_(1).jpg)
Basic Circuits for Year 13
Basic Circuits for Year 13Super Sumador
Super Sumador
16-Bit Computer
16-Bit ComputerAlso I am working on adding more instructions for the cpu and the gpu, let me know what might be useful in the comments and definitely check my in progress updates below!
I am running into an issue with per pixel drawing giving a contention error which doesn't make sense as i have tested the chip. unless the rgb screen col and row pins are also outputs i don't get what is going on.
For now though i'm taking a break from that and working on implementing some more of the OPs.
Anything with a * before it is not implemented yet.
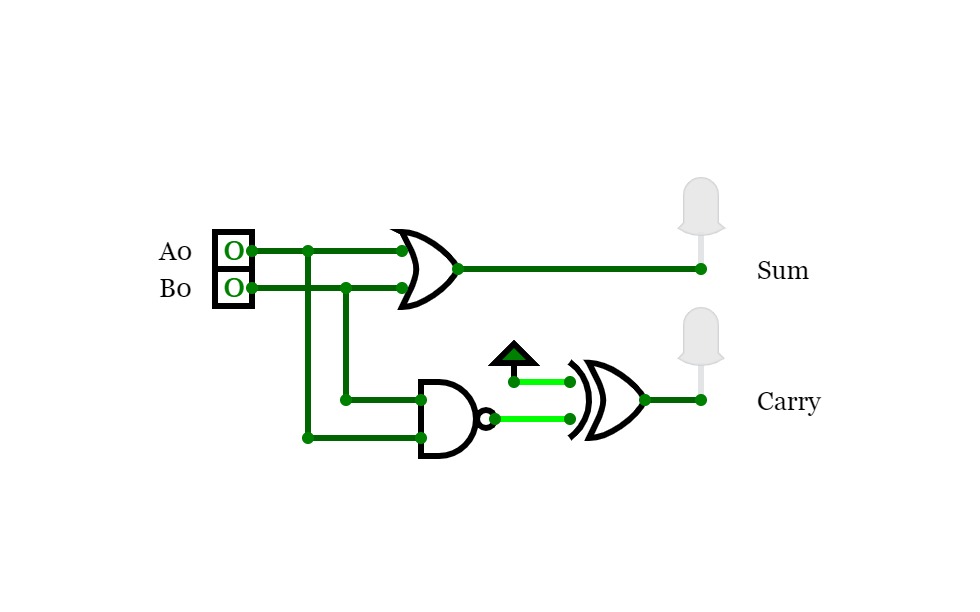
16-bit Prefix Adder
16-bit Prefix Adder16-bit Prefix adder to perform addition even faster, it's a form of carry-lookahead adder (CLA).
The speed up is especially significant for adders of 32-bit, or more. This is only a demo.
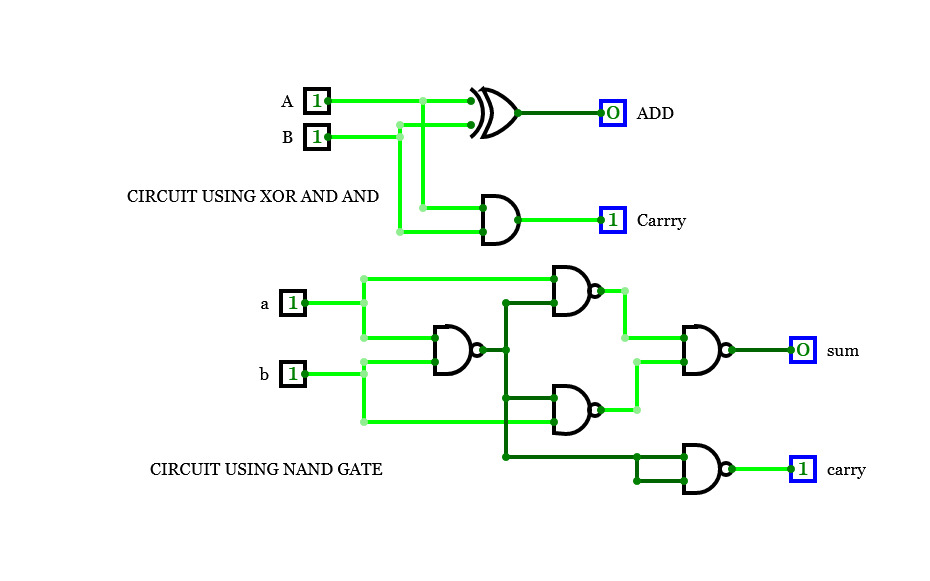
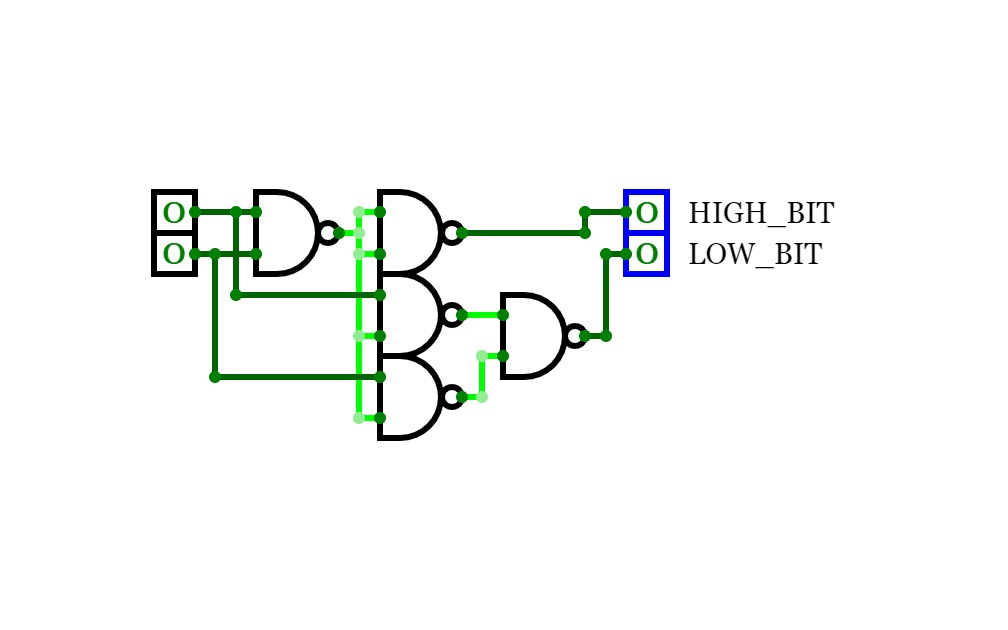
Half Adder
Half AdderA basic circuit and an universal circuit using NAND gate for Half adder
full Adder
full AdderFull Adder
9234_DurgeshPandey_Adder
9234_DurgeshPandey_AdderDurgesh Pandey
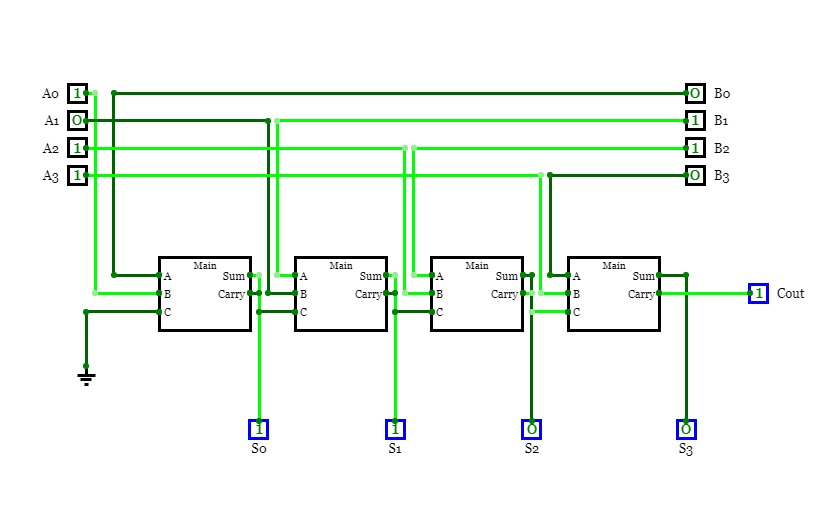
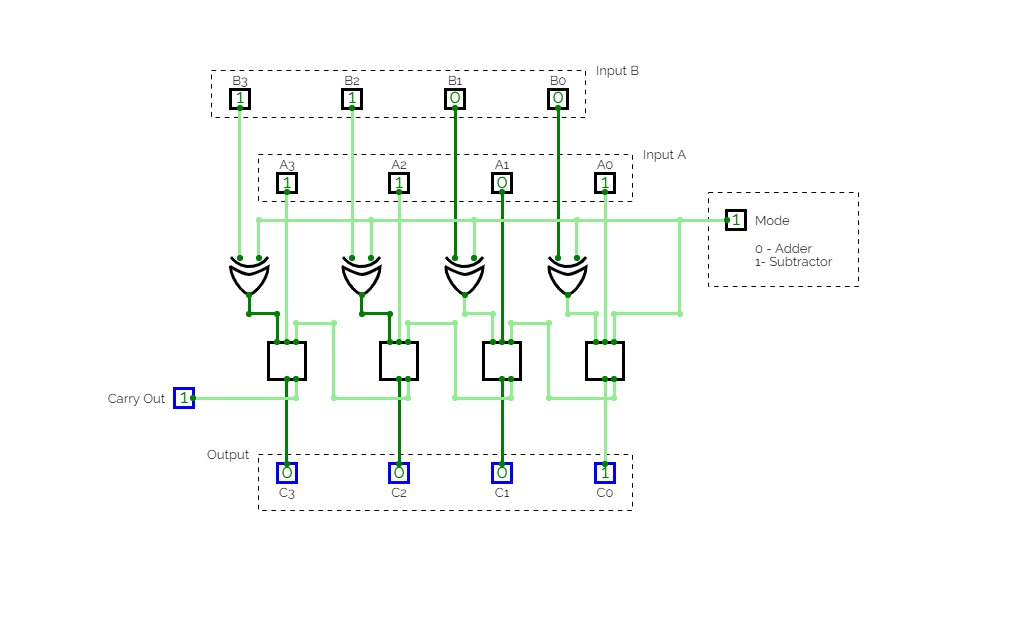
4-Bit Binary Adder Subtractor
DECO Practical Examination

Femto-4v0.5 (Computer)
Femto-4v0.5 (Computer)Latest versions of the 256-Series, including the Femto-4:
https://circuitverse.org/users/4699/projects/256-series
A 16-bit computer/maybe console inspired thing, the Femto-4. This is a fork from the main branch to keep a semi-functional version around. This project was started around November 2020.
Currently runs:
Test code demonstrating basic functionality. First it uses most instructions to ensure they work, before showing the graphical capabilities of the computer.
Features:
Immediate, direct and indirect memory access
Jumps and conditional Jumps
16-bit address space
Switchable Memory Banks
An ALU capable of logical operators, addition, subtraction and shift left
Easy to add to buses
"Fast Execution" - Can run more than one instruction per clock cycle
15x15 pixel display
Will have:
An ALU capable of shift right and multiplying
Inputs, both "controllers" and keyboards
"Faster Execution" - Runs instructions on both edges of the clock pulse
Random number register
Text outputs
Stack
Assembler (hopefully)
Save memory
Several pre-written carts to play with
General Architecture:
The Femto-4 has variable length instructions that are comprised of multiple 16-bit chunks. First the OP Code of the instruction is read, and then depending on the OP Code, additional pieces of data may be read for the operands. This allows execution to become incorrectly offset, which can lead to the execution of garbage if the PC is jumped to an incorrect address. This is usually fine, since the OP Code space is so empty that the data will likely be passed one at a time until the next valid instruction. Data is read through the standard data retrieval system (which is handy since its design is so universal and easy to add to) making this architecture a Von Neuman architecture as opposed to a Harvard architecture, like my previous, worse, computer. The MAR always specifies the address being read to or written from, whilst the MDR always holds the data being written. Data from the data out bus can be written to any special register during the instruction. OP Codes and operands are all 16-bits, which is a bit wasteful in terms of OP Code usage, however it was easier to implement this way, and so that is what I went with.
Memory Mapping:
The 16-bit address space of the Femto-4 is memory mapped, with all data being stored somewhere in the address space, including many special registers like the program counter and the Memory Address Register. The last 48kx16b of memory (all addresses starting with 01, 10, or 11) are dedicated to the cart memory. This is where the interchangeable program would be stored, allowing programs to be easily changed by changing carts. (However, currently there is only one cart). The carts have 32 16kx16b EEPROM/RAM chips, which can be switched between during execution by writing to address 00cc (subject to change). This gives each cart 512kx16b of memory to play with. In theory, additional memory can be added in a cart by creating a similar system on the inside of the cart, which would allow it to swap between even more EEPROM/RAM chips. The initial 16kx16b are therefore mapped to everything else, including a fixed "work" RAM chip that cannot be switched out, the bootloader, the PPU data, general use registers and special use registers.
"Fast Execution":
Execution at the fastest clock speed (one pulse every 50ms, or 20Hz) is terribly slow, and would make reasonable graphics effectively impossible. Due to this, the Femto-4 includes several execution modes that allow the computer to run much faster. There are two registers involved in this, address 00ca, the mode register, and address 00cb, the protection register. When the least significant bit of the mode register is low, the computer runs normally, executing 1 instruction per clock pulse. When it is set high however, the computer enters fast execution, where it executes multiple instructions per clock pulse. This is achieved by looping a rising edge monostable circuit into a falling edge monostable circuit, producing a loop that will pulse indefinitely until the looping line is written high too by some external factor. Stopping the loop is critical since leaving the loop running will stop CircuitVerse's execution, due to it going over the stack limit of the execution. "Fast execution" is always paused by a 0000 OP Code, which ensures that the computer will not attempt to "fast execute" memory that has not been written to. Setting the second bit of the mode register will enable protection. This will ensure that computer only executes as many instructions as the value in the protection register. This protects execution by ensuring that the loop will always pause before the cycle limit is reached. A value of 8 works consistently, though I have not toyed with values much higher. In future, additional execution options will likely be made available, the current planned ones being enabling falling edge execution as well as rising edge execution, to double the execution speed, updating graphics on both edges of the clock pulse, updating graphics every other clock pulse, updating graphics when the update graphics command is run, and disabling graphics.
Graphics:
The Femto-4 is capable of driving a 15x15 15bit direct colour screen. It has space for 32 "sprites" which are rectangles with an assigned colour. Currently, every time the clock pulses low, the screen is refreshed. Should a falling edge "fast execution" mode be added and work, the falling edge should only be used to execute game code, since writing graphics data as the screen is being drawn may mess up the graphics. These 32 "sprites" have their data stored in the PPU RAM in the following format: The first 16 bits are the corners of the rectangle, with each coordinate being 4 bits. The coordinates are ordered x1 x2 y1 y2. The next 16 bits are the sprites colour, with the first 15 bits being used for 15 bit direct colour, and the last bit being used to enable or disable drawing the sprite. Since the screen is not wiped every time it is refreshed, the background must be sprite to ensure that the screen is fully wiped before the rest of the sprites are drawn on. The "sprites" are drawn in memory order, with the "sprite" with the largest address always being drawn last and therefore on top, of all other "sprites". This is achieved by using the exact same monostable clock system as "Fast Execution", which reads off all the sprite data and draws them to the screen in a single clock pulse. This can loop more times safely than the main CPU since it has less dependencies which dramatically increase the simulation's stack usage. The demonstration code uses two "sprites". The first "sprite" is the black background, and the second "sprite" is the red rectangle. The coordinate value of the red rectangle is incremented every frame, causing the animation. Had I had more storage I might have incremented the colour as well to show the colour capabilities of the Femto-4. Whilst driving a larger screen might be nice, given the limit in the number of instructions per second, it is unlikely that it could be well utilised, which is why I have chosen this screen size. A variation with larger screens may appear at some point, but this is a low priority for me.
