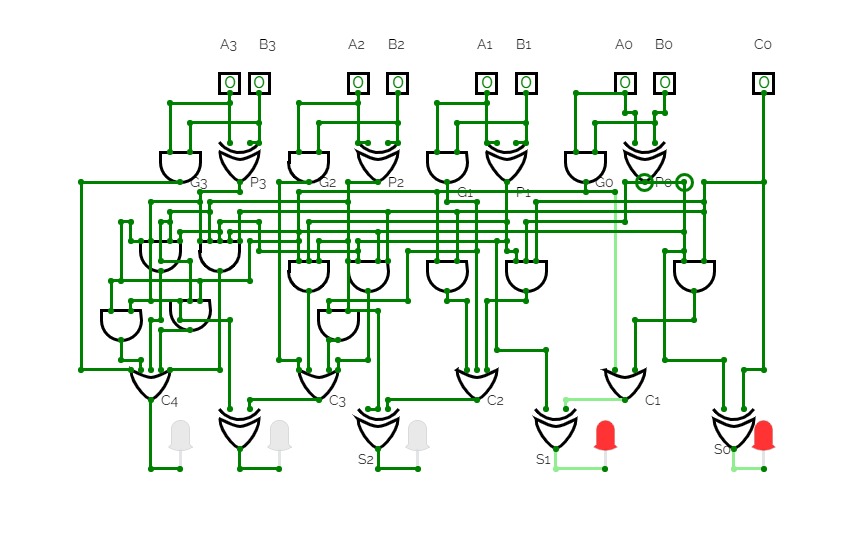

Carry-look-ahead carry generator
Carry-look-ahead carry generator
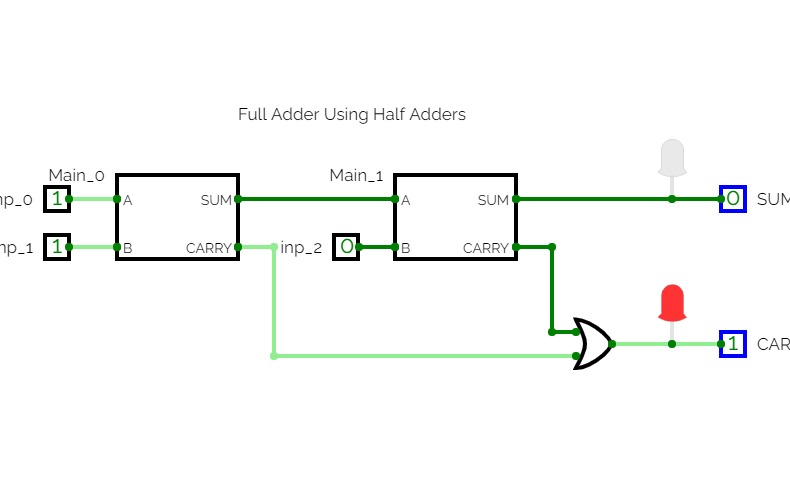
Full-Adder using Half-Adder
Full-Adder using Half-Adder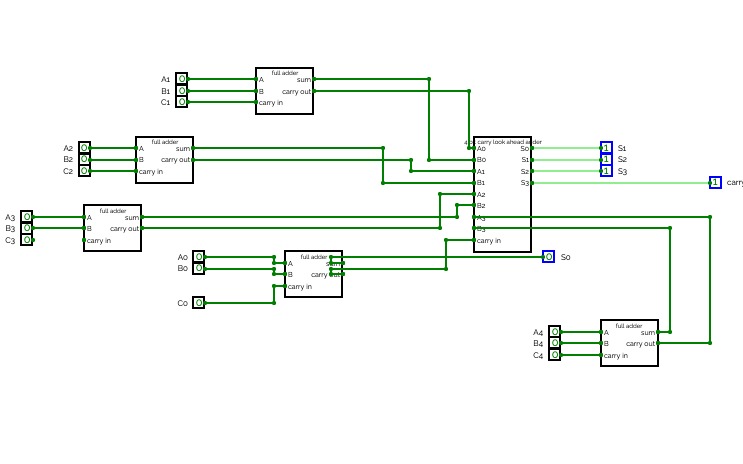
wallace tree adder
wallace tree adderwallace tree adder is used to add 3 or more numbers at once. thus improving efficiency.
full adder
full adder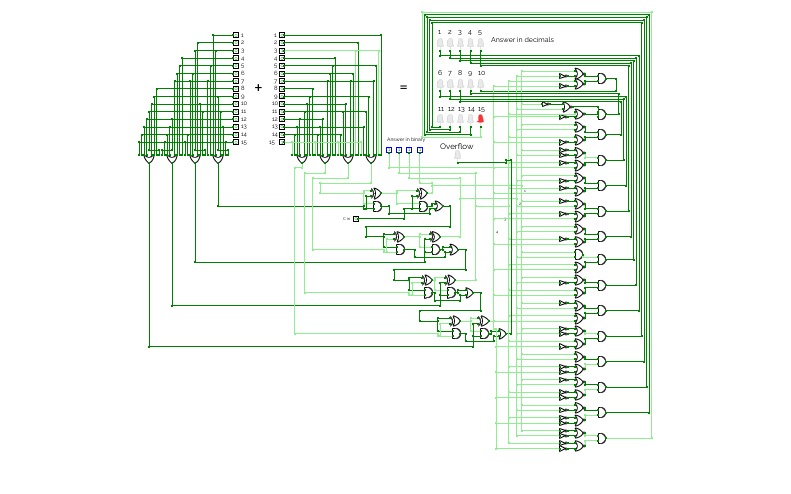
4 bit adder
4 bit adderMy first project on this site!
this 4 bit adder is fully decimal, that means the number you input is decimal and the answer will also be in decimal.
The circuit consists of a decimal-to-binary converter, an 4 bit adder and a binary-to-decimal converter.
The circuit is made without sub-circuits.
To use the adder, click any number you want on the left and right side of the plus. The answer will appear on the right side, in decimal and binary.
full adder and subtractor
full adder and subtractorI am currently in the process of creating a binary to hexadecimal convertor to show the additions in a decimal form in 2 digits.
help is appreciated just drop me a message and i will add you to the collaborator.
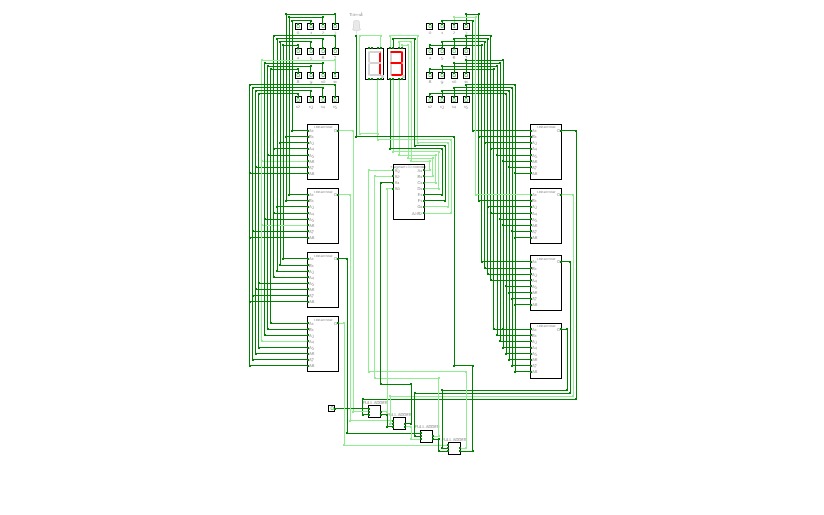
8 digit adder
8 digit adder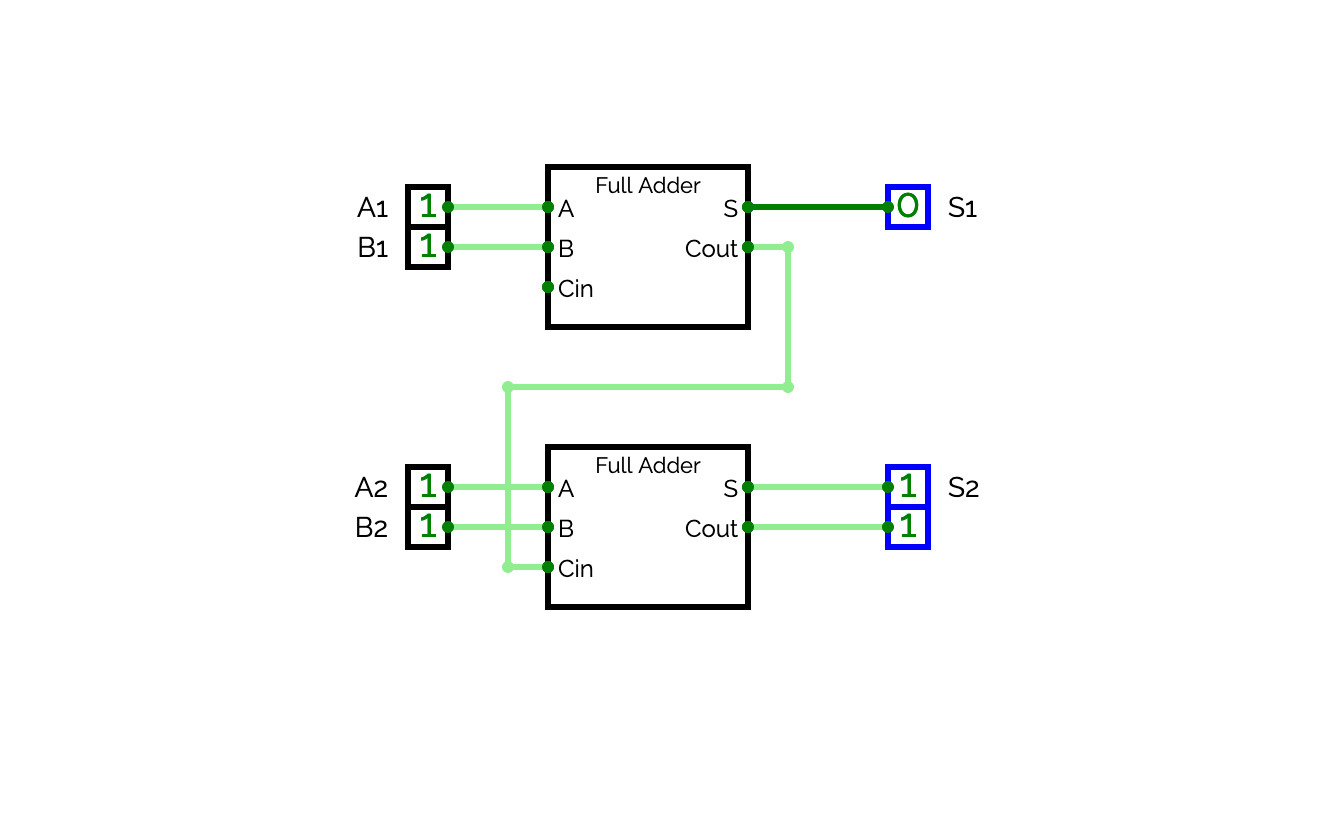

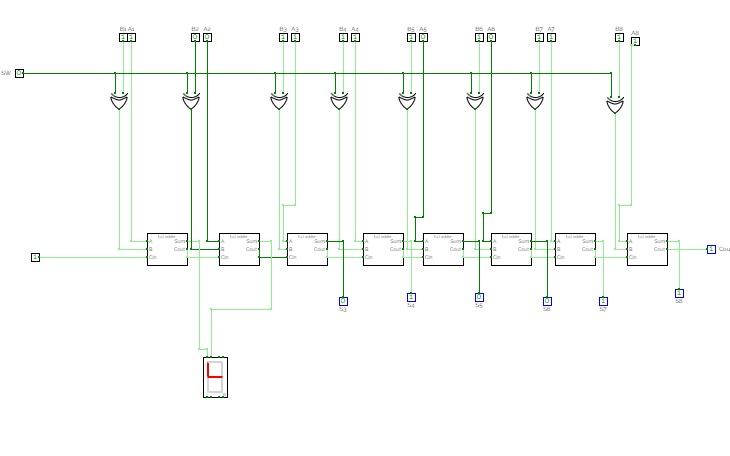
4-bit Adder
4-bit AdderThe 4-bit adder which can do math on 4-bit integers and display on 2 7-segment LEDs.
This project is owned by Lu Xuan Minh - student of HCMUT.
Everyone can fork my project for the purpose of studying and researching.
Thank you for your viewing!
Lu Xuan Minh
Email: [email protected]
Half adder
Half adder4-bit Adder with 7 segment displays
4-bit Adder with 7 segment displays4-bit Adder with 7 segment displays
Combinational Logic
Combinational Logic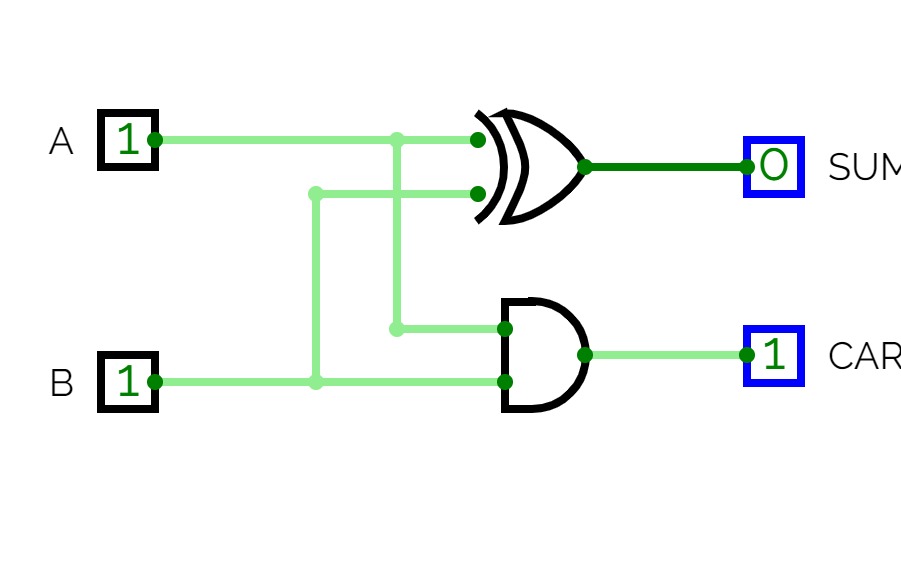
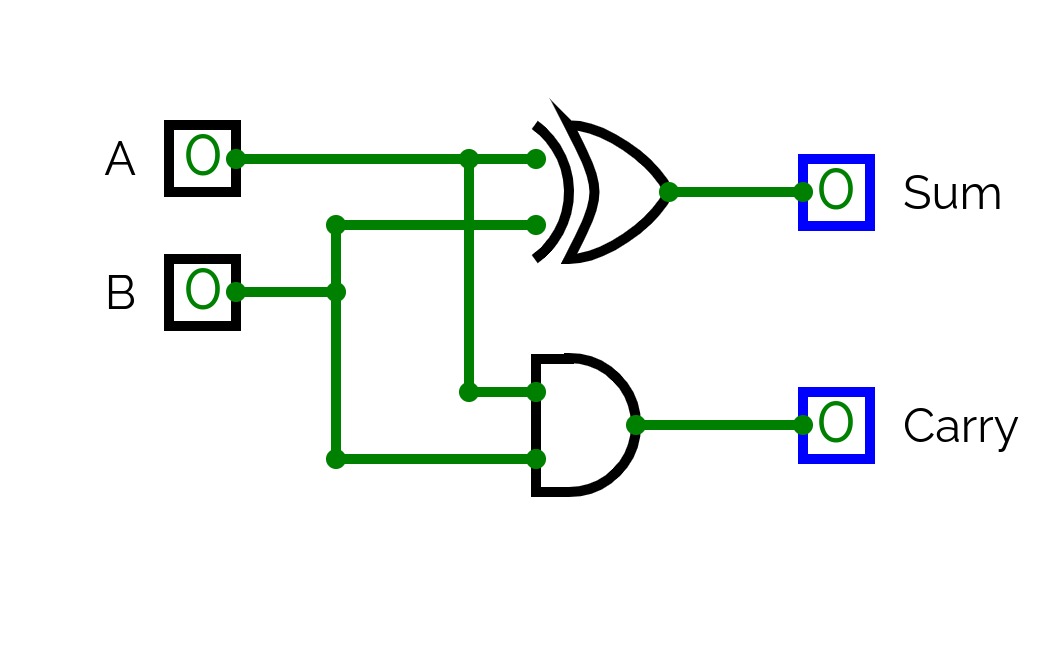
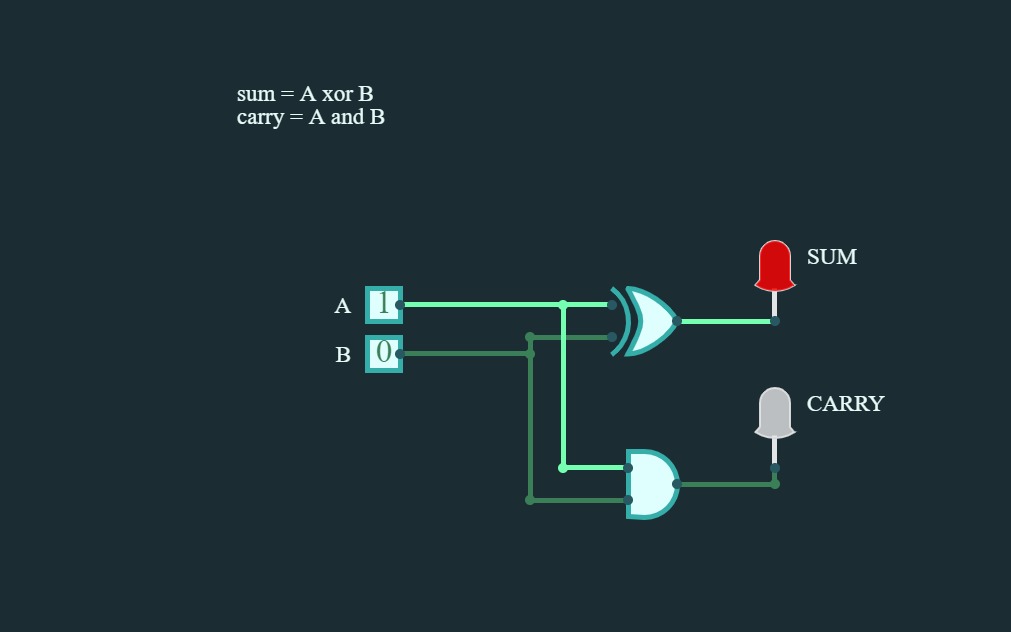
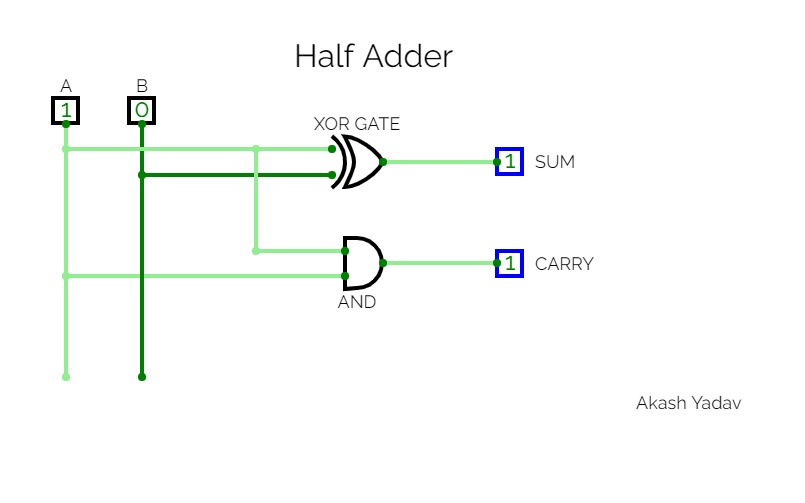
Half Adder
Half AdderHalf adder is a combinational logic circuit with two inputs and two outputs. The half adder circuit is designed to add two single bit binary number A and B. It is the basic building block for the addition of two single-bit numbers. This circuit has two outputs carry and sum.
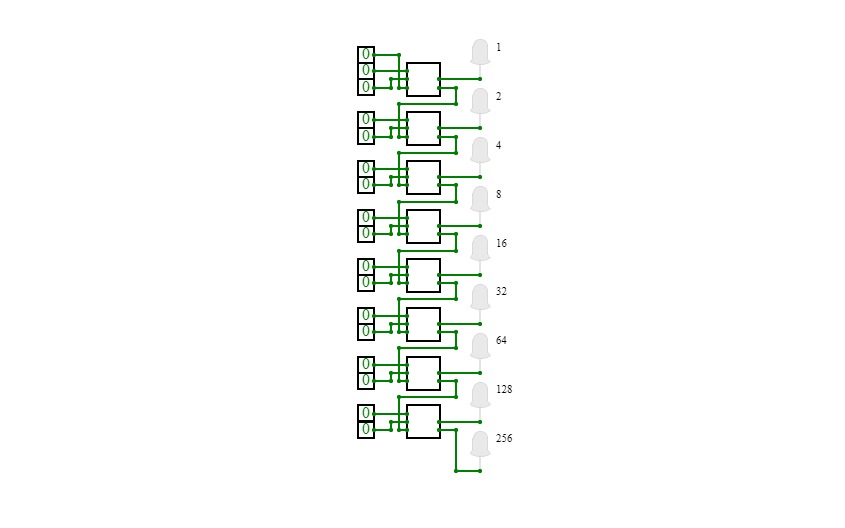