ALU:
The basic ALU (currently the only implemented bit of the ALU) was inspired by the ALU-74LS181. It was designed to flexibly change between various operations by changing an additional piece of data which is bundled in the OP Code. This allows a single ALU to handle all the required processes, such as the basic binary logic operations, shift right, adding and subtracting. This is unlike my previous computer which had different chips for each operation it could do. Additional capability chips, such as multiplication and shifting right will be added later.
General Registers:
This computer probably has more general registers than it should. What makes the 256 general registers unique is that they can be easily piped into the A and B operators when performing ALU operations. This allows ALU instructions to only have one operand, with the lower 8-bits being the register address of value A, and with the higher 8-bits being the register address of value B.
Timing:
This computer is timed using a several standard delay chips. The pulse length running in to the computer is about 10k units long. This then runs into the pulse generator which pulses 32 unique lines with a 20k delay between them which can then be used to time when control lines pulse. This is bundled together into a 32-bit timing bus, which then uses bit selectors to select how much delay that pulse will have. This is why there are 32 sub-circuits which are effectively just bit specific bit selectors - they allow me to "compactly" build timing circuitry. In addition to the main delay of 20k between the chosen bits, I can add "on-delays" to further delay the control line, allowing me to ensure that control lines like the enable read line can be on before the register reads from them. "On-delays" were first constructed to ensure that the data out line did not have contention issues - it ensured that the previous address outputting data was disabled before the next address outputting data onto the line was enabled. They add 1k of delay on the rising edge, and less than 10 delay on the falling edge. This way I do not need to worry about "on-delays" increasing the delay of one command into the next. The "Fast Execution" loop gives a pulse of 300k, with a delay between pulses of around 600k. This ensures that the previous instruction will finish before the next instruction starts. I do not entirely understand how the timing system works, since the in my mind it should be producing contention issues, however proofing it against that breaks the system entirely.
Other Notes:
You may note that I use 32b EEPROM banks instead of 16b ones. This choice was made to reduce the number of EEPROM banks required. Each half of the EEPROM's 32b output is treated as one address. Whilst this added a slight bit of additional complexity in writing, it halved the number of EEPROM banks required. This project was started when I realised that EEPROM banks could be that large, since a major sticking point in a previous attempt was the number of EEPROM banks required. (That attempt is private and completely dysfunctional. It also suffers from contention errors caused by incomplete splitters.)
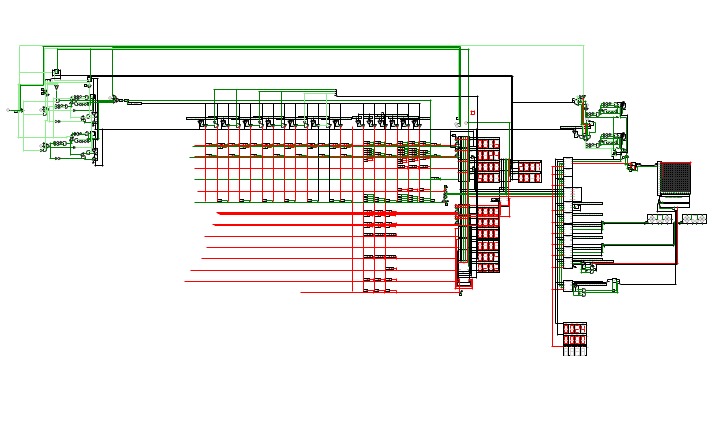
Femto-4v0.7 (Computer)
Femto-4v0.7 (Computer)Latest versions of the 256-Series, including the Femto-4:
https://circuitverse.org/users/4699/projects/256-series
A 16-bit computer/maybe console inspired thing, the Femto-4. This is a fork from the main branch to keep a semi-functional version around. This project was started around November 2020.
Currently runs:
Test "Hello World" code demonstrating text input and output functionality of the computer. Once the computer has outputted "Hello World! Type something!" it will shift in any input from the keyboard into the text output.
Features:
Immediate, direct and indirect memory access
Jumps and conditional Jumps
16-bit address space
Switchable Memory Banks
An ALU capable of logical operators, addition, subtraction and shift left
Easy to add to buses
"Fast Execution" - Can run more than one instruction per clock cycle
15x15 pixel display
Updates:
Inputs, both "controllers" and keyboards
"Faster Execution" - Runs instructions on both edges of the clock pulse
Random number register
Text outputs
Will have:
An ALU capable of shift right and multiplying
Stack
Assembler (hopefully)
Save memory
Several pre-written carts to play with
Maybe separate GPU to help with graphics handling
General Architecture:
The Femto-4 has variable length instructions that are comprised of multiple 16-bit chunks. First the OP Code of the instruction is read, and then depending on the OP Code, additional pieces of data may be read for the operands. This allows execution to become incorrectly offset, which can lead to the execution of garbage if the PC is jumped to an incorrect address. This is usually fine, since the OP Code space is so empty that the data will likely be passed one at a time until the next valid instruction. Data is read through the standard data retrieval system (which is handy since its design is so universal and easy to add to) making this architecture a Von Neuman architecture as opposed to a Harvard architecture, like my previous, worse, computer. The MAR always specifies the address being read to or written from, whilst the MDR always holds the data being written. Data from the data out bus can be written to any special register during the instruction. OP Codes and operands are all 16-bits, which is a bit wasteful in terms of OP Code usage, however it was easier to implement this way, and so that is what I went with.
Memory Mapping:
The 16-bit address space of the Femto-4 is memory mapped, with all data being stored somewhere in the address space, including many special registers like the program counter and the Memory Address Register. The last 48kx16b of memory (all addresses starting with 01, 10, or 11) are dedicated to the cart memory. This is where the interchangeable program would be stored, allowing programs to be easily changed by changing carts. (However, currently there is only one cart). The carts have 32 16kx16b EEPROM/RAM chips, which can be switched between during execution by writing to address 00cc (subject to change). This gives each cart 512kx16b of memory to play with. In theory, additional memory can be added in a cart by creating a similar system on the inside of the cart, which would allow it to swap between even more EEPROM/RAM chips. The initial 16kx16b are therefore mapped to everything else, including a fixed "work" RAM chip that cannot be switched out, the bootloader, the PPU data, general use registers and special use registers.
"Fast Execution":
Execution at the fastest clock speed (one pulse every 50ms, or 20Hz) is terribly slow, and would make reasonable graphics effectively impossible. Due to this, the Femto-4 includes several execution modes that allow the computer to run much faster. There are two registers involved in this, address 00ca, the mode register, and address 00cb, the protection register. When the least significant bit of the mode register is low, the computer runs normally, executing 1 instruction per clock pulse. When it is set high however, the computer enters fast execution on the rising edge, where it executes multiple instructions per clock pulse. This is achieved by looping a rising edge monostable circuit into a falling edge monostable circuit, producing a loop that will pulse indefinitely until the looping line is written high too by some external factor. Stopping the loop is critical since leaving the loop running will stop CircuitVerse's execution, due to it going over the stack limit of the execution. "Fast execution" is always paused by a 0000 OP Code, which ensures that the computer will not attempt to "fast execute" memory that has not been written to. Setting the 3 bit of the mode register high will enable protection. This will ensure that computer only executes as many instructions as the value in the protection register. This protects execution by ensuring that the loop will always pause before the cycle limit is reached. A value of hex 10 (16) is the highest value I have found to work. Setting the 2nd bit of the mode register high will enable the clock to run fast execution on the falling edge of the clock as well, doubling execution speed. This raises the max execution speed to 640 instructions per second. On the other end of the mode register are the graphics mode. The highest two bits give the graphics update mode, 00 for rising edge only (normal speed), 01 for duel edge (double speed), 10 for every other clock pulse (half speed), and 11 for when given the correct OP Code (controlled updates). The OP Code used for the graphics update is (01). The third most significant bit is the graphics disable bit. Setting it high stops updating the graphics.
Graphics:
The Femto-4 is capable of driving a 15x15 15bit direct colour screen. It has space for 32 "sprites" which are rectangles with an assigned colour. Currently, every time the clock pulses low, the screen is refreshed. Should a falling edge "fast execution" mode be added and work, the falling edge should only be used to execute game code, since writing graphics data as the screen is being drawn may mess up the graphics. These 32 "sprites" have their data stored in the PPU RAM in the following format: The first 16 bits are the corners of the rectangle, with each coordinate being 4 bits. The coordinates are ordered x1 x2 y1 y2. The next 16 bits are the sprites colour, with the first 15 bits being used for 15 bit direct colour, and the last bit being used to enable or disable drawing the sprite. Since the screen is not wiped every time it is refreshed, the background must be sprite to ensure that the screen is fully wiped before the rest of the sprites are drawn on. The "sprites" are drawn in memory order, with the "sprite" with the largest address always being drawn last and therefore on top, of all other "sprites". This is achieved by using the exact same monostable clock system as "Fast Execution", which reads off all the sprite data and draws them to the screen in a single clock pulse. This can loop more times safely than the main CPU since it has less dependencies which dramatically increase the simulation's stack usage. The demonstration code uses two "sprites". The first "sprite" is the black background, and the second "sprite" is the red rectangle. The coordinate value of the red rectangle is incremented every frame, causing the animation. Had I had more storage I might have incremented the colour as well to show the colour capabilities of the Femto-4. Whilst driving a larger screen might be nice, given the limit in the number of instructions per second, it is unlikely that it could be well utilised, which is why I have chosen this screen size. A variation with larger screens may appear at some point, but this is a low priority for me.
ALU:
The basic ALU (currently the only implemented bit of the ALU) was inspired by the ALU-74LS181. It was designed to flexibly change between various operations by changing an additional piece of data which is bundled in the OP Code. This allows a single ALU to handle all the required processes, such as the basic binary logic operations, shift right, adding and subtracting. This is unlike my previous computer which had different chips for each operation it could do. Additional capability chips, such as multiplication and shifting right will be added later.
General Registers:
This computer probably has more general registers than it should. What makes the 256 general registers unique is that they can be easily piped into the A and B operators when performing ALU operations. This allows ALU instructions to only have one operand, with the lower 8-bits being the register address of value A, and with the higher 8-bits being the register address of value B.
Timing:
This computer is timed using a several standard delay chips. The pulse length running in to the computer is about 10k units long. This then runs into the pulse generator which pulses 32 unique lines with a 20k delay between them which can then be used to time when control lines pulse. This is bundled together into a 32-bit timing bus, which then uses bit selectors to select how much delay that pulse will have. This is why there are 32 sub-circuits which are effectively just bit specific bit selectors - they allow me to "compactly" build timing circuitry. In addition to the main delay of 20k between the chosen bits, I can add "on-delays" to further delay the control line, allowing me to ensure that control lines like the enable read line can be on before the register reads from them. "On-delays" were first constructed to ensure that the data out line did not have contention issues - it ensured that the previous address outputting data was disabled before the next address outputting data onto the line was enabled. They add 1k of delay on the rising edge, and less than 10 delay on the falling edge. This way I do not need to worry about "on-delays" increasing the delay of one command into the next. The "Fast Execution" loop gives a pulse of 300k, with a delay between pulses of around 600k. This ensures that the previous instruction will finish before the next instruction starts. I do not entirely understand how the timing system works, since the in my mind it should be producing contention issues, however proofing it against that breaks the system entirely.
Other Notes:
You may note that I use 32b EEPROM banks instead of 16b ones. This choice was made to reduce the number of EEPROM banks required. Each half of the EEPROM's 32b output is treated as one address. Whilst this added a slight bit of additional complexity in writing, it halved the number of EEPROM banks required. This project was started when I realised that EEPROM banks could be that large, since a major sticking point in a previous attempt was the number of EEPROM banks required. (That attempt is private and completely dysfunctional. It also suffers from contention errors caused by incomplete splitters.) The memory wrappers allow external chips to interact with the main dat control system, in this case used for RNG, controllers, the keyboard, and driving the text output.
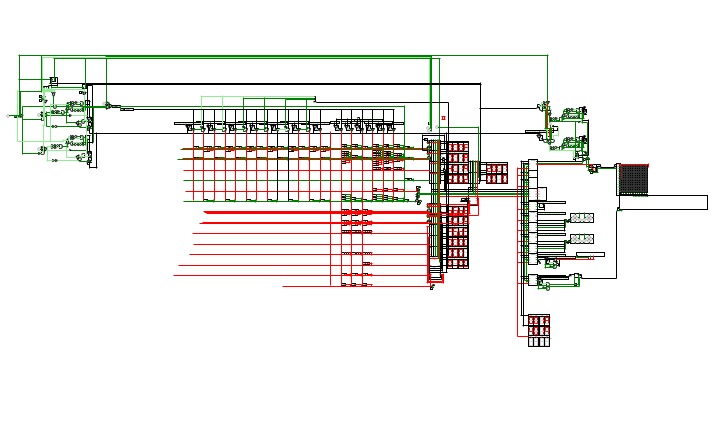
Femto-4v0.7.1 (Computer)
Femto-4v0.7.1 (Computer)Latest versions of the 256-Series, including the Femto-4:
https://circuitverse.org/users/4699/projects/256-series
A 16-bit computer/maybe console inspired thing, the Femto-4. This is a fork from the main branch to keep a semi-functional version around. This project was started around November 2020.
Currently runs:
Outputs the twelve days of Christmas into the text output.
Features:
Immediate, direct and indirect memory access
Jumps and conditional Jumps
16-bit address space
Switchable Memory Banks
An ALU capable of logical operators, addition, subtraction and shift left
Easy to add to buses
"Fast Execution" - Can run more than one instruction per clock cycle
15x15 pixel display
Updates:
Inputs, both "controllers" and keyboards
"Faster Execution" - Runs instructions on both edges of the clock pulse
Random number register
Text outputs
Will have:
An ALU capable of shift right and multiplying
Stack
Assembler (hopefully)
Save memory
Several pre-written carts to play with
Maybe separate GPU to help with graphics handling
General Architecture:
The Femto-4 has variable length instructions that are comprised of multiple 16-bit chunks. First the OP Code of the instruction is read, and then depending on the OP Code, additional pieces of data may be read for the operands. This allows execution to become incorrectly offset, which can lead to the execution of garbage if the PC is jumped to an incorrect address. This is usually fine, since the OP Code space is so empty that the data will likely be passed one at a time until the next valid instruction. Data is read through the standard data retrieval system (which is handy since its design is so universal and easy to add to) making this architecture a Von Neuman architecture as opposed to a Harvard architecture, like my previous, worse, computer. The MAR always specifies the address being read to or written from, whilst the MDR always holds the data being written. Data from the data out bus can be written to any special register during the instruction. OP Codes and operands are all 16-bits, which is a bit wasteful in terms of OP Code usage, however it was easier to implement this way, and so that is what I went with.
Memory Mapping:
The 16-bit address space of the Femto-4 is memory mapped, with all data being stored somewhere in the address space, including many special registers like the program counter and the Memory Address Register. The last 48kx16b of memory (all addresses starting with 01, 10, or 11) are dedicated to the cart memory. This is where the interchangeable program would be stored, allowing programs to be easily changed by changing carts. (However, currently there is only one cart). The carts have 32 16kx16b EEPROM/RAM chips, which can be switched between during execution by writing to address 00cc (subject to change). This gives each cart 512kx16b of memory to play with. In theory, additional memory can be added in a cart by creating a similar system on the inside of the cart, which would allow it to swap between even more EEPROM/RAM chips. The initial 16kx16b are therefore mapped to everything else, including a fixed "work" RAM chip that cannot be switched out, the bootloader, the PPU data, general use registers and special use registers.
"Fast Execution":
Execution at the fastest clock speed (one pulse every 50ms, or 20Hz) is terribly slow, and would make reasonable graphics effectively impossible. Due to this, the Femto-4 includes several execution modes that allow the computer to run much faster. There are two registers involved in this, address 00ca, the mode register, and address 00cb, the protection register. When the least significant bit of the mode register is low, the computer runs normally, executing 1 instruction per clock pulse. When it is set high however, the computer enters fast execution on the rising edge, where it executes multiple instructions per clock pulse. This is achieved by looping a rising edge monostable circuit into a falling edge monostable circuit, producing a loop that will pulse indefinitely until the looping line is written high too by some external factor. Stopping the loop is critical since leaving the loop running will stop CircuitVerse's execution, due to it going over the stack limit of the execution. "Fast execution" is always paused by a 0000 OP Code, which ensures that the computer will not attempt to "fast execute" memory that has not been written to. Setting the 3 bit of the mode register high will enable protection. This will ensure that computer only executes as many instructions as the value in the protection register. This protects execution by ensuring that the loop will always pause before the cycle limit is reached. A value of hex 10 (16) is the highest value I have found to work. Setting the 2nd bit of the mode register high will enable the clock to run fast execution on the falling edge of the clock as well, doubling execution speed. This raises the max execution speed to 640 instructions per second. On the other end of the mode register are the graphics mode. The highest two bits give the graphics update mode, 00 for rising edge only (normal speed), 01 for duel edge (double speed), 10 for every other clock pulse (half speed), and 11 for when given the correct OP Code (controlled updates). The OP Code used for the graphics update is (01). The third most significant bit is the graphics disable bit. Setting it high stops updating the graphics.
Graphics:
The Femto-4 is capable of driving a 15x15 15bit direct colour screen. It has space for 32 "sprites" which are rectangles with an assigned colour. Currently, every time the clock pulses low, the screen is refreshed. Should a falling edge "fast execution" mode be added and work, the falling edge should only be used to execute game code, since writing graphics data as the screen is being drawn may mess up the graphics. These 32 "sprites" have their data stored in the PPU RAM in the following format: The first 16 bits are the corners of the rectangle, with each coordinate being 4 bits. The coordinates are ordered x1 x2 y1 y2. The next 16 bits are the sprites colour, with the first 15 bits being used for 15 bit direct colour, and the last bit being used to enable or disable drawing the sprite. Since the screen is not wiped every time it is refreshed, the background must be sprite to ensure that the screen is fully wiped before the rest of the sprites are drawn on. The "sprites" are drawn in memory order, with the "sprite" with the largest address always being drawn last and therefore on top, of all other "sprites". This is achieved by using the exact same monostable clock system as "Fast Execution", which reads off all the sprite data and draws them to the screen in a single clock pulse. This can loop more times safely than the main CPU since it has less dependencies which dramatically increase the simulation's stack usage. The demonstration code uses two "sprites". The first "sprite" is the black background, and the second "sprite" is the red rectangle. The coordinate value of the red rectangle is incremented every frame, causing the animation. Had I had more storage I might have incremented the colour as well to show the colour capabilities of the Femto-4. Whilst driving a larger screen might be nice, given the limit in the number of instructions per second, it is unlikely that it could be well utilised, which is why I have chosen this screen size. A variation with larger screens may appear at some point, but this is a low priority for me.
ALU:
The basic ALU (currently the only implemented bit of the ALU) was inspired by the ALU-74LS181. It was designed to flexibly change between various operations by changing an additional piece of data which is bundled in the OP Code. This allows a single ALU to handle all the required processes, such as the basic binary logic operations, shift right, adding and subtracting. This is unlike my previous computer which had different chips for each operation it could do. Additional capability chips, such as multiplication and shifting right will be added later.
General Registers:
This computer probably has more general registers than it should. What makes the 256 general registers unique is that they can be easily piped into the A and B operators when performing ALU operations. This allows ALU instructions to only have one operand, with the lower 8-bits being the register address of value A, and with the higher 8-bits being the register address of value B.
Timing:
This computer is timed using a several standard delay chips. The pulse length running in to the computer is about 10k units long. This then runs into the pulse generator which pulses 32 unique lines with a 20k delay between them which can then be used to time when control lines pulse. This is bundled together into a 32-bit timing bus, which then uses bit selectors to select how much delay that pulse will have. This is why there are 32 sub-circuits which are effectively just bit specific bit selectors - they allow me to "compactly" build timing circuitry. In addition to the main delay of 20k between the chosen bits, I can add "on-delays" to further delay the control line, allowing me to ensure that control lines like the enable read line can be on before the register reads from them. "On-delays" were first constructed to ensure that the data out line did not have contention issues - it ensured that the previous address outputting data was disabled before the next address outputting data onto the line was enabled. They add 1k of delay on the rising edge, and less than 10 delay on the falling edge. This way I do not need to worry about "on-delays" increasing the delay of one command into the next. The "Fast Execution" loop gives a pulse of 300k, with a delay between pulses of around 600k. This ensures that the previous instruction will finish before the next instruction starts. I do not entirely understand how the timing system works, since the in my mind it should be producing contention issues, however proofing it against that breaks the system entirely.
Other Notes:
You may note that I use 32b EEPROM banks instead of 16b ones. This choice was made to reduce the number of EEPROM banks required. Each half of the EEPROM's 32b output is treated as one address. Whilst this added a slight bit of additional complexity in writing, it halved the number of EEPROM banks required. This project was started when I realised that EEPROM banks could be that large, since a major sticking point in a previous attempt was the number of EEPROM banks required. (That attempt is private and completely dysfunctional. It also suffers from contention errors caused by incomplete splitters.) The memory wrappers allow external chips to interact with the main dat control system, in this case used for RNG, controllers, the keyboard, and driving the text output.
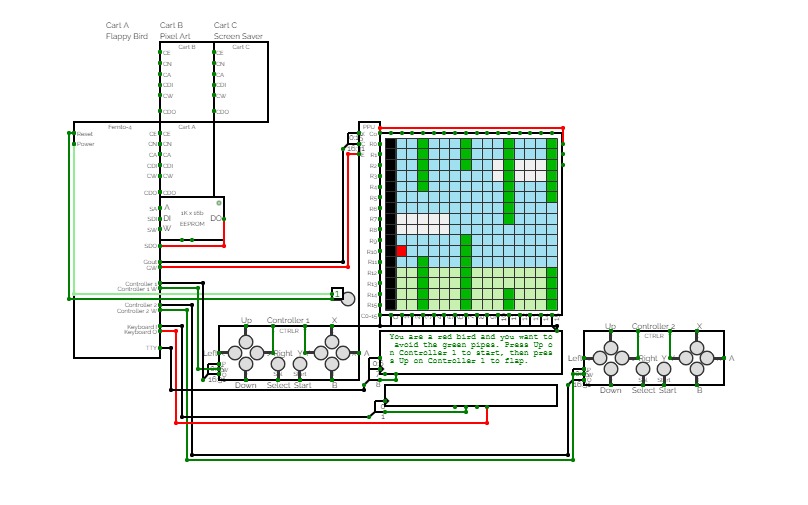
Femto-4v1.2 (Computer)
Femto-4v1.2 (Computer)Latest versions of the 256-Series, including the Femto-4:
https://circuitverse.org/users/4699/projects/256-series
A 16-bit computer/maybe console inspired thing, the Femto-4. This is a fork from the main branch to keep a semi-functional version around. This project was started around November 2020.
Currently runs:
Cart A: Flappy Bird
Cart B: Some Pixel Art
Cart C: Screensaver
Assembler:
https://repl.it/@Sanderokianstfe/Femto-4-Assembler#DeveloperGuide.txt
Features:
Immediate, direct and indirect memory access
Jumps and conditional Jumps
16-bit address space
Switchable Memory Banks, allowing for a standard Cart to hold up to 512kx16b of data
An ALU capable of logical operators, addition, subtraction and shift left
Easy to add to buses
"Fast Execution" - Can run more than one instruction per clock cycle
16x16 pixel display
Inputs, both "controllers" and keyboards
"Faster Execution" - Runs instructions on both edges of the clock pulse
Random number generator
Text outputs
An ALU capable of shift right, multiplying, dividing, and other specialised functions
Stack
Assembler (written in an external program)
Save memory
Two pre-written carts to play with
Fixed code controlled graphics updates
Made Bootloader clear TTY, Keyboard, and Controller Pushed
Fixed Register ALU instructions
Updated Cart A and Cart B to make use of the Register ALU instructions
Updates:
Another pre-written cart to play with
Updated the sprite-art cart to respond to the start button on both controllers.
Will have:
More pre-written carts
Bug fixes
Do fork the project and write your own code for it! If you want more information on how to do so read the Developer Guide in the assembler.
Note:
The Flappy Bird high score is mine. If you want to save your own scores permanently you will have to fork it.
General Architecture:
The Femto-4 has variable length instructions that are comprised of multiple 16-bit chunks. First the OP Code of the instruction is read, and then depending on the OP Code, additional pieces of data may be read for the operands. This allows execution to become incorrectly offset, which can lead to the execution of garbage if the PC is jumped to an incorrect address. This is usually fine, since the OP Code space is so empty that the data will likely be passed one at a time until the next valid instruction. Data is read through the standard data retrieval system (which is handy since its design is so universal and easy to add to) making this architecture a Von Neuman architecture as opposed to a Harvard architecture, like my previous, worse, computer. The MAR always specifies the address being read to or written from, whilst the MDR always holds the data being written. Data from the data out bus can be written to any special register during the instruction. OP Codes and operands are all 16-bits, which is a bit wasteful in terms of OP Code usage, however it was easier to implement this way, and so that is what I went with (and there are a lot of ALU processes).
Memory Mapping:
The 16-bit address space of the Femto-4 is memory mapped, with all data being stored somewhere in the address space. The last 48kx16b of memory (all addresses starting with 01, 10, or 11) are dedicated to the cart memory. This is where the interchangeable program would be stored, allowing programs to be easily changed by changing carts. (However, currently there are currently only two carts). The carts have 32 16kx16b EEPROM/RAM chips, which can be switched between during execution by writing to address 00cc. This gives each cart 512kx16b of memory to play with. In theory, additional memory can be added in a cart by creating a similar system on the inside of the cart, which would allow it to swap between even more EEPROM/RAM chips. The initial 16kx16b are therefore mapped to everything else, including a fixed "work" RAM chip that cannot be switched out, the bootloader, the PPU data, general use registers, the, stack, inputs, outputs, and special use registers.
"Fast Execution":
Execution at the fastest clock speed (one pulse every 50ms, or 20Hz) is terribly slow, and would make reasonable graphics effectively impossible. Due to this, the Femto-4 includes several execution modes that allow the computer to run much faster. There are two registers involved in this, address 00ca, the mode register, and address 00cb, the protection register. When the two least significant bits of the mode register are low, the computer runs normally, executing 1 instruction per clock pulse. When it is set high however, the computer enters fast execution on the rising edge, where it executes multiple instructions per clock pulse. This is achieved by looping a rising edge monostable circuit into a falling edge monostable circuit, producing a loop that will pulse indefinitely until the looping line is written high to by some external factor. Stopping the loop is critical since leaving the loop running will stop CircuitVerse's execution, due to it going over the stack limit of the execution. "Fast execution" is always paused by a 0x0000 OP Code, which ensures that the computer will not attempt to "fast execute" memory that has not been written to. It is also paused by the OP Code 0x0001. Setting the 3 bit of the mode register high will enable protection. This will ensure that computer only executes as many instructions as the value in the protection register. This protects execution by ensuring that the loop will always pause before the cycle limit is reached. Since some operations are far more complex than other operations, the maximum number of instructions per clock pulse is variable, and testing should always be conducted to ensure that the limit is not reached. Due to this, for games that need regular graphics updates, it is recommended that protection is not used, and instead the pauses are fully code controlled. Setting the 2nd bit of the mode register high will enable the clock to run fast execution on the falling edge of the clock as well, doubling execution speed. On the other end of the mode register are the graphics mode. The highest two bits give the graphics update mode, 00 for falling edge only (normal speed), 01 for dual edge (double speed), 10 for every other clock pulse (half speed), and 11 for code controlled, where the 0x0001 OP Code is required to update the graphics. The third most significant bit is the graphics disable bit. Setting it high stops updating the graphics. The mode and protection values are only updated on the rising edge of the clock pulse, and therefore there should always be pauses before and after any execution mode or protection change.
Graphics:
The Femto-4 is capable of driving a 16x16 15bit direct colour screen. It has space for 32 "sprites" which are rectangles with an assigned colour. Currently, every time the clock pulses low, the screen is refreshed. When using dual-edge "Faster Execution", the falling edge should only be used to execute game code, since writing graphics data as the screen is being drawn may mess up the graphics. These 32 "sprites" have their data stored in the PPU RAM in the following format: The first 16 bits are the corners of the rectangle, with each coordinate being 4 bits. The coordinates are ordered x1 x2 y1 y2. The next 16 bits are the sprites colour, with the first 15 bits being used for 15 bit direct colour, and the last bit being used to enable or disable drawing the sprite. Since the screen is not wiped every time it is refreshed, the background must be sprite to ensure that the screen is fully wiped before the rest of the sprites are drawn on. Control of this allows carts to draw a single frame over multiple updates, allowing the 32-sprite limit to be bypassed. The "sprites" are drawn in memory order, with the "sprite" with the largest address always being drawn last and therefore on top, of all other "sprites". This is achieved by using the exact same monostable clock system as "Fast Execution", which reads off all the sprite data and draws them to the screen in a single clock pulse. This can loop more times safely than the main CPU since it has less dependencies which dramatically increase the simulation's stack usage.
ALU:
The basic ALU was inspired by the ALU-74LS181. It was designed to flexibly change between various operations by changing an additional piece of data which is bundled in the OP Code. This allows a single ALU to handle all the required processes, such as the basic binary logic operations, shift left, adding, and subtracting. This is unlike my previous computer which had different chips for each operation it could do. The Femto-4 also can multiply, divide, shift right, shift left/right by a specified number of bits, and perform operations designed to work with the Femto-4's graphics data.
Conditional Jumps:
The Femto-4 can perform immediate and direct jumps depending on the flags, a specified bit of the accumulator, and the clock. The flag jumps allow for comparisons to be made. There are three flags, the carry, the most significant bit in the accumulator, and if the accumulator value is 0, the equals flag. By performing A-B, we can compare A and B by looking at the flags. If the equals flag is true, then A=B, since A-B = 0. If the most significant bit is 0, then the number is positive or 0 (by two's complement) and therefore A>=B. The comparison is not entirely correct for numbers in two's complement (a large positive number and a large negative number when subtracted can yield a positive number), but for small values it works well. Whilst we cannot directly check A<=B using A-B in this design, we can simply flip the subtraction to B-A to do so.
The accumulator bit testing is mainly used to check for controller inputs. Since each button in the controller is mapped to one bit, bit testing that bit effectively allows us to check if a button has been pressed. In theory a similar test could be performed using an AND instruction, and checking if the result is equal to 0 or not.
The jump on clock is there to ensure that we can jump execution on the right clock pulse, which ensures that graphics can be updated on the edge of execution.
Timing:
This computer is timed using several standard delay chips. The pulse length running in to the computer is about 10k units long. Therefore, different parts an instruction are separated by 20k unit delays. Further control of timings inside these periods is achieved through 1k "On Delays", which have a 1k delay turning on, but a 0k delay turning off, ensuring that pulses do not bleed into the next pulse. For more information see here: https://circuitverse.org/users/4699/projects/circuitverse-delay-introduction.
Other Notes:
The memory wrappers allow external chips to interact with the main data control system, in this case used for RNG, controllers, the keyboard, and driving the text output.
For more information, please read the developer guide found in the Femto-4's Assembler, or just post a comment and ask me.
This is a secret to everybody, unless you found it.