B8256 V2
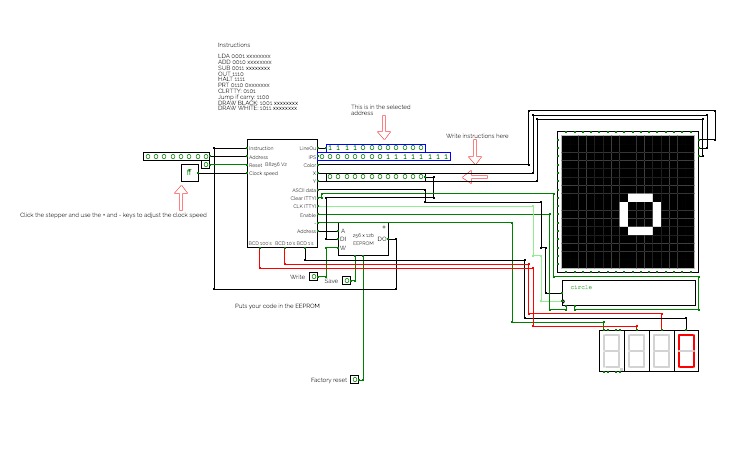
B8256 V2RECOMMENDED FOR COMPUTERS
This is the second addition of the B8 Series. Otherwise known as the BURTONABLE 8 256 it is capable of running programs 256 lines long! as well as 7 instructions to use
LDA 0001: Loads the given value into the Accumulator
ADD 0010: The given value will be added to the accumulator
SUB 0011: The given value will be subtracted from the accumulator
OUT 1110: Shows the output of A and B
HALT 1111: Stops all
PRT 0110: Prints a 7 bit ASCII character to the TTY
CLRTTY 0101: Clears the TTY element
DRAW BLACK 1001: Draws the color black to the X (4 bits) and the Y (4 bits)
DRAW WHITE 1011: Draws the color white to the X (4 bits) and the Y (4 bits)
JC 1100: Only jumps up by the given data if 2 negative numbers add up to a positive number
sometimes the codes get corrupted just spam reset a couple times
FUN CODES: To use them, just double click the EEPROM
To retrieve a code just press the save button and then open the dev console (FN + Volume up MAC) or F12 (PC)
To put codes in the EEPROM double click it and paste the code
circle.
2952,2968,2984,2999,2998,2997,2980,2964,2948,2933,2934,2935,1635,1641,1650,1635,1644,1637,3840,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
I would love to see your codes too so post them in the comments!
THIS VERSION IS OUTDATED HERE IS THE LINK TO THE NEW ONE https://circuitverse.org/users/160624/projects/b8256-v3
Oh and also The original B8 got deleted :(

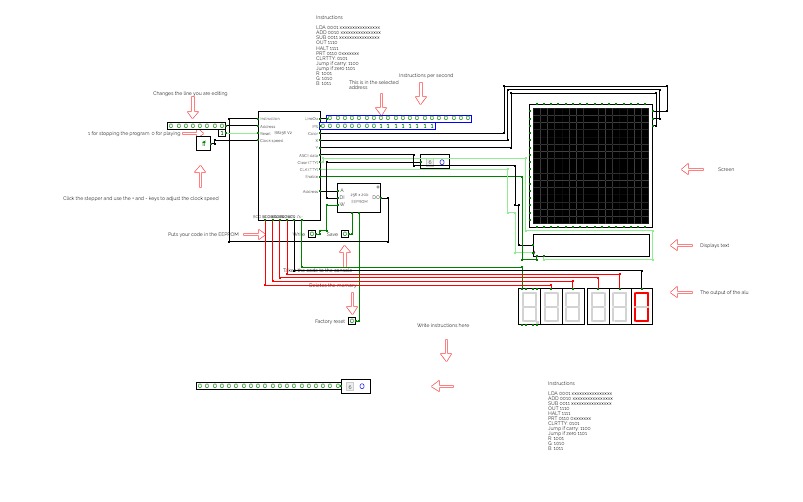
Burtonable Fortitudo
Burtonable FortitudoUSE ON A COMPUTER
Same as V2 exempt that there is a Jump if zero command
JO: Jumps if the ALU output is 0