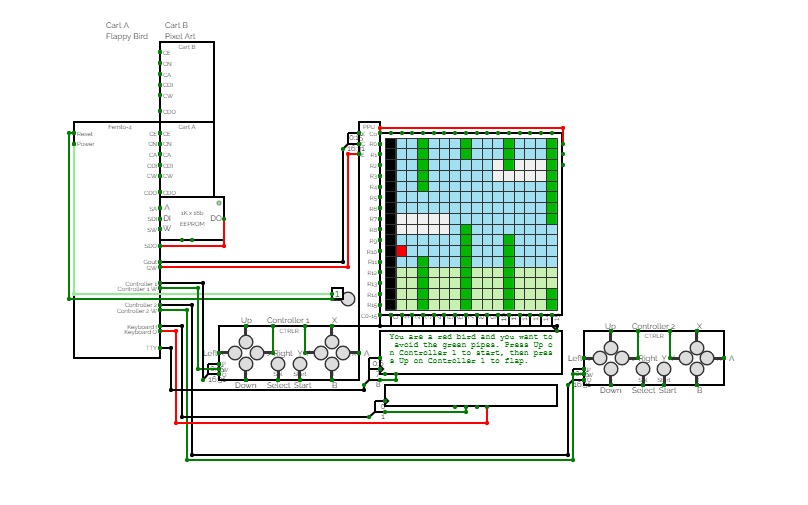
Femto-4v1.1 (Computer)
Femto-4v1.1 (Computer)Latest versions of the 256-Series, including the Femto-4:
https://circuitverse.org/users/4699/projects/256-series
A 16-bit computer/maybe console inspired thing, the Femto-4. This is a fork from the main branch to keep a semi-functional version around. This project was started around November 2020.
Currently runs:
Cart A: Flappy Bird
Cart B: Some Pixel Art
Assembler:
https://repl.it/@Sanderokianstfe/Femto-4-Assembler#DeveloperGuide.txt
Features:
Immediate, direct and indirect memory access
Jumps and conditional Jumps
16-bit address space
Switchable Memory Banks, allowing for a standard Cart to hold up to 512kx16b of data
An ALU capable of logical operators, addition, subtraction and shift left
Easy to add to buses
"Fast Execution" - Can run more than one instruction per clock cycle
16x16 pixel display
Inputs, both "controllers" and keyboards
"Faster Execution" - Runs instructions on both edges of the clock pulse
Random number generator
Text outputs
An ALU capable of shift right, multiplying, dividing, and other specialised functions
Stack
Assembler (written in an external program)
Save memory
One pre-written cart to play with
Updates:
Another pre-written cart
Fixed code controlled graphics updates
Made Bootloader clear TTY, Keyboard, and Controller Pushed
Fixed Register ALU instructions
Updated Cart A and Cart B to make use of the Register ALU instructions
Will have:
More pre-written carts
Bug fixes
Do fork the project and write your own code for it! If you want more information on how to do so read the Developer Guide in the assembler.
Note:
The Flappy Bird high score is mine. If you want to save your own scores permanently you will have to fork it.
General Architecture:
The Femto-4 has variable length instructions that are comprised of multiple 16-bit chunks. First the OP Code of the instruction is read, and then depending on the OP Code, additional pieces of data may be read for the operands. This allows execution to become incorrectly offset, which can lead to the execution of garbage if the PC is jumped to an incorrect address. This is usually fine, since the OP Code space is so empty that the data will likely be passed one at a time until the next valid instruction. Data is read through the standard data retrieval system (which is handy since its design is so universal and easy to add to) making this architecture a Von Neuman architecture as opposed to a Harvard architecture, like my previous, worse, computer. The MAR always specifies the address being read to or written from, whilst the MDR always holds the data being written. Data from the data out bus can be written to any special register during the instruction. OP Codes and operands are all 16-bits, which is a bit wasteful in terms of OP Code usage, however it was easier to implement this way, and so that is what I went with (and there are a lot of ALU processes).
Memory Mapping:
The 16-bit address space of the Femto-4 is memory mapped, with all data being stored somewhere in the address space. The last 48kx16b of memory (all addresses starting with 01, 10, or 11) are dedicated to the cart memory. This is where the interchangeable program would be stored, allowing programs to be easily changed by changing carts. (However, currently there are currently only two carts). The carts have 32 16kx16b EEPROM/RAM chips, which can be switched between during execution by writing to address 00cc. This gives each cart 512kx16b of memory to play with. In theory, additional memory can be added in a cart by creating a similar system on the inside of the cart, which would allow it to swap between even more EEPROM/RAM chips. The initial 16kx16b are therefore mapped to everything else, including a fixed "work" RAM chip that cannot be switched out, the bootloader, the PPU data, general use registers, the, stack, inputs, outputs, and special use registers.
"Fast Execution":
Execution at the fastest clock speed (one pulse every 50ms, or 20Hz) is terribly slow, and would make reasonable graphics effectively impossible. Due to this, the Femto-4 includes several execution modes that allow the computer to run much faster. There are two registers involved in this, address 00ca, the mode register, and address 00cb, the protection register. When the two least significant bits of the mode register are low, the computer runs normally, executing 1 instruction per clock pulse. When it is set high however, the computer enters fast execution on the rising edge, where it executes multiple instructions per clock pulse. This is achieved by looping a rising edge monostable circuit into a falling edge monostable circuit, producing a loop that will pulse indefinitely until the looping line is written high to by some external factor. Stopping the loop is critical since leaving the loop running will stop CircuitVerse's execution, due to it going over the stack limit of the execution. "Fast execution" is always paused by a 0x0000 OP Code, which ensures that the computer will not attempt to "fast execute" memory that has not been written to. It is also paused by the OP Code 0x0001. Setting the 3 bit of the mode register high will enable protection. This will ensure that computer only executes as many instructions as the value in the protection register. This protects execution by ensuring that the loop will always pause before the cycle limit is reached. Since some operations are far more complex than other operations, the maximum number of instructions per clock pulse is variable, and testing should always be conducted to ensure that the limit is not reached. Due to this, for games that need regular graphics updates, it is recommended that protection is not used, and instead the pauses are fully code controlled. Setting the 2nd bit of the mode register high will enable the clock to run fast execution on the falling edge of the clock as well, doubling execution speed. On the other end of the mode register are the graphics mode. The highest two bits give the graphics update mode, 00 for falling edge only (normal speed), 01 for dual edge (double speed), 10 for every other clock pulse (half speed), and 11 for code controlled, where the 0x0001 OP Code is required to update the graphics. The third most significant bit is the graphics disable bit. Setting it high stops updating the graphics. The mode and protection values are only updated on the rising edge of the clock pulse, and therefore there should always be pauses before and after any execution mode or protection change.
Graphics:
The Femto-4 is capable of driving a 16x16 15bit direct colour screen. It has space for 32 "sprites" which are rectangles with an assigned colour. Currently, every time the clock pulses low, the screen is refreshed. When using dual-edge "Faster Execution", the falling edge should only be used to execute game code, since writing graphics data as the screen is being drawn may mess up the graphics. These 32 "sprites" have their data stored in the PPU RAM in the following format: The first 16 bits are the corners of the rectangle, with each coordinate being 4 bits. The coordinates are ordered x1 x2 y1 y2. The next 16 bits are the sprites colour, with the first 15 bits being used for 15 bit direct colour, and the last bit being used to enable or disable drawing the sprite. Since the screen is not wiped every time it is refreshed, the background must be sprite to ensure that the screen is fully wiped before the rest of the sprites are drawn on. Control of this allows carts to draw a single frame over multiple updates, allowing the 32-sprite limit to be bypassed. The "sprites" are drawn in memory order, with the "sprite" with the largest address always being drawn last and therefore on top, of all other "sprites". This is achieved by using the exact same monostable clock system as "Fast Execution", which reads off all the sprite data and draws them to the screen in a single clock pulse. This can loop more times safely than the main CPU since it has less dependencies which dramatically increase the simulation's stack usage.
ALU:
The basic ALU was inspired by the ALU-74LS181. It was designed to flexibly change between various operations by changing an additional piece of data which is bundled in the OP Code. This allows a single ALU to handle all the required processes, such as the basic binary logic operations, shift left, adding, and subtracting. This is unlike my previous computer which had different chips for each operation it could do. The Femto-4 also can multiply, divide, shift right, shift left/right by a specified number of bits, and perform operations designed to work with the Femto-4's graphics data.
Conditional Jumps:
The Femto-4 can perform immediate and direct jumps depending on the flags, a specified bit of the accumulator, and the clock. The flag jumps allow for comparisons to be made. There are three flags, the carry, the most significant bit in the accumulator, and if the accumulator value is 0, the equals flag. By performing A-B, we can compare A and B by looking at the flags. If the equals flag is true, then A=B, since A-B = 0. If the most significant bit is 0, then the number is positive or 0 (by two's complement) and therefore A>=B. The comparison is not entirely correct for numbers in two's complement (a large positive number and a large negative number when subtracted can yield a positive number), but for small values it works well. Whilst we cannot directly check A<=B using A-B in this design, we can simply flip the subtraction to B-A to do so.
The accumulator bit testing is mainly used to check for controller inputs. Since each button in the controller is mapped to one bit, bit testing that bit effectively allows us to check if a button has been pressed. In theory a similar test could be performed using an AND instruction, and checking if the result is equal to 0 or not.
The jump on clock is there to ensure that we can jump execution on the right clock pulse, which ensures that graphics can be updated on the edge of execution.
Timing:
This computer is timed using several standard delay chips. The pulse length running in to the computer is about 10k units long. Therefore, different parts an instruction are separated by 20k unit delays. Further control of timings inside these periods is achieved through 1k "On Delays", which have a 1k delay turning on, but a 0k delay turning off, ensuring that pulses do not bleed into the next pulse. For more information see here: https://circuitverse.org/users/4699/projects/circuitverse-delay-introduction.
Other Notes:
The memory wrappers allow external chips to interact with the main data control system, in this case used for RNG, controllers, the keyboard, and driving the text output.
For more information, please read the developer guide found in the Femto-4's Assembler, or just post a comment and ask me.
This is a secret to everybody, unless you found it.
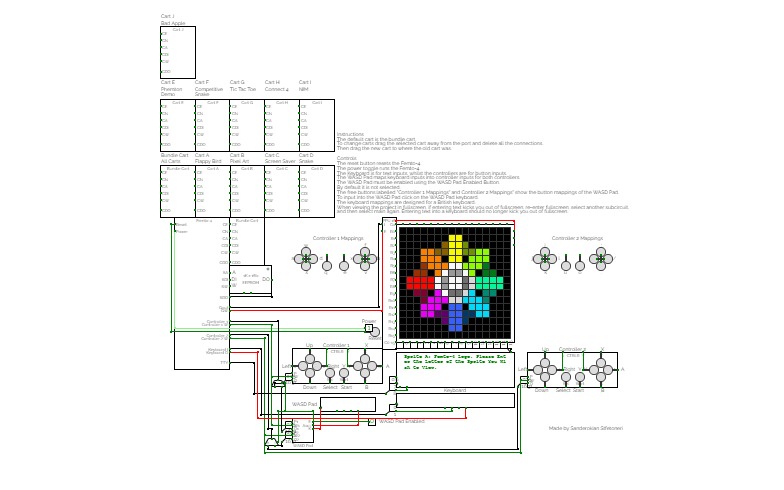
Femto-4v2.6 (Computer)
Femto-4v2.6 (Computer)A 16-bit computer/maybe console inspired thing, the Femto-4. This will be the main branch and backups will be forks from it. This project was started around November 2020.
Currently runs:
- Cart A: Flappy Bird
- Cart B: Some Pixel Art
- Cart C: Screensaver
- Cart D: Snake
- Cart E: Phemton Demonstrations
- Cart F: Competitive Snake
- Cart G: Tic Tac Toe
- Cart H: Connect 4
- Cart I: NIM
- Cart J: Bad Apple
- Bundle Cart: All carts in one
- Cart 2A: 32x32 Snake
- Cart 2B: 32x32 Competitive Snake
- Cart 2C: 32x32 Pixel Art
- Cart 2D: 32x32 Bad Apple
- Bundle Cart 2: All 32x32 carts in one
Assembler:
Compiler:
- https://github.com/Comerstar/PhemtonCompiler/blob/main/PhemtonLiteCompiler/PhemtonDeveloperGuide.txt
The 256-Series:
Full screen Notes:
For some reason, the Femto-4v2.6 only is having issues around caching previous subcircuits. Should you need to use something to unbind key entries from the full screen button, toggle the clock. Previous versions are completely unaffected.
Cart Notes:
Cart A:
- The first cart written for the Femto-4.
Cart B:
- The sprites in the cart are:
- A: Femto-4 Logo.
- B: Madeline from Celeste.
- C: Madeline from Celeste (again).
- D: Part of you aka Badeline from Celeste.
- E: A strawberry from Celeste.
- F: Standing Mario from Super Mario Bros.
- G: Jumping Mario from Super Mario Bros.
- H: Standing Mario from Super Mario Bros 3.
- I: Running Mario from Super Mario Bros 3.
- J: Sanderokian (my own character).
Cart C:
- Enter anything into the keyboard to randomise the colours.
- Enter r into the keyboard to reset the colours.
Cart D:
- WASD Pad is recommended.
- Game settings (enter the letter before starting the game to use the setting):
- e: toggle whether crashing into the edges results in a game over.
- The two modes (with/without edge collisions) have two separate high scores.
- w: change the snake's colour scheme to white.
- r: change the snake's colour scheme to red.
- y: change the snake's colour scheme to yellow.
- o: change the snake's colour scheme to orange.
- p: change the snake's colour scheme to purple.
- a: change the snake's colour scheme to aqua.
- g: change the snake's colour scheme to green.
- b: change the snake's colour scheme to blue.
- m: change the snake's colour scheme to magenta.
- 1: change the snake's colour scheme to pink.
- 2: change the snake's colour scheme to light blue.
- 3: change the snake's colour scheme to the challenge colour scheme with an invisible body.
- 0: randomise the snake's colour scheme.
Cart E:
- The test codes in the cart are:
- 1: Hello World.
- 2: Single Operator Calculator.
- 3: Exponentiation Calculator.
- 4: Fibonacci Calculator.
- 5: Keyboard to TTY Test.
- 6: Keyboard to TTY LDI LID Test.
- 7: Keyboard to TTY LII Test.
- 8: Keyboard to TTY LIA Test.
Cart F:
- WASD Pad is essentially required.
- Game settings (enter the letter before starting the game to use the setting):
- e: toggle whether crashing into the edges results in a game over.
- w: toggle whether the number of wins each player has is tracked.
- s: toggle whether the total score each player has scored is tracked.
- d: display the total wins and total scored.
- r: reset the tracked statistics.
Cart G:
- The small light in the corner indicates which player's turn it is.
- When it is dimmed, it means that the computer is processing that player's turn.
- Game settings (enter the letter before starting the game to use the setting):
- w: toggle whether the number of wins each player has is tracked.
- s: toggle automatic start player swapping. d: display the wins each player has.
- r: reset the wins each player has.
Cart H:
- The bar at the top indicates which player's turn it is.
- When it is dimmed, it means that the computer is processing that player's turn.
- Game settings (enter the letter before starting the game to use the setting):
- w: toggle whether the number of wins each player has is tracked.
- s: toggle automatic start player swapping.
- d: display the wins each player has.
- r: reset the wins each player has.
Cart I:
- Game settings (enter the letter before starting the game to use the setting):
- w: toggle whether the number of wins each player has is tracked.
- s: toggle automatic start player swapping.
- d: display the wins each player has.
- r: reset the wins each player has.
- i: display the game instructions.
- c: toggle the whether player 2 is played by the computer.
Cart J:
- Plays Bad Apple
- There are no further controls
Cart 2A:
- The options are the same as Cart D.
Cart 2B:
- The options are the same as Cart F.
Cart 2C:
- The sprites in the cart are:
- A: Femto-4 Logo.
- B: Sanderokian (my own character).
- C: Alstran (my own character).
Cart 2D:
- Plays Bad Apple on the larger screen
- There are no further controls
Features:
- Immediate, direct, & indirect memory access.
- Jumps & conditional jumps.
- 16-bit address space.
- Switchable memory banks, allowing for a standard cart to hold up to 1MB of data.