And you can under stand things better!
(these instructions arent done)
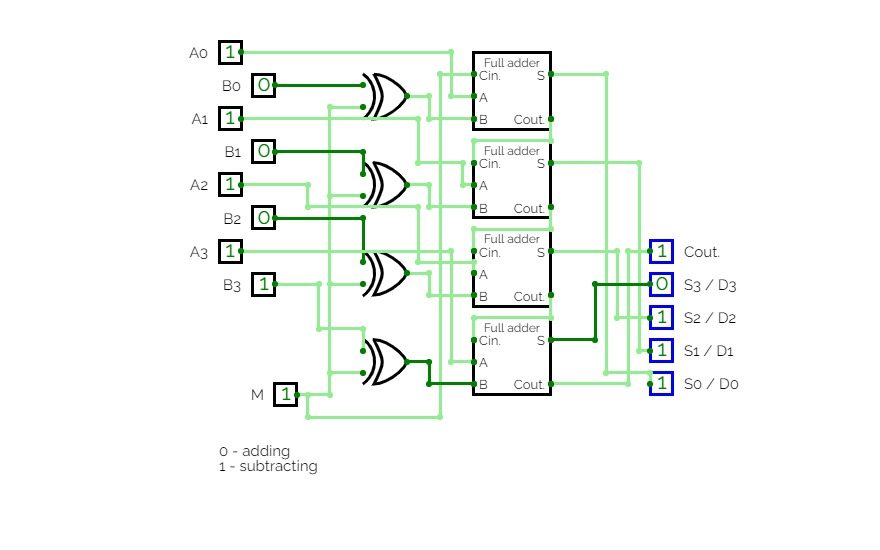
4 bit adder subtractor
4 bit adder subtractorThis is a 4 bit adder.
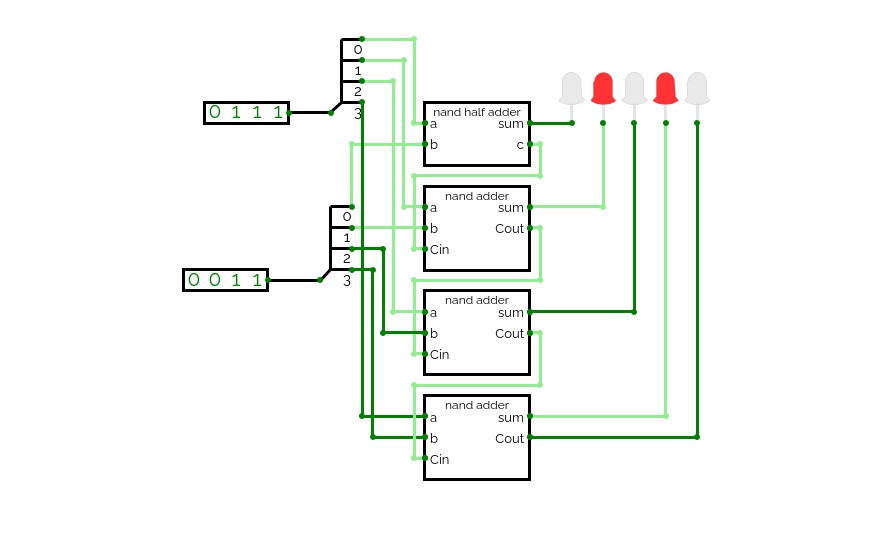
nand adder
nand adder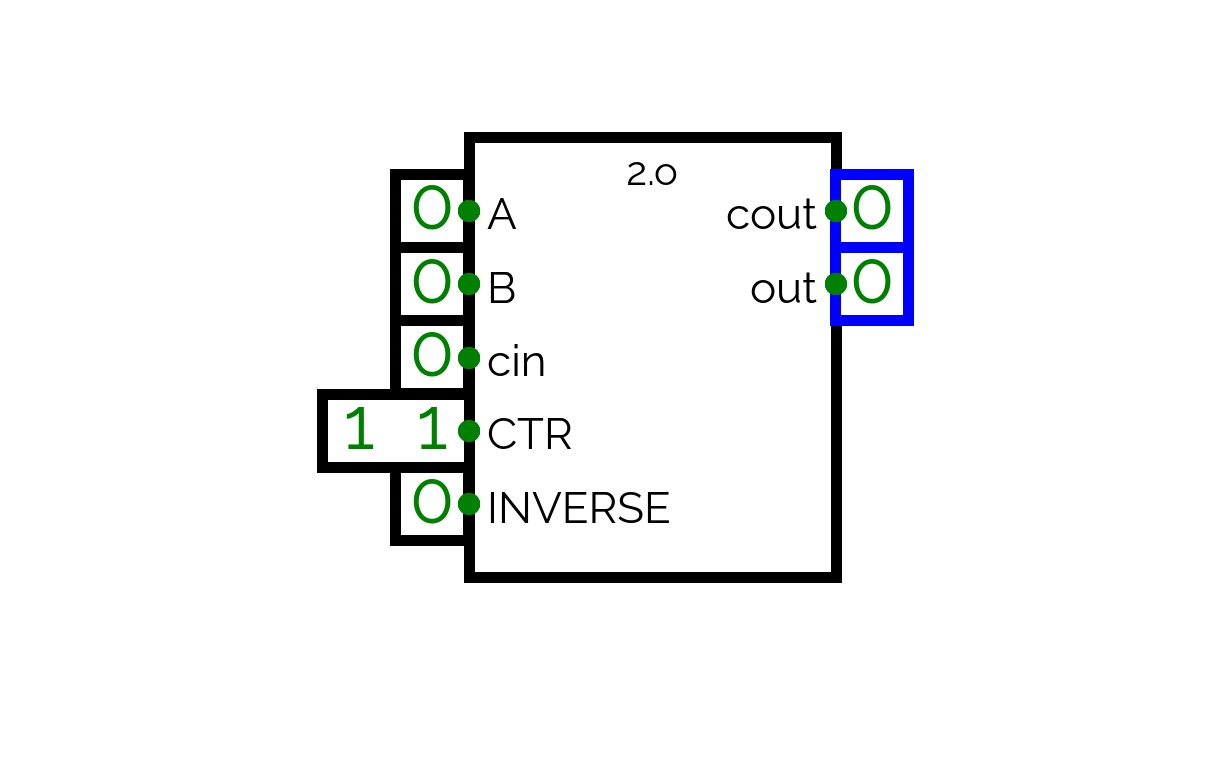
Simple 1 bit ALU with 4 operations
Simple 1 bit ALU with 4 operations
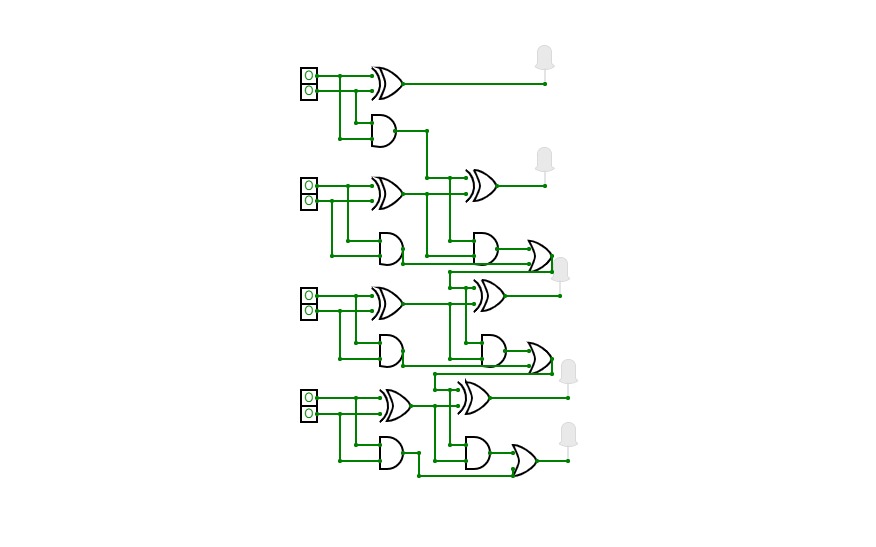
4 bit binary adder
4 bit binary adderHey, i built a 4 bit Adder circuit which can add a pair of 4 bit binary numbers. it consist of 7 XOR gates, 7 AND gates, and 3 OR gates