- An ALU capable of logical operators, addition, subtraction, shift left, shift right, multiplying, dividing, & other specialised functions.
- Fast execution - can run more than one instruction per clock cycle.
- 16x16 pixel display with 32 sprites and 15-bit direct colour.
- 32x32 pixel display with 32 sprites which can have up to 18-bit direct colour.
- Two controllers, a keyboard mapping for the controllers, & a keyboard for text inputs.
- RNG, TTY, stack, & save memory.
- Von Neumann Architecture.
- Assembler & compiler (written in Python).
- Twelve pre-written carts to play with.
Updates:
v1.0:
- Finished the project and added Cart A.
v1.1:
- Added Cart B, some Pixel Art.
- Fixed GRF, & AXR instructions.
- Made Bootloader clear TTY, Keyboard, & Controller Pushed.
- Updated Cart A & Cart B to make use of AXR instructions.
v1.2:
- Added Cart C, a Screensaver.
- Updated Cart B to respond to the start button on both controllers.
v1.3:
- Added Cart D, Snake.
- Moved to new project to fix issues around searching for projects branched from private projects.
- Removed unnecessary EEPROM banks and write lines from all carts.
- Made Reset clear WRAM and the General Registers.
v1.4:
- Fixed Keyboard.
- Added a Bundle Cart that allows you to view all the carts without changing carts (you must reset the console to view another cart).
- Fixed bug in the standard bank design which wrote data to incorrect addresses.
- Fixed contention issue in Mult.
- Added Annotations to the In Debug.
v1.5:
- Added Snake Player.
- Added Reset & Power labels to the relevant buttons.
v2.0:
- Further optimisation to reduce lag/increase execution speed.
- Added more memory access options.
v2.1:
- Further optimisation of the CU.
- Added a keyboard to controller mapping.
v2.2:
- Continued optimisation and overhaul of the CU.
- Removed old CU & compare circuits.
- Added additional stack access instructions.
- Updated the debug versions with the changes, as well as fixing bugs in the debug versions.
- Designed a Logo for the Femto-4.
- Rewrote Cart C to allow the sprites to be viewed in any order, and added the logo to it.
v2.3:
- Introducing Phemton Lite, the first version of the Femto-4's high level languages.
- Added a link to Phemton Lite's compiler.
- Added Cart E to demonstrate code written in Phemton Lite.
- Combined SpecialD & ROMD1, and removed SpecialD & ROMDB.
- Updated Snake code & Bundle code to match the new addresses.
- Added Cart F, a competitive version of Snake.
- Added an additional sprite into Cart B.
- Fixed issues with LII, LXA & LXP instructions.
v2.4:
- Fixed alignment of the upper carts.
- Added Cart G & Cart H, Tic Tac Toe & Connect 4 written in Phemton Lite.
- Added progress lights to Cart G & Cart H.
- Reworked bundle cart to make the code shorter and more efficient for large numbers of carts.
- Made Cart G & Cart H faster.
- Reshuffled Cart E test codes and added 2 Cart E test codes, exponentiation & Fibonacci calculation.
- Added game options to Cart D, Cart F, Cart G, & Cart H.
- Updated Cart C to allow the colours to be randomised.
- Added optional colour schemes for Cart D.
- Fixed Snake Player.
- Remade the multiply and divide circuits to take advantage of the inbuilt adders.
- Removed old MultM and DivM circuits.
v2.5:
- Further optimisation of the CU.
- Optimisation of the fast execution clocks for the computer, the graphics, & the WASD Pad.
- Fixed debug versions' issues with Phemton conditionals and added optimisations to the debug versions.
- Added 32x32 screen PPU.
- Added Cart 2A, Cart 2B, & Cart 2C, 32x32 versions of Snake, Competitive Snake, & Pixel Art.
- Added Cart I, NIM written in Phemton Lite.
v2.6
- Added the ability to directly write sprites to the PPU during execution.
- Significantly optimised the CU by removing unnecessary subcircuits.
- Introduced significant quantities of lazy evaluation to further improve performance.
- Added Cart J, and Cart 2D, which both play Bad Apple.
- The Femto-4 can now be added to the set of things that plays Bad Apple.
Future Updates:
- More pre-written carts.
- Bug fixes.
- Adding an optimiser to the compiler.
- Phemton Full.
- Phemton Plus.
Do fork the project and write your own code for it! If you want more information on how to do so read the Developer Guide in the assembler.
Note: The Flappy Bird high score and the Snake high score are mine. If you want to save your own scores permanently you will have to fork the project.
The Femto-4

General Architecture: The Femto-4 is a 16-bit, Von Neumann architecture computer with variable length instructions that are comprised of multiple 16-bit words. It has many features associated with CISCs, such as variable length instructions, and multicycle indirect loads, however operates like a RISC, with each instruction taking exactly 1 clock cycle. This was done to give the Femto-4 power whilst keeping its construction simple. First the OP code of the instruction is read, and then depending on the OP code, additional pieces of data may be read for the operands. This allows execution to become incorrectly offset, which can lead to the execution of garbage if the PC is jumped to an incorrect address. This is usually fine, since the OP code space is so empty that the data will likely be passed one at a time until the next valid instruction. Instructions are read from main memory, making this architecture a Von Neumann architecture as opposed to a Harvard architecture. The MAR always specifies the address being read to or written from, whilst the MDR always holds the data being written. Data from the data out bus can be written to most special registers during the instruction. OP codes and operands are all 16-bits. The large OP code size was chosen due to the high number of ALU instructions. There are approximately 500 interpretable OP codes that the computer can handle.
Memory Mapping: The 16-bit address space of the Femto-4 is memory mapped, with all data being stored somewhere in the address space. The last 48kx16b of memory (all addresses starting with 0b01, 0b10, or 0b11) are dedicated to the cart memory. This is where the interchangeable program would be stored, allowing programs to be easily changed by changing carts. The carts have 32 16kx16b EEPROM/RAM chips, which can be switched between during execution by writing to address 0x00cc. This gives each cart 512kx16b of memory to play with. In theory, additional memory can be added in a cart by creating a similar system on the inside of the cart, which would allow it to swap between even more EEPROM/RAM chips. The initial 16kx16b are therefore mapped to everything else, including a fixed WRAM chip that cannot be switched out, the bootloader, the PPU data, general registers, the stack, inputs, outputs, and a few special registers, such as the protect, mode, and flag registers.
Fast Execution: Execution at the fastest clock speed (one pulse every 100ms, or 10Hz, which is defined as the clock changing state every 50ms, or at a rate of 20Hz) is terribly slow, and would make reasonable graphics effectively impossible. Due to this, the Femto-4 includes several execution modes that allow the computer to run much faster. There are two registers involved in this, address 0x00ca, the mode register, and address 0x00cb, the protect register. When the two least significant bits of the mode register are low, the computer runs normally, executing 1 instruction per clock pulse. When bit 0 is set high, the computer enters fast execution on the rising edge, where it executes multiple instructions per clock pulse. This is achieved by looping an inverter into itself, producing a loop that will pulse indefinitely until the looping line is stopped by some external factor. Stopping the loop is critical since leaving the loop running will stop CircuitVerse's execution, due to it going over the stack limit of the execution. Fast execution is always paused by a 0x0000 and 0x0001 OP Code. Bit 2 enables falling edge fast execution, which can be done with rising edge fast execution producing dual edge fast execution. Setting the third bit of the mode register high will enable protection. This will ensure that computer only executes as many instructions as the value in the protect register. This protects execution by ensuring that the loop will always pause before the cycle limit is reached. Since some operations are far more complex than other operations, the maximum number of instructions per clock pulse is variable, and testing should always be conducted to ensure that the limit is not reached. Due to this, for games that need regular graphics updates, it is recommended that protection is not used, and instead the pauses are fully code controlled. On the other end of the mode register are the graphics mode. The highest two bits give the graphics update mode, 0b00 for falling edge only (normal speed), 0b01 for dual edge (double speed), 0b10 for every other clock pulse (half speed), and 0b11 for code controlled, where the 0x0001OP Code is required to update the graphics. The third most significant bit is the graphics disable bit. Setting it high stops updating the graphics, reducing lag by prevent the graphics fast execution loop from running. The mode and protection values are only updated on the rising edge of the clock pulse, and therefore there should always be pauses before and after any execution mode or protection change. By default, the Femto-4 executes with a protection value of 16, to allow the carts to run smoothly, however, depending on the instructions being used, that number can be raised to 64.
Graphics (16x16): The Femto-4 is capable of driving a 16x16 15-bit direct colour screen. It has space for 32 sprites which are rectangles with an assigned colour. All the sprites are drawn to the screen whenever a graphics update occurs, depending on the graphics mode. When using dual-edge fast execution, the falling edge should only be used to execute game code, since writing graphics data as the screen is being drawn may mess up the graphics. These 32 sprites have their data stored in the PPU RAM in the following format: The first 16 bits are the corners of the rectangle, with each coordinate being 4 bits. The coordinates are ordered x coordinate 1 (4), x coordinate 2 (4), y coordinate 1 (4), y coordinate 2 (4). The second coordinates are offset up by 1, to allow the full screen to be drawn to, such that the dimensions of the rectangle are (x2 - x1) + 1 and (y2 - y1) + 1. The next 16 bits are the sprites colour, with the first 15 bits being used for 15-bit direct colour, and the last bit being used to enable or disable drawing the sprite. The last bit is important to ensure that blank sprites are not drawn to the screen. Since the screen is not wiped every time it is refreshed, the background must be a sprite to ensure that the screen is fully wiped before the rest of the sprites are drawn on. Control of this allows carts to draw a single frame over multiple updates, allowing the 32-sprite limit to be bypassed (see how Snake works). The sprites are drawn in memory order, with the sprite with the largest address always being drawn last and therefore on top, of all other sprites. This is achieved by using the exact same system as fast execution, which reads off all the sprite data and draws them to the screen in a single clock pulse. This can loop more times safely than the main CPU since it has less dependencies which dramatically decreases the simulation's stack usage.
Graphics (32x32): The Femto-4 can also drive a 32x32 screen, with sprites able to be drawn through 3 different modes. The 32x32 screen PPU treats the addresses as one combined 32-bit value, with the value with the smaller address going first. The first 3 bits of the 32 bits define the mode. Only the values 1, 2, 3, correspond to actual sprites, whilst the rest are not drawn to the screen. Mode 1 splits the remaining 29-bit space as the following: unused (1), x coordinate (5), y coordinate (5), red (6), green (6), blue (6). Mode 2 splits the 29-bit space in the following way: x coordinate 1 (5), x coordinate 2 (5), y coordinate 1 (5), y coordinate 2 (5), red (3), green (3), blue (3). Mode 3 splits the 29-bit space in the following way: unused (3), x coordinate (5), y coordinate (5), red (5), green (5), blue (5), alpha/transparency (1). As with the 16x16 screen, Mode 2's second coordinates are offset by 1 resulting in rectangles having the dimensions of (x1 - x2) + 1 and (y1 - y2) + 1. Mode 3 is designed to allow the colours used in the 16x16 screen to be the same, making converting code between the two versions easier. The update mechanism is the same as 16x16 screen.
ALU: The basic ALU was inspired by the ALU-74LS181. It was designed to flexibly change between various operations by changing an additional piece of data which is bundled in the OP code. This allows a single ALU to handle all the required processes, such as the basic binary logic operations, shift left, adding, and subtracting, reducing the number of circuits required, as well as the logic required to decide which instruction to use. The Femto-4 also can multiply, divide, shift right, shift left/right by a specified number of bits, and perform operations designed to work with the computer's graphics data.
Conditional Jumps: The Femto-4 can perform immediate and direct jumps depending on the flags, a specified bit of the accumulator, and the clock. The flag jumps allow for comparisons to be made. There are three flags, the carry, the most significant bit in the accumulator, and if the accumulator value is 0, the equals flag. By performing A-B, we can compare A and B by looking at the flags. If the equals flag is true, then A=B, since A-B = 0. If the most significant bit is 0, then the number is positive or 0 (by two's complement) and therefore A>=B. The comparison is not entirely correct for numbers in two's complement (a large positive number and a large negative number when subtracted can yield a positive number), but for small values it works well. Whilst we cannot directly check A<=B using A-B in this design, we can simply flip the subtraction to B-A to do so. The accumulator bit testing is mainly used to check for controller inputs. Since each button in the controller is mapped to one bit, bit testing that bit effectively allows us to check if a button has been pressed. A similar test could be performed using an AND instruction, and checking if the result is equal to 0 or not. Bit testing is most useful for testing an input from both controllers, since it can cut out an additional instruction. The jump on clock is there to ensure that we can jump execution on the right clock pulse, which ensures that graphics can be updated on the edge of execution.
Timing: The computer is timed using several standard delay chips. The pulse length running in to the computer is about 10k units long. Therefore, different parts an instruction are separated by 20k unit delays. Further control of timings inside these periods is achieved through 1k "On Delays", which have a 1k delay turning on, but a 0k delay turning off, ensuring that pulses do not bleed into the next pulse. These pulses can tell registers to write and what source to write from, enable the read and write lines, update the ALU, and update the stack Each instruction is separate by 600k of delay in fast execution. For more information on how delay works see here: https://circuitverse.org/users/4699/projects/circuitverse-delay-introduction.
Keyboard Mapping: The Femto-4's keyboard controller mapping was created using a specialised chip. This chip used the fast execution loop to take 15 inputs from a keyboard and map the inputs to button presses on the controllers. Since the buttons are updated several times in a clock pulse, the keyboard controller cannot handle held buttons. The keyboard mapping is designed to work with both controllers, allowing two player games to be feasible on the computer.
Assembly: The Femto-4 has an assembler that converts assembly written in a .txt into hex values in a .txt that can be copied and loaded into the EEPROM banks for storage. The assembler can handle symbol assignment, as well as assigning addresses in the code symbols to make handling jumps easier. For full details on the Femto-4's assembly language view the assembly developer guide.
Phemton: Phemton is the Femto-4's high level language, with a compiler to compile it's code into Femto-4 assembly. Phemton handles variable memory assignment, basic array assignment, if, elif, else statments, while loops, for loops, and functions. Phemton Lite is the only compiler complete, and lacks an optimiser. Phemton Lite has the concept of local scope only when compiling. All uniquely identified variables are given a global address. This reduces the runtime load since the computer does not need to decide where the variables need to go during run time. Future planned additions include generated code optimisations and optimisers, Phemton Full, which has dynamic memory assignment, and Phemton Plus, which adds additional types for floats and longs. For more details view Phemton's developer guide.
Other Notes: The memory wrappers allow external chips to interact with the main data control system, in this case used for RNG, controllers, the keyboard, and driving the text output. This makes it easy to additional chips to the computer. All assembly and Phemton code can be found in the project for the Femto-4's assembler and compiler respectively. The save data cart must be located outside of the Femto-4 circuit to ensure that its contents are automatically saved. Sorry about all the copies of this computer clogging up the top of the search results.
For more information, please read the developer guide found in the Femto-4's Assembler, or just post a comment and ask me.
This is a secret to everybody, unless you found it.
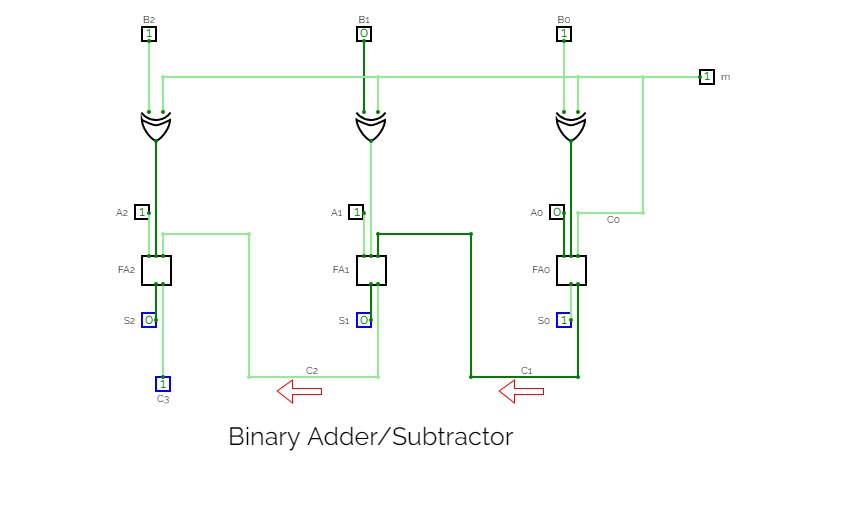

Binary Adder/Subtractor
Binary Adder/SubtractorImplement 3-bit parallel Binary Adder/Subtractor.

Carry-Lookahead Adder
Carry-Lookahead Adder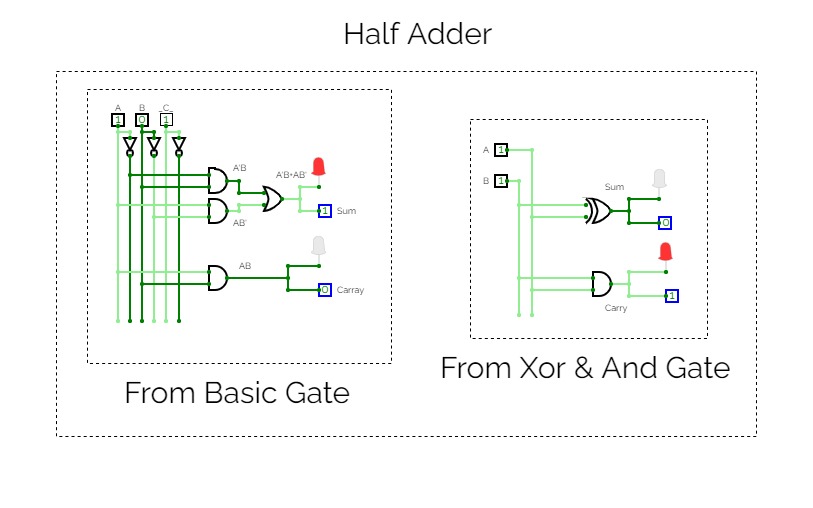

Adder: Half and Full Adder
Adder: Half and Full Adder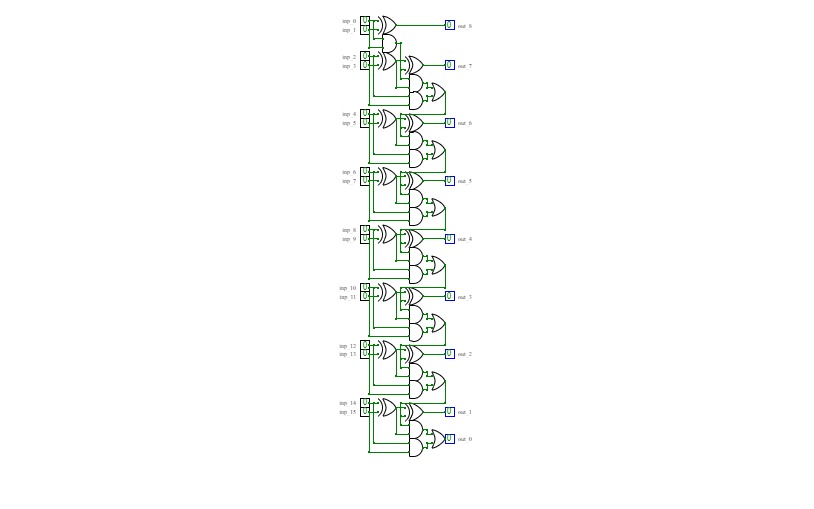
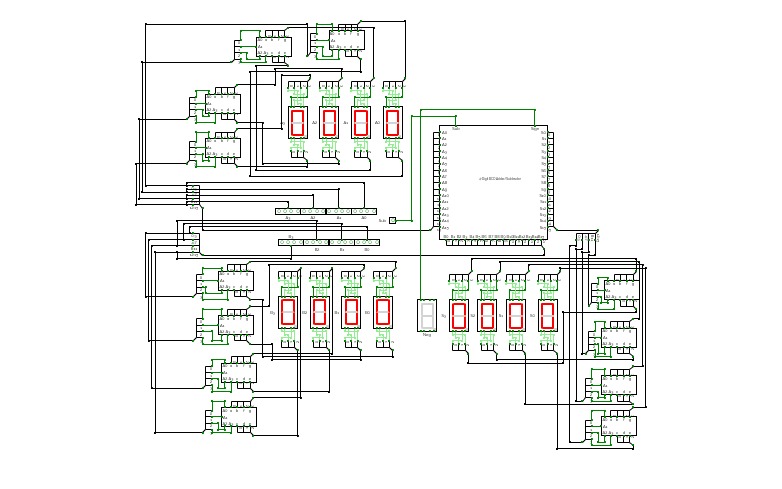
BCD Adder
BCD Adder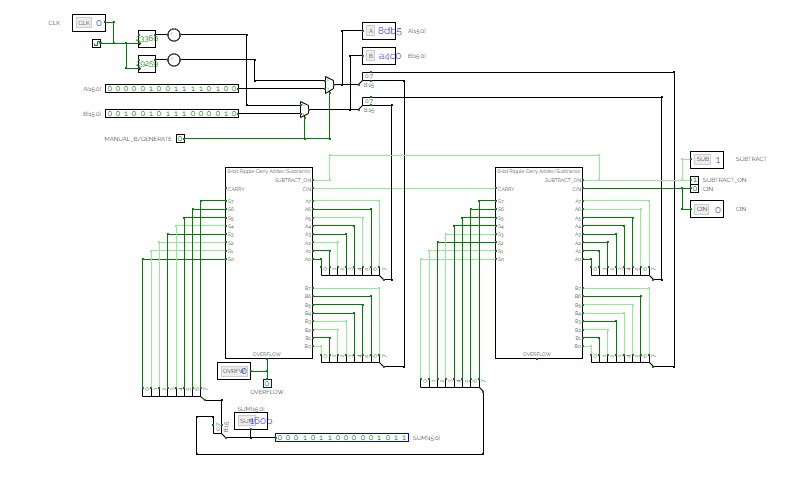

Adder
Adder
project
project
project
project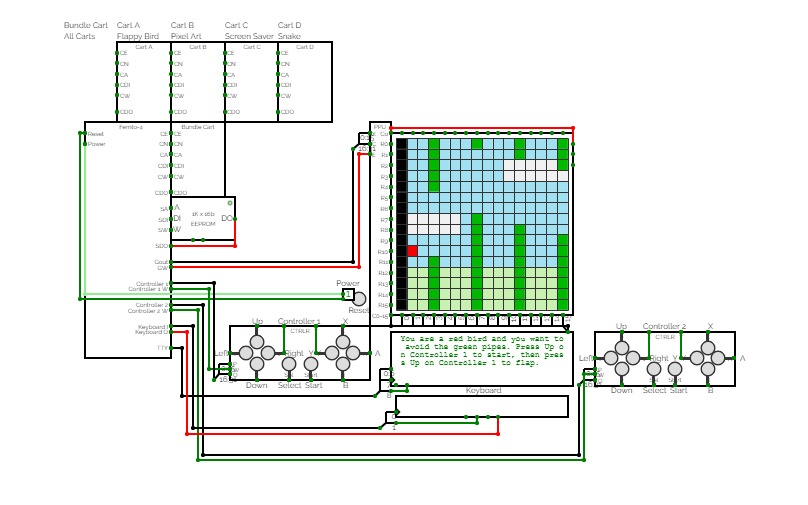
Femto-4v1.5 (Computer)
Femto-4v1.5 (Computer)Latest versions of the 256-Series, including the Femto-4:
https://circuitverse.org/users/4699/projects/256-series
A 16-bit computer/maybe console inspired thing, the Femto-4. This is a branch to keep a functional version around. This project was started around November 2020.
Currently runs:
Cart A: Flappy Bird
Cart B: Some Pixel Art
Cart C: Screensaver
Cart D: Snake
Bundle Cart: All carts in one
Assembler:
https://repl.it/@Sanderokianstfe/Femto-4-Assembler#DeveloperGuide.txt
Features:
Immediate, direct and indirect memory access
Jumps and conditional Jumps
16-bit address space
Switchable Memory Banks, allowing for a standard cart to hold up to 512kx16b of data
An ALU capable of logical operators, addition, subtraction, shift left, shift right, multiplying, dividing, and other specialised functions
Easy to add to buses
"Fast Execution" - Can run more than one instruction per clock cycle
"Faster Execution" - Runs instructions on both edges of the clock pulse
16x16 pixel display with 32 "Sprites" and 15-bit direct colour
Inputs, both "controllers" and keyboards
Random number generator
Text outputs
Stack
Von Neumann Architecture
Assembler (written in an external program)
Save memory
Four pre-written carts to play with
Previous Updates:
Fixed code controlled graphics updates
Made Bootloader clear TTY, Keyboard, and Controller Pushed
Fixed Register ALU instructions
Updated Cart A and Cart B to make use of the Register ALU instructions
Updated the Cart B to respond to the start button on both controllers
Moved to new project to fix issues around searching for projects branched from private projects
Removed unnecessary EEPROM banks from all carts
Removed unnecessary write lines leading to EEPROMs in carts, preventing code from being overwritten during execution
Made Reset clear WRAM and the General Registers
Fixed Keyboard
Added a Bundle Cart that allows you to view all the carts I have made without changing carts (you must reset the console to view another cart)
Fixed bug in standard bank design which wrote data to incorrect addresses
Fixed contention issue with multiplying
Added Annotations to the In Debug
Updates:
Added Snake Player
Added Reset and Power Labels to the relevant buttons
Will have:
More pre-written carts
Bug fixes
Do fork the project and write your own code for it! If you want more information on how to do so read the Developer Guide in the assembler.
Note:
The Flappy Bird high score and the Snake high score are mine. If you want to save your own scores permanently you will have to fork the project.
General Architecture:
The Femto-4 is a 16-bit computer with variable length instructions that are comprised of multiple 16-bit words. First the OP Code of the instruction is read, and then depending on the OP Code, additional pieces of data may be read for the operands. This allows execution to become incorrectly offset, which can lead to the execution of garbage if the PC is jumped to an incorrect address. This is usually fine, since the OP Code space is so empty that the data will likely be passed one at a time until the next valid instruction. Data is read through the standard data retrieval system (which is handy since its design is so universal and easy to add to) making this architecture a Von Neumann architecture as opposed to a Harvard architecture, like my previous, worse, computer. The MAR always specifies the address being read to or written from, whilst the MDR always holds the data being written. Data from the data out bus can be written to any special register during the instruction. OP Codes and operands are all 16-bits, which is a bit wasteful in terms of OP Code usage, however it was easier to implement this way, and so that is what I went with (and there are a lot of ALU processes).
Memory Mapping:
The 16-bit address space of the Femto-4 is memory mapped, with all data being stored somewhere in the address space. The last 48kx16b of memory (all addresses starting with 01, 10, or 11) are dedicated to the cart memory. This is where the interchangeable program would be stored, allowing programs to be easily changed by changing carts. The carts have 32 16kx16b EEPROM/RAM chips, which can be switched between during execution by writing to address 00cc. This gives each cart 512kx16b of memory to play with. In theory, additional memory can be added in a cart by creating a similar system on the inside of the cart, which would allow it to swap between even more EEPROM/RAM chips. The initial 16kx16b are therefore mapped to everything else, including a fixed "work" RAM chip that cannot be switched out, the bootloader, the PPU data, general use registers, the, stack, inputs, outputs, and special use registers.
"Fast Execution":
Execution at the fastest clock speed (one pulse every 100ms, or 10Hz, which is defined as the clock changing state every 50ms, or at a rate of 20Hz) is terribly slow, and would make reasonable graphics effectively impossible. Due to this, the Femto-4 includes several execution modes that allow the computer to run much faster. There are two registers involved in this, address 00ca, the mode register, and address 00cb, the protection register. When the two least significant bits of the mode register are low, the computer runs normally, executing 1 instruction per clock pulse. When it is set high however, the computer enters fast execution on the rising edge, where it executes multiple instructions per clock pulse. This is achieved by looping a rising edge monostable circuit into a falling edge monostable circuit, producing a loop that will pulse indefinitely until the looping line is written high to by some external factor. Stopping the loop is critical since leaving the loop running will stop CircuitVerse's execution, due to it going over the stack limit of the execution. "Fast execution" is always paused by a 0x0000 OP Code, which ensures that the computer will not attempt to "fast execute" memory that has not been written to. It is also paused by the OP Code 0x0001. Setting the 3 bit of the mode register high will enable protection. This will ensure that computer only executes as many instructions as the value in the protection register. This protects execution by ensuring that the loop will always pause before the cycle limit is reached. Since some operations are far more complex than other operations, the maximum number of instructions per clock pulse is variable, and testing should always be conducted to ensure that the limit is not reached. Due to this, for games that need regular graphics updates, it is recommended that protection is not used, and instead the pauses are fully code controlled. Setting the 2nd bit of the mode register high will enable the clock to run fast execution on the falling edge of the clock as well, doubling execution speed. On the other end of the mode register are the graphics mode. The highest two bits give the graphics update mode, 00 for falling edge only (normal speed), 01 for dual edge (double speed), 10 for every other clock pulse (half speed), and 11 for code controlled, where the 0x0001 OP Code is required to update the graphics. The third most significant bit is the graphics disable bit. Setting it high stops updating the graphics, reducing lag by reducing the number of changing outputs. The mode and protection values are only updated on the rising edge of the clock pulse, and therefore there should always be pauses before and after any execution mode or protection change.
Graphics:
The Femto-4 is capable of driving a 16x16 15bit direct colour screen. It has space for 32 "sprites" which are rectangles with an assigned colour. All the sprites are drawn to the screen whenever a graphics update occurs, depending on the graphics mode. When using dual-edge "Faster Execution", the falling edge should only be used to execute game code, since writing graphics data as the screen is being drawn may mess up the graphics. These 32 "sprites" have their data stored in the PPU RAM in the following format: The first 16 bits are the corners of the rectangle, with each coordinate being 4 bits. The coordinates are ordered x1 x2 y1 y2. The next 16 bits are the sprites colour, with the first 15 bits being used for 15 bit direct colour, and the last bit being used to enable or disable drawing the sprite. Since the screen is not wiped every time it is refreshed, the background must be a sprite to ensure that the screen is fully wiped before the rest of the sprites are drawn on. Control of this allows carts to draw a single frame over multiple updates, allowing the 32-sprite limit to be bypassed (see how Snake works). The "sprites" are drawn in memory order, with the "sprite" with the largest address always being drawn last and therefore on top, of all other "sprites". This is achieved by using the exact same monostable clock system as "Fast Execution", which reads off all the sprite data and draws them to the screen in a single clock pulse. This can loop more times safely than the main CPU since it has less dependencies which dramatically decreases the simulation's stack usage.
ALU:
The basic ALU was inspired by the ALU-74LS181. It was designed to flexibly change between various operations by changing an additional piece of data which is bundled in the OP Code. This allows a single ALU to handle all the required processes, such as the basic binary logic operations, shift left, adding, and subtracting. This is unlike my previous computer which had different chips for each operation it could do. The Femto-4 also can multiply, divide, shift right, shift left/right by a specified number of bits, and perform operations designed to work with the Femto-4's graphics data.
Conditional Jumps:
The Femto-4 can perform immediate and direct jumps depending on the flags, a specified bit of the accumulator, and the clock. The flag jumps allow for comparisons to be made. There are three flags, the carry, the most significant bit in the accumulator, and if the accumulator value is 0, the equals flag. By performing A-B, we can compare A and B by looking at the flags. If the equals flag is true, then A=B, since A-B = 0. If the most significant bit is 0, then the number is positive or 0 (by two's complement) and therefore A>=B. The comparison is not entirely correct for numbers in two's complement (a large positive number and a large negative number when subtracted can yield a positive number), but for small values it works well. Whilst we cannot directly check A<=B using A-B in this design, we can simply flip the subtraction to B-A to do so.