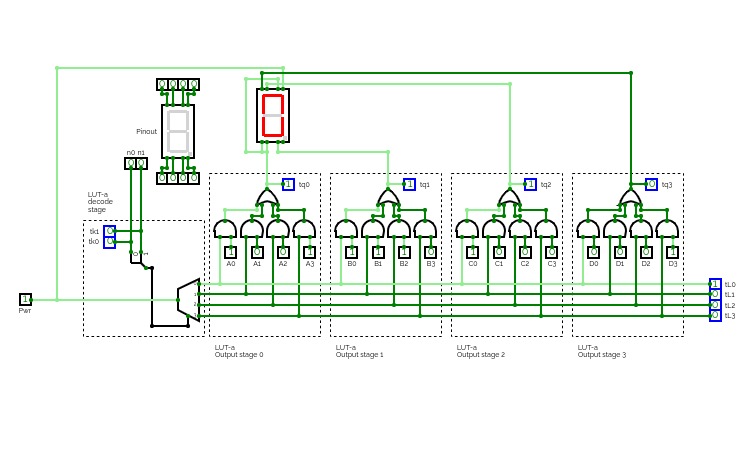
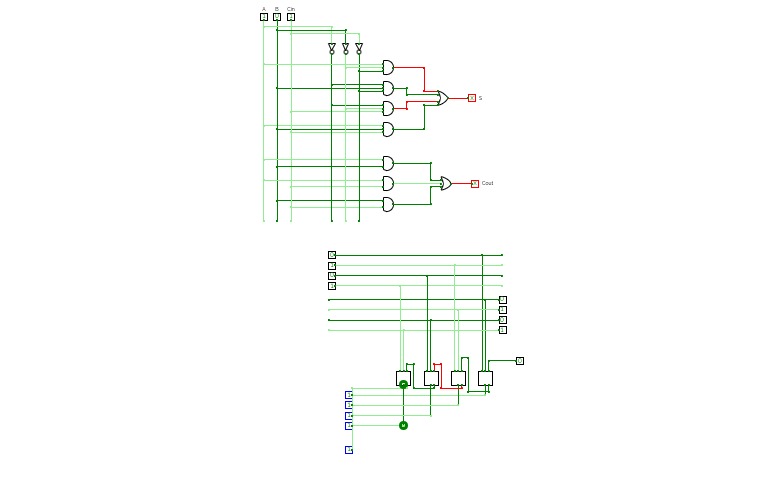
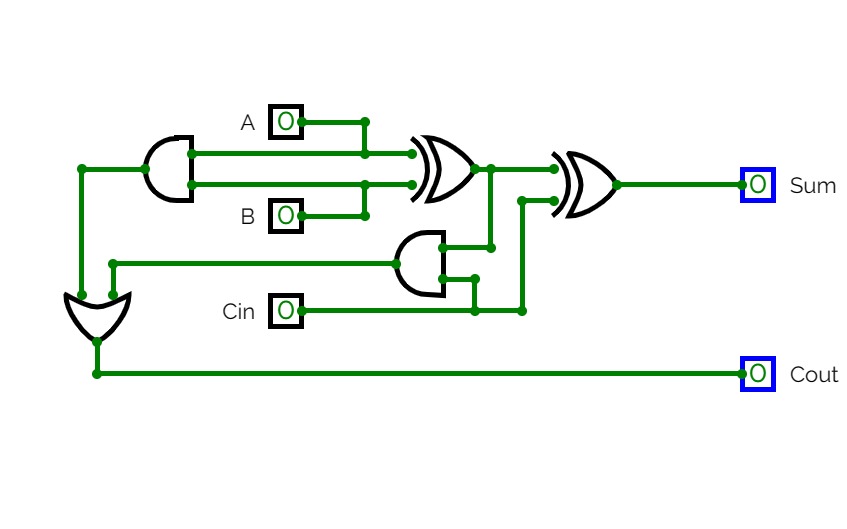

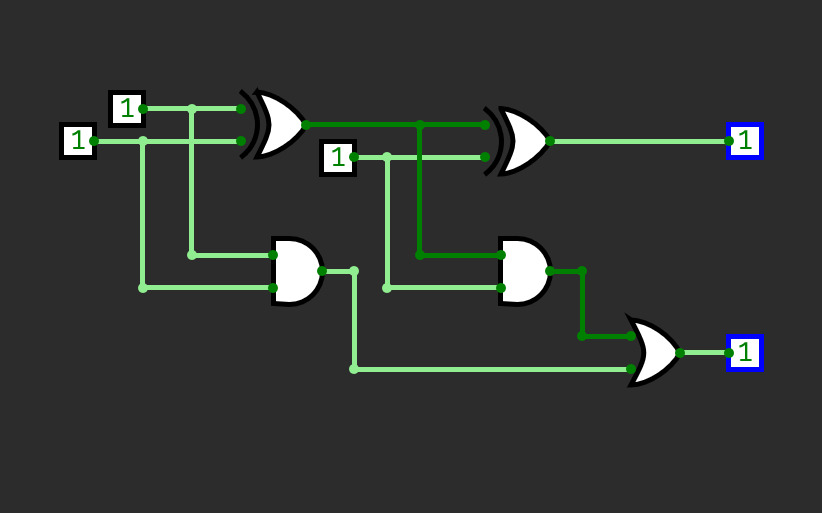
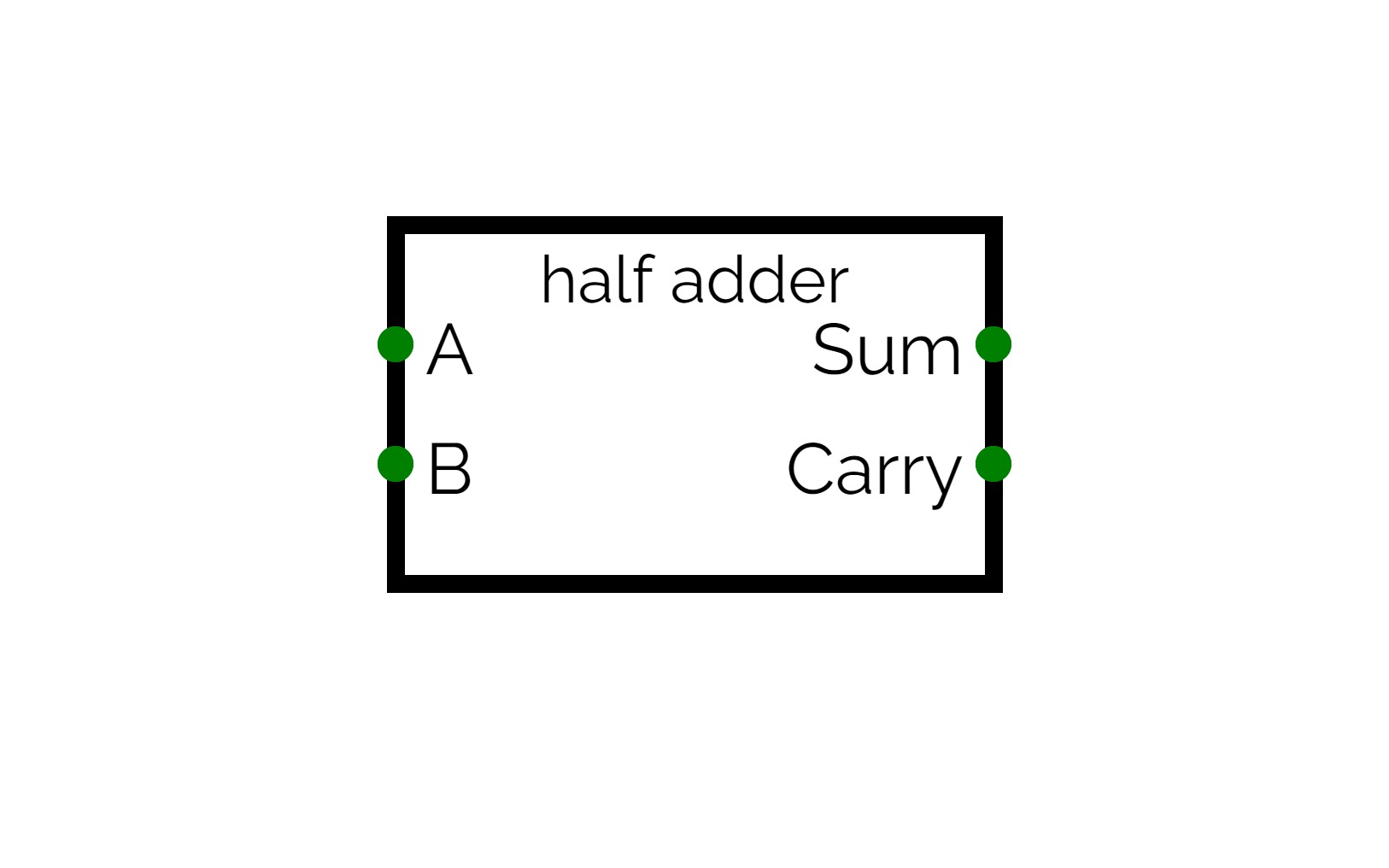
half adder
half adder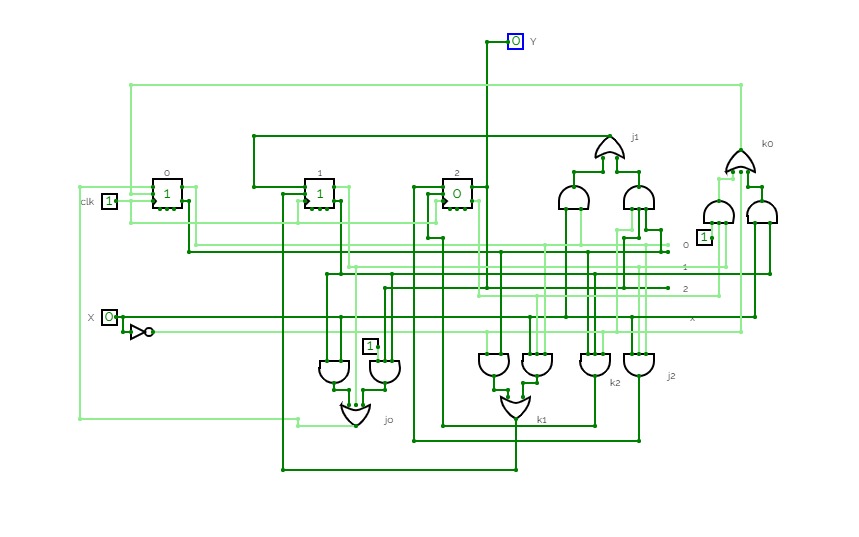
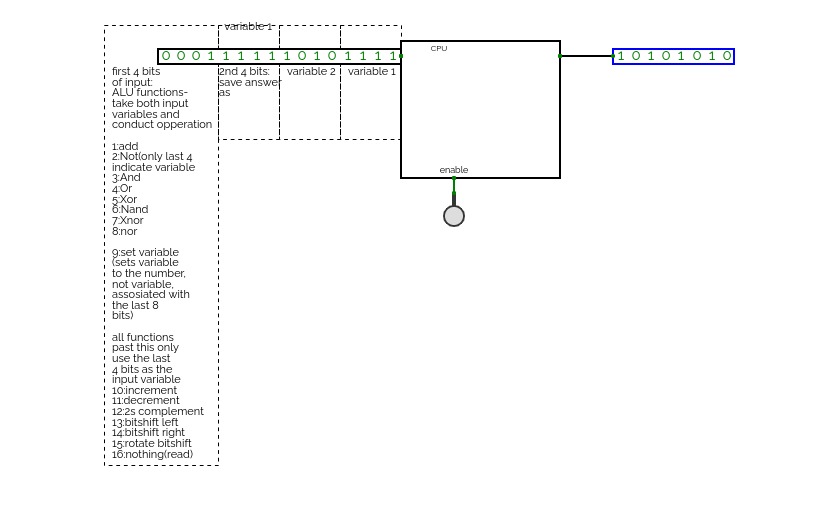
A CPU! this took me a while to figure out, mostly how to get it to run comands, but I eventually found a solution of using 4 bits as function indicators, 4 as where to save the output, 4 as the 2nd input, and 4 as the first input!