The accumulator bit testing is mainly used to check for controller inputs. Since each button in the controller is mapped to one bit, bit testing that bit effectively allows us to check if a button has been pressed. In theory a similar test could be performed using an AND instruction, and checking if the result is equal to 0 or not.
The jump on clock is there to ensure that we can jump execution on the right clock pulse, which ensures that graphics can be updated on the edge of execution.
Timing:
This computer is timed using several standard delay chips. The pulse length running in to the computer is about 10k units long. Therefore, different parts an instruction are separated by 20k unit delays. Further control of timings inside these periods is achieved through 1k "On Delays", which have a 1k delay turning on, but a 0k delay turning off, ensuring that pulses do not bleed into the next pulse. These pulses can tell registers to write and what source to write from, enable the read and write lines, update the ALU, and update the stack. For more information on how delay works see here: https://circuitverse.org/users/4699/projects/circuitverse-delay-introduction.
Other Notes:
The memory wrappers allow external chips to interact with the main data control system, in this case used for RNG, controllers, the keyboard, and driving the text output. This makes it easy to additional chips to the computer.
For more information, please read the developer guide found in the Femto-4's Assembler, or just post a comment and ask me.
This is a secret to everybody, unless you found it.
Computer Add Auto
Computer Add AutoA Computer. Kind of.
The 256-Series, my new collection of simulated computers: https://circuitverse.org/users/4699/projects/256-series
This version is setup to demonstrate a program that adds two numbers together. This version has been specifically modified to make demonstrating the program easier. This was done by making operand A for the first two instructions depend on user input, which allows the user to easily test the program with different values.
The code is as follows:
00: LOAD Input A into Address 00
01: LOAD Input B into Address 01
02: ADD Addresses 00 and 01
03: LOAD ADD Result into 02
04: RETURN Address 02
Features:
32-Bits of 5-bit RAM,
32 Lines for Instructions,
ADD, AND and XOR Functions.
Go To Functionality
Can do IF = Statements
OP Codes:
0000 = Nothing
0001 VVVVV AAAAA = LOAD VVVVV into address AAAAA
0010 AAAAA 00000 = LOAD Add result into address AAAAA
0011 DDDDD VVVVV = ADD DDDDD and VVVVV together
0100 AAAAA BBBBB = ADD address AAAAA and address BBBBB together
0101 DDDDD VVVVV = AND DDDDD and VVVVV together
0110 AAAAA BBBBB = AND address AAAAA and address BBBBB together
0111 DDDDD VVVVV = XOR DDDDD and VVVVV together
1000 AAAAA BBBBB = XOR address AAAAA and BBBBB together
1001 AAAAA 00000 = LOAD AND result into address AAAAA
1010 AAAAA 00000 = LOAD XOR result into address AAAAA
1011 AAAAA 00000 = GOTO address AAAAA (in instruction memory)
1100 AAAAA BBBBB = If add result = 0 (ignoring carry), GOTO address AAAAA else go to address BBBBB (in instruction memory)
1101 VVVVV 00000 = Return VVVVV (Stops the program)
1110 AAAAA 00000 = Return the value at address AAAAA (Stops the program)
1111 = Nothing

Full Adder
Full AdderFull Adder made from NOT and OR gates
Contrary to popular belief, Lorem Ipsum is not simply random text. It has roots in a piece of classical Latin literature from 45 BC, making it over 2000 years old. Richard McClintock, a Latin professor at Hampden-Sydney College in Virginia, looked up one of the more obscure Latin words, consectetur, from a Lorem Ipsum passage, and going through the cites of the word in classical literature, discovered the undoubtable source. Lorem Ipsum comes from sections 1.10.32 and 1.10.33 of "de Finibus Bonorum et Malorum" (The Extremes of Good and Evil) by Cicero, written in 45 BC. This book is a treatise on the theory of ethics, very popular during the Renaissance. The first line of Lorem Ipsum, "Lorem ipsum dolor sit amet..", comes from a line in section 1.10.32.
Contrary to popular belief, Lorem Ipsum is not simply random text. It has roots in a piece of classical Latin literature from 45 BC, making it over 2000 years old. Richard McClintock, a Latin professor at Hampden-Sydney College in Virginia, looked up one of the more obscure Latin words, consectetur, from a Lorem Ipsum passage, and going through the cites of the word in classical literature, discovered the undoubtable source. Lorem Ipsum comes from sections 1.10.32 and 1.10.33 of "de Finibus Bonorum et Malorum" (The Extremes of Good and Evil) by Cicero, written in 45 BC. This book is a treatise on the theory of ethics, very popular during the Renaissance. The first line of Lorem Ipsum, "Lorem ipsum dolor sit amet..", comes from a line in section 1.10.32.
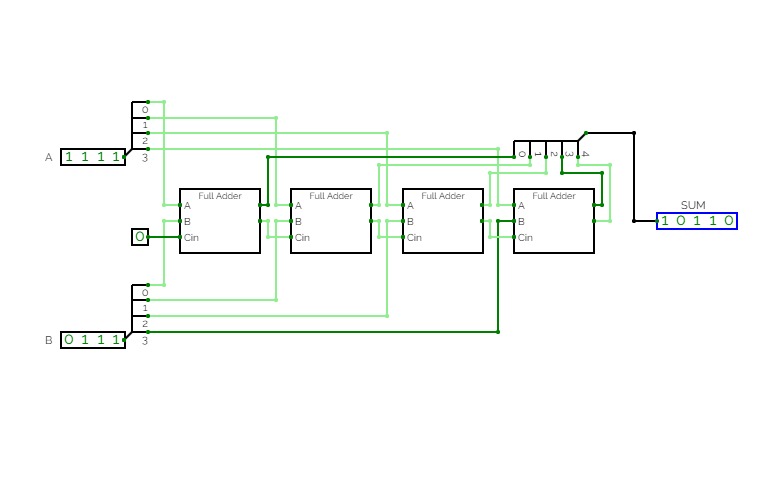

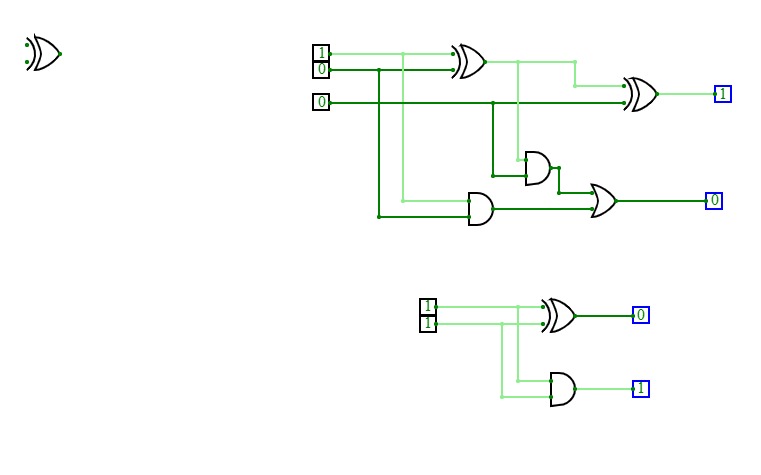
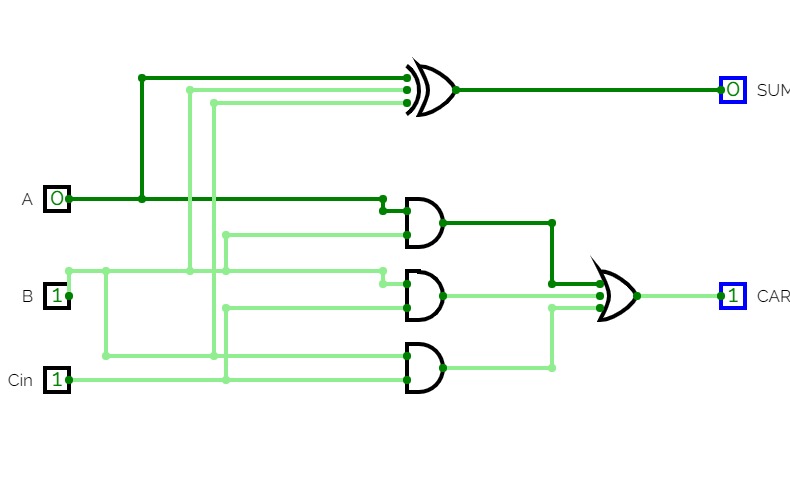
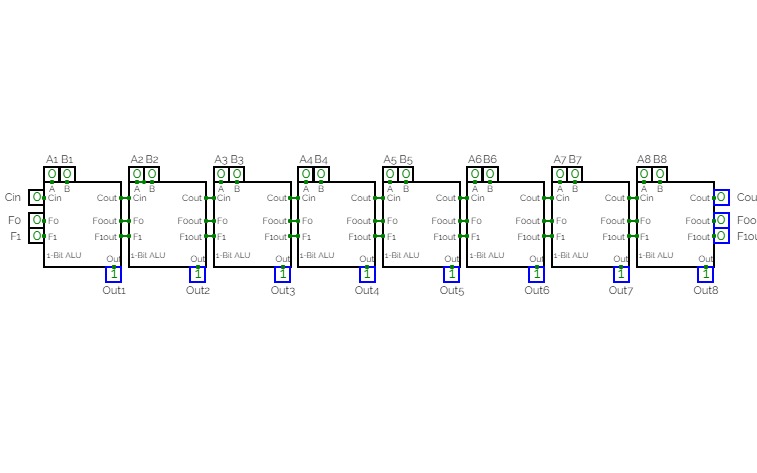
CPU ALU BUILD
CPU ALU BUILD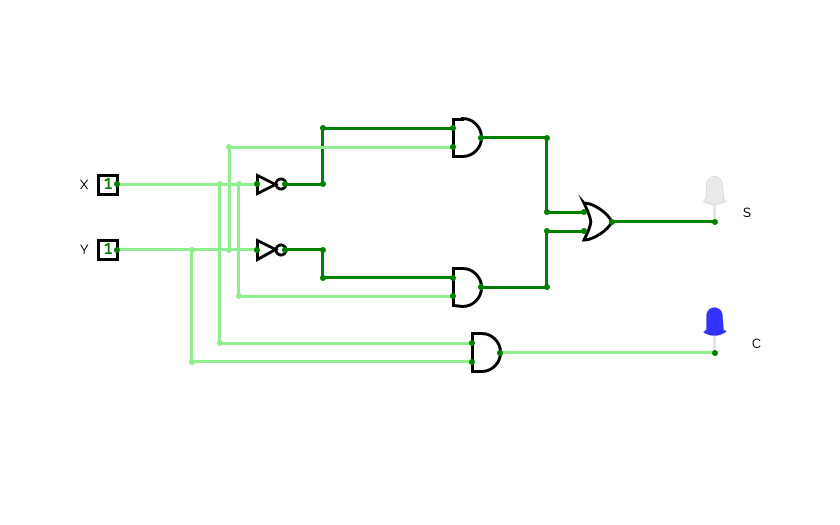

DL_CO_Half_Adder_Basic_Gates_2147033
DL_CO_Half_Adder_Basic_Gates_2147033Half Adder using Basic Gates
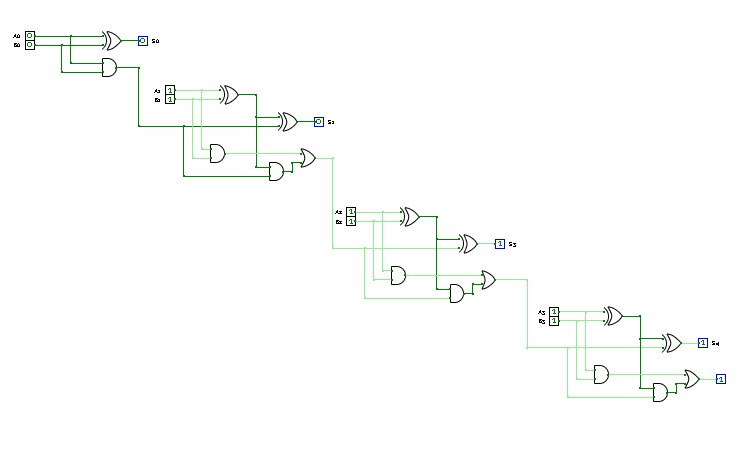
3-Bit Adder
3-Bit Adder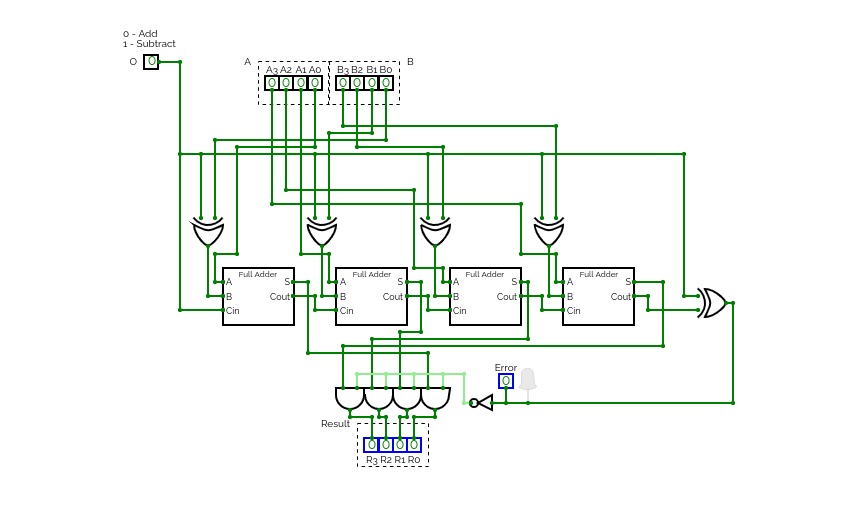

Calculator v1.1.0
Calculator v1.1.0A (currently) 4-bit adder/subtractor
Currently working on implementing multiplication, division, and a base-10 output
Format: A +/- B
Version Log
vRevamp.logicChange.reformat
v1.0.0-v1.0.2:
Base versions (4bit)
v1.1.0:
Now shuts down output when error occurs, added compact version
(I just like adding unnecessary version logs)
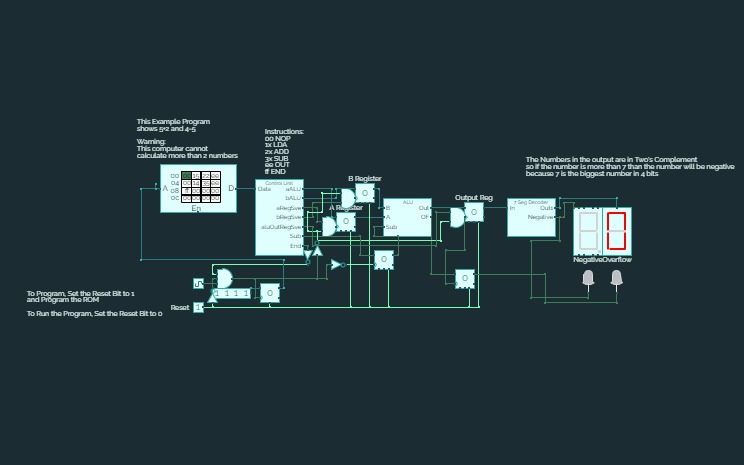
Simple 4 Bit Computer
Simple 4 Bit ComputerThis is My 4 Bit computer with 6 instructions just like the SAP Computer. :)
Instructions:
00 NOP
1x LDA
2x ADD
3x SUB
ee OUT
ff END
Warning:
This computer cannot calculate more than 2 numbers
This Example Program shows 5+7 and 4-5.
To Program, Set the Reset Bit to 1 and Program the ROM.
To Run the Program, Set the Reset Bit to 0.