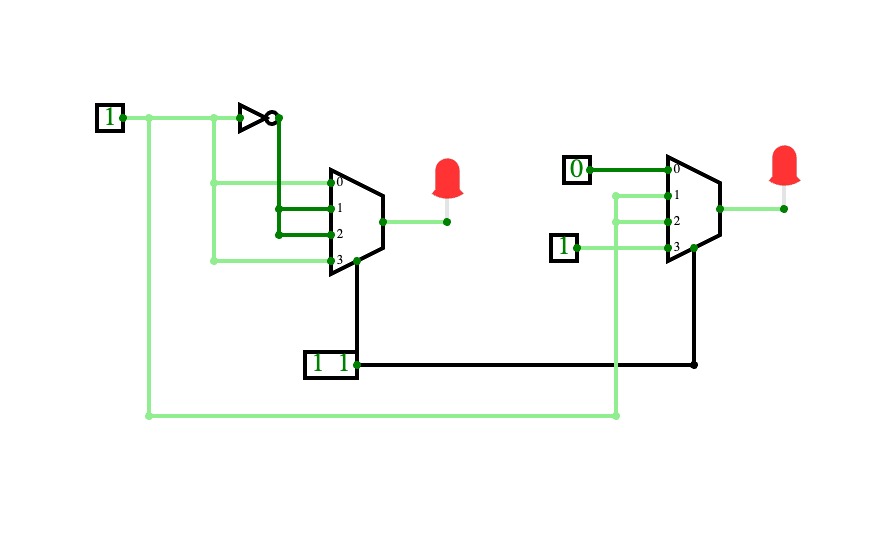
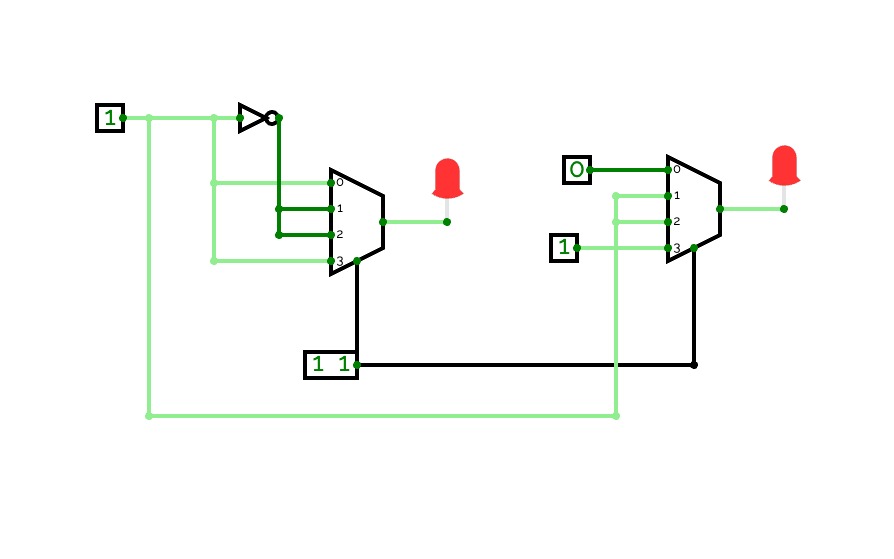
DE Project 4:1 MUX adder
DE Project 4:1 MUX adder

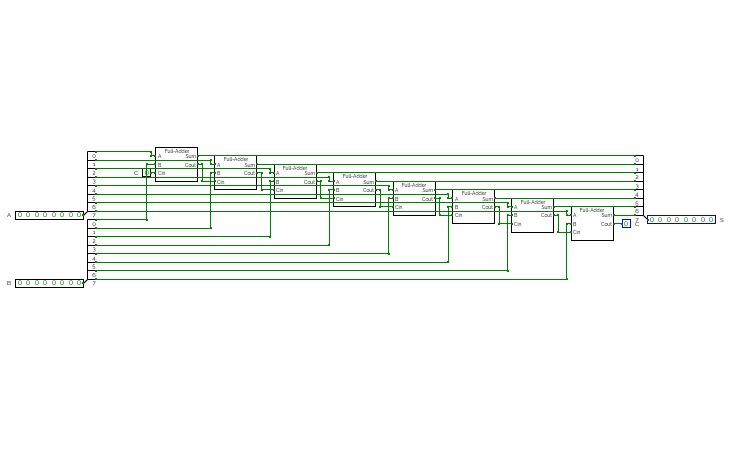

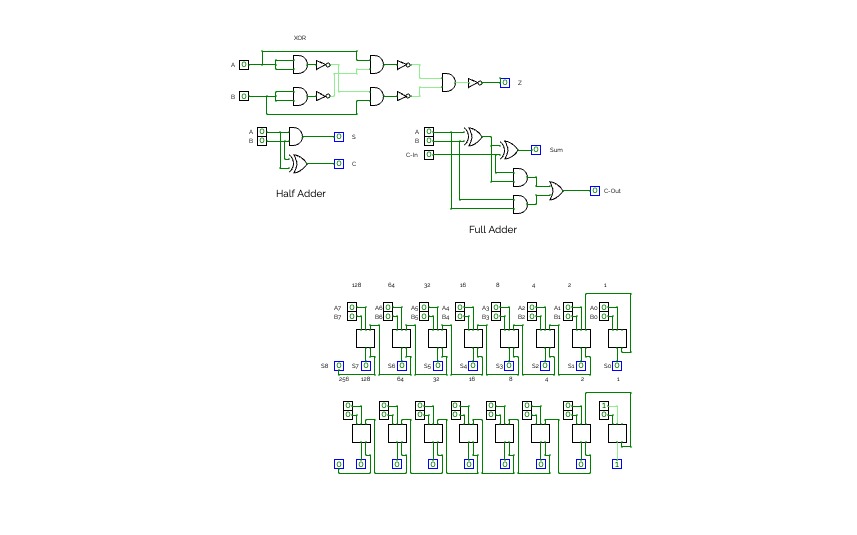
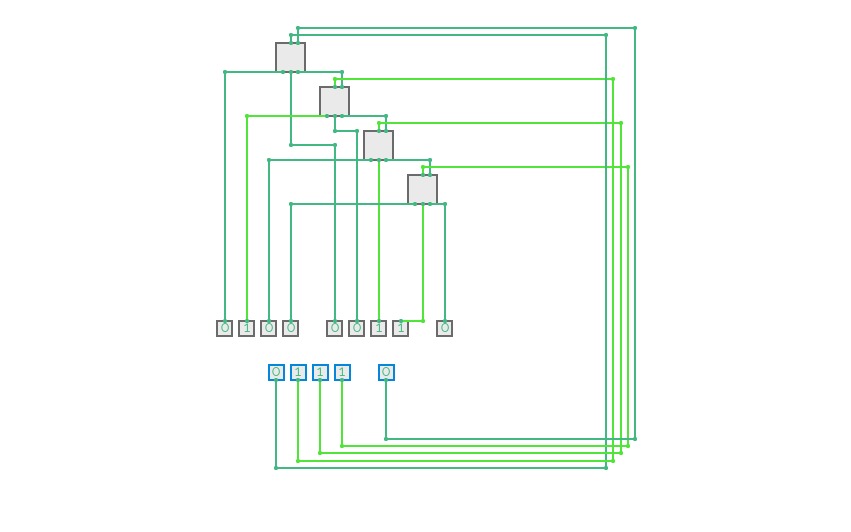

4bit Adder
4bit AdderI am on a journey to make a full calculator. This is the start of my journey and im bringing you along with me. Look at the How it Works tap to learn with me and look at the adder tab to see the 4 bit adder!