The Numbers in the output are in Two's Complement so if the number is more than 7
than the number will be negative because 7 is the biggest number in 4 bits.
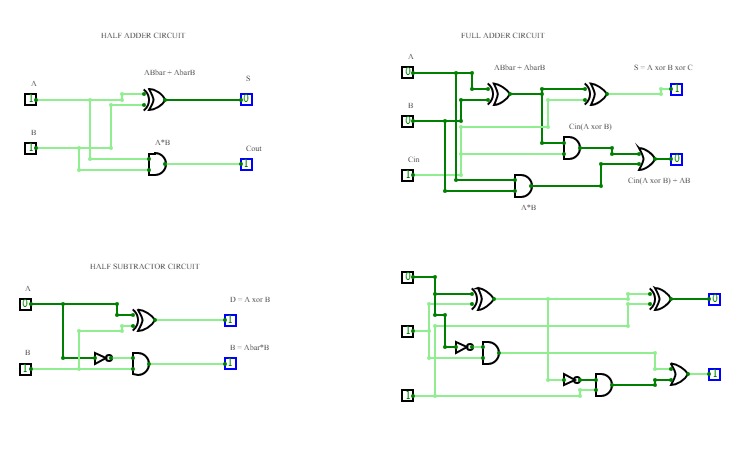
Project_2_Adder_Circuit
Project_2_Adder_CircuitA circuit diagram consisting of half and full-order variants of adder and subtractor circuits
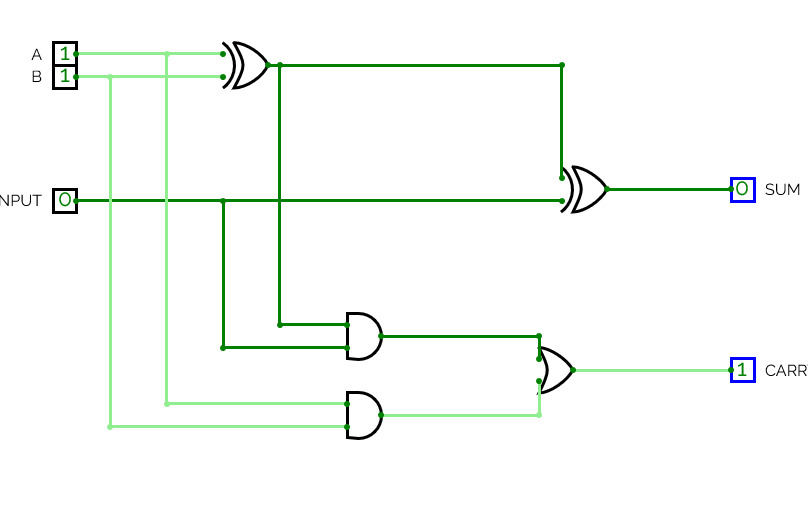
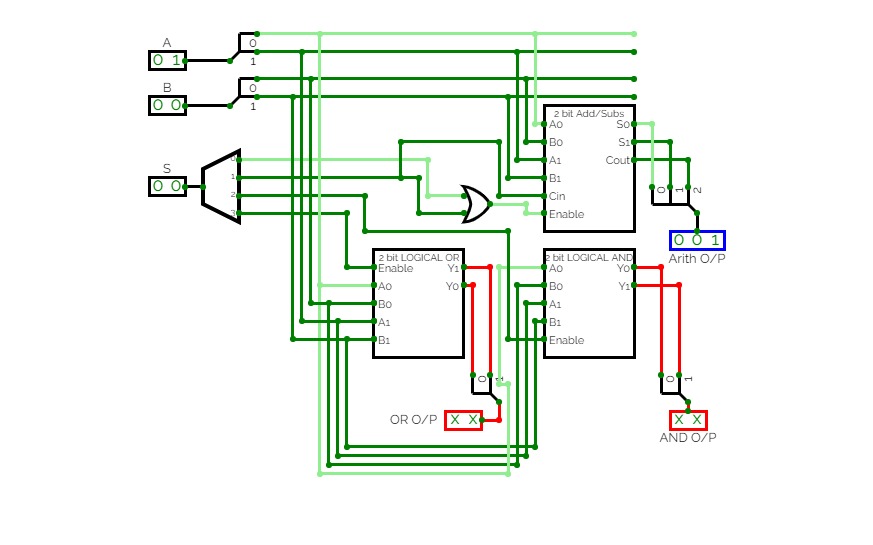

ALU 2bit 4 OPS
ALU 2bit 4 OPS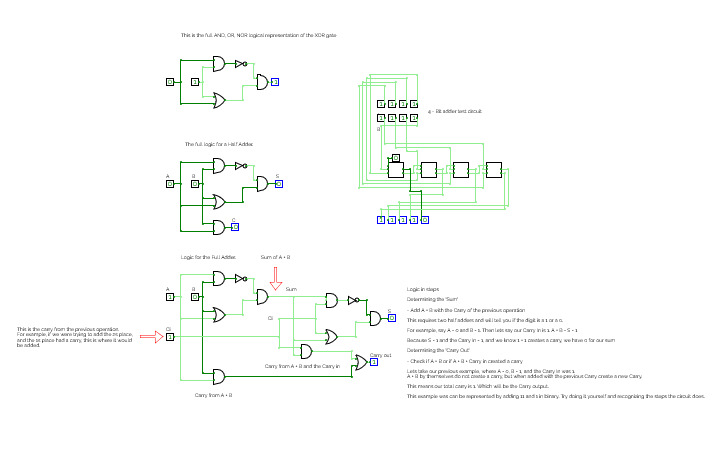
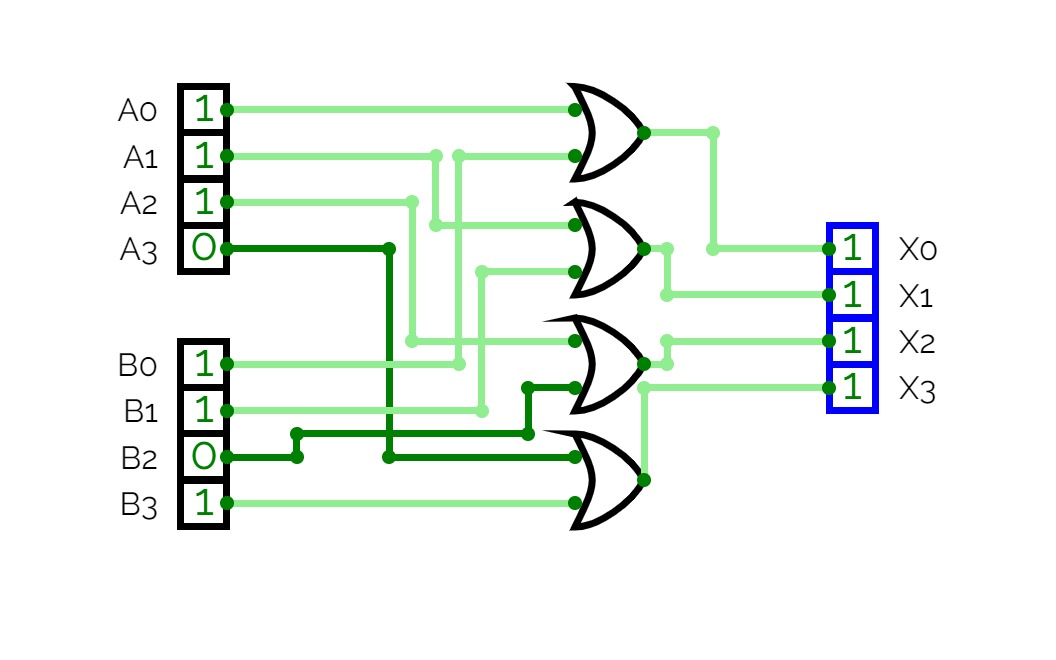
CPU
CPU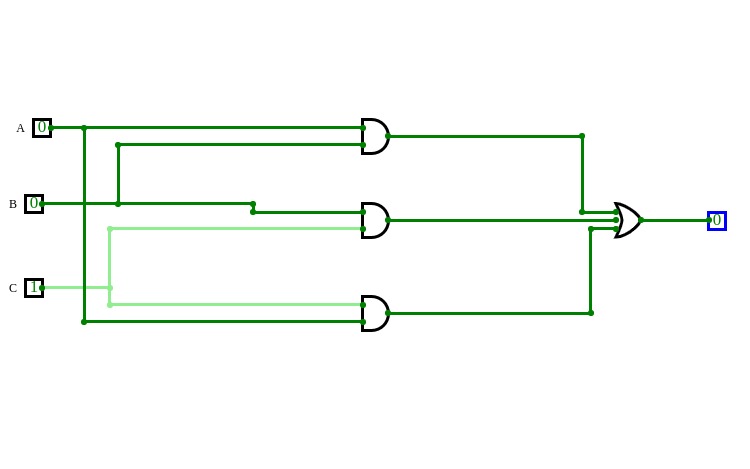
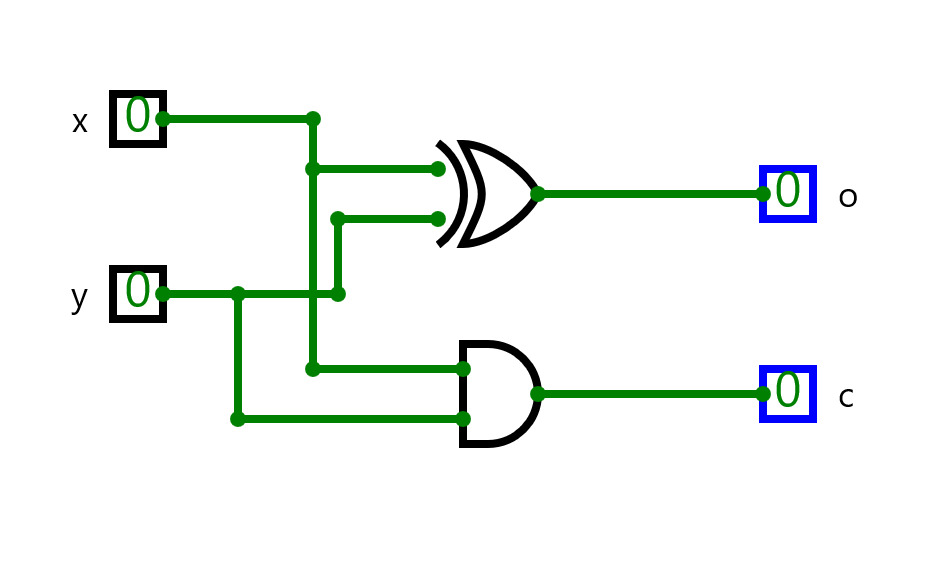
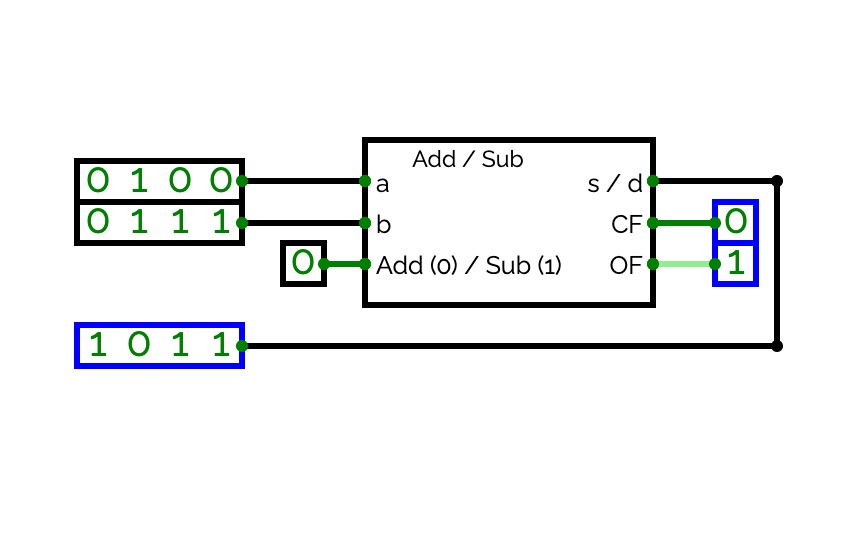
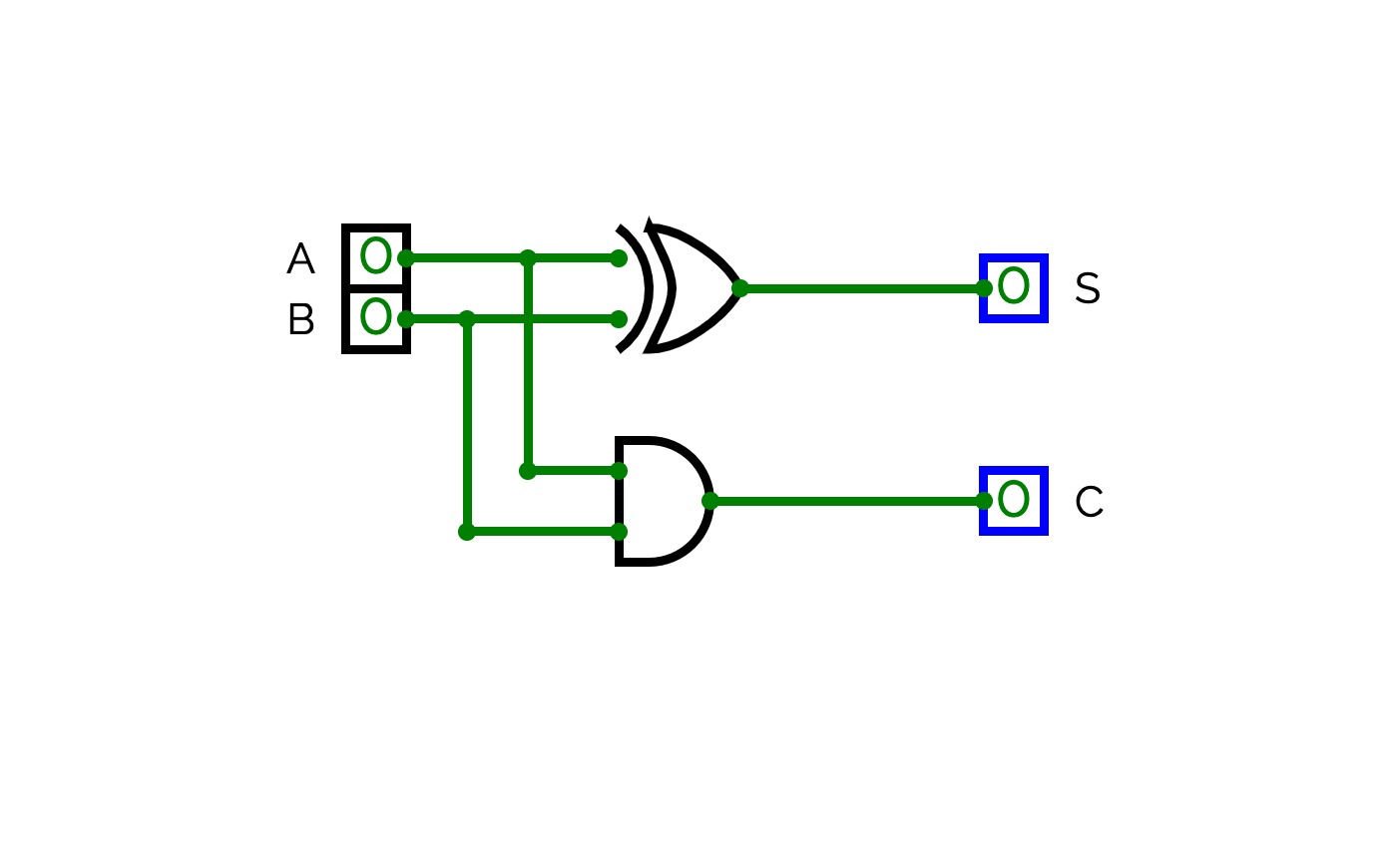