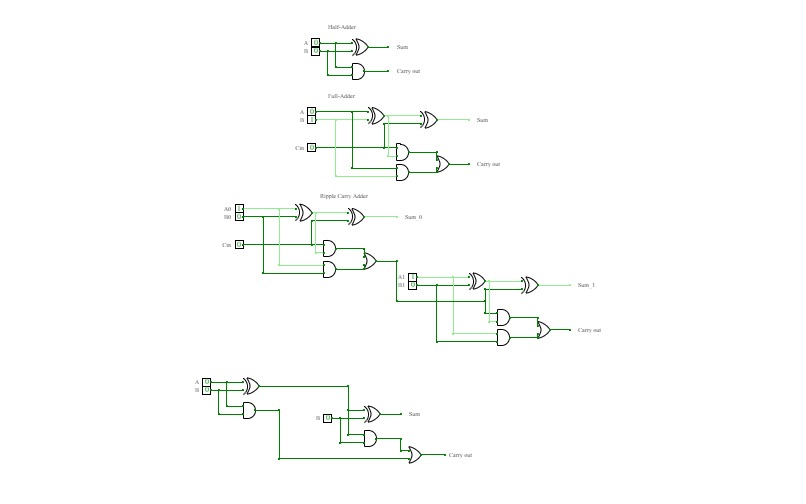
Half and Full Adders
Half and Full Adders

.jpg)
CTH-10 CPU
CTH-10 CPUThis is the CTH-10 CPU. By CrEePeRz24321. (most updated version of the CTH Series) This uses all binary to operate. First click on Power to start. Turn Op to 1 and double click the RAM. Then type in the Op code you want. Only put inputs and read outputs of the User Interface. Wait until the Red light turns Green then start. If you want to change operations, then turn Op to 1 and double click the RAM. Then type in the Op code you want. (If you use full screen, and it keeps on kicking you out when you type, click full screen and then look to the bottom right and press + or - and don't touch the full screen after that unless the RAM input kicks you out)
0 is No Operation - Inputs unavailable
1 is RAM - write the address into In1, write the number you want to store into In2 and press Write.
2 is ADD - write the first digit into In1, write the second digit into In2
3 is Subtract - write the first digit into In1, write the second digit into In2
4 is Counter - Inputs unavailable
5 is AND Gate - write the first digit into In1, write the second digit into In2
6 is a Clock - Inputs unavailable
7 is Accessing the ROM - Inputs unavailable
8 is Binary to Decimal converter
9 is Random Number - Inputs unavailable
10 is Not Gate - write the converting digit into In1
11 is Shift Right* - write the converting digit into In1, write the shift number into In2
12 is Shift Left* - write the converting digit into In1, write the shift number into In2
13 is Multiply - write the first digit into In1, write the second digit into In2
14 is Divide - write the first digit into In1, write the second digit into In2**
HALT is to halt operation
*when using shift the first 3 digits of Out will be nonfunctional
**when using divide the first 4 digits away from the CPU are remainders and the last 4 digits closest to the CPU are quotients.
(There is also a Computer version that doesn't get updated much.)
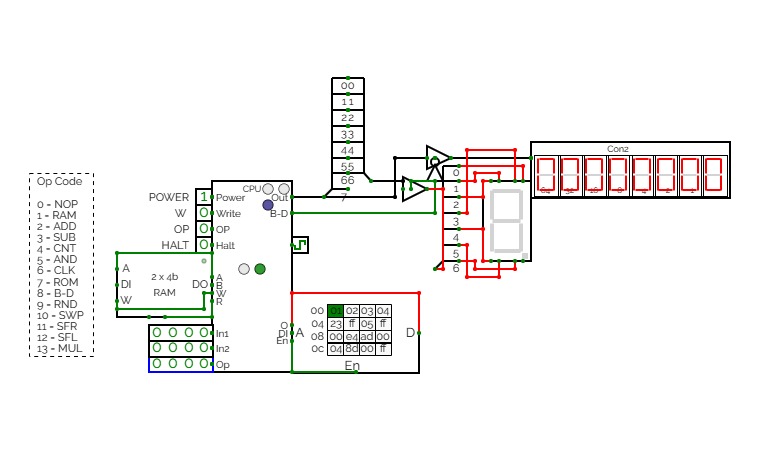
CTH-10
CTH-10This is the CTH-10 CPU. This uses all binary to operate. First click on Power to start. Turn Op to 1 and double click the RAM. Then type in the Op code you want. Only put inputs and read outputs of the User Interface. Wait until the Red light turns Green then start. If you want to change operations, then turn Op to 1 and double click the RAM. Then type in the Op code you want. (If you use full screen, and it keeps on kicking you out when you type, click full screen and then look to the bottom right and press + or - and don't touch the full screen after that unless the RAM input kicks you out)
0 is No Operation - Inputs unavailable
1 is RAM - write the address into In1, write the number you want to store into In2 and press Write.
2 is ADD - write the first digit into In1, write the second digit into In2
3 is Subtract - write the first digit into In1, write the second digit into In2
4 is Counter - Inputs unavailable
5 is AND Gate - write the first digit into In1, write the second digit into In2
6 is a Clock - Inputs unavailable
7 is Accessing the ROM - Inputs unavailable
8 is Binary to Decimal converter
9 is Random Number - Inputs unavailable
10 is Not Gate - write the converting digit into In1
11 is Shift Right* - write the converting digit into In1, write the shift number into In2
12 is Shift Left* - write the converting digit into In1, write the shift number into In2
13 is Multiply - write the first digit into In1, write the second digit into In2
HALT is to halt operation
*when using shift the first 3 digits of Out will be nonfunctional

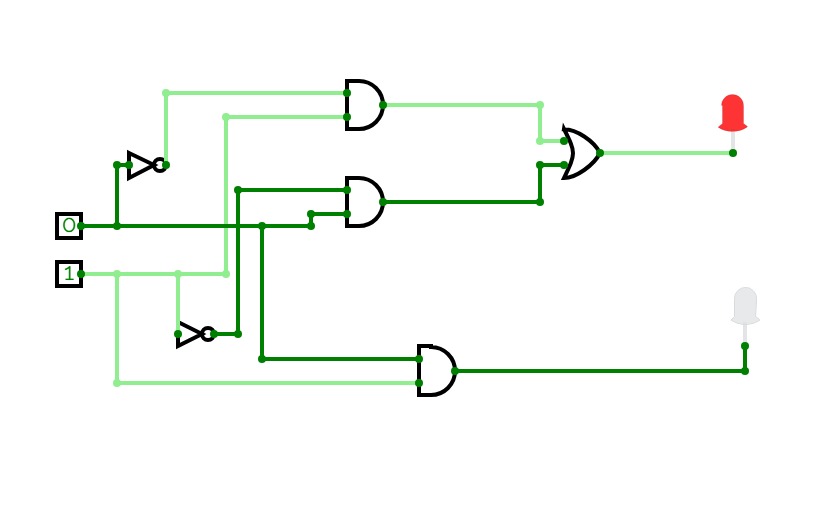
Half Adder
Half Adder
FullAdder
FullAdder






FullAdder
FullAdder












brent-kung-adder
brent-kung-adder8 bit carry look-ahead brent-kung adder

2-bit adder
2-bit adderThis is a simple 4 bit adder, use the (+ -) keys to increase/decrease value for the two inputs.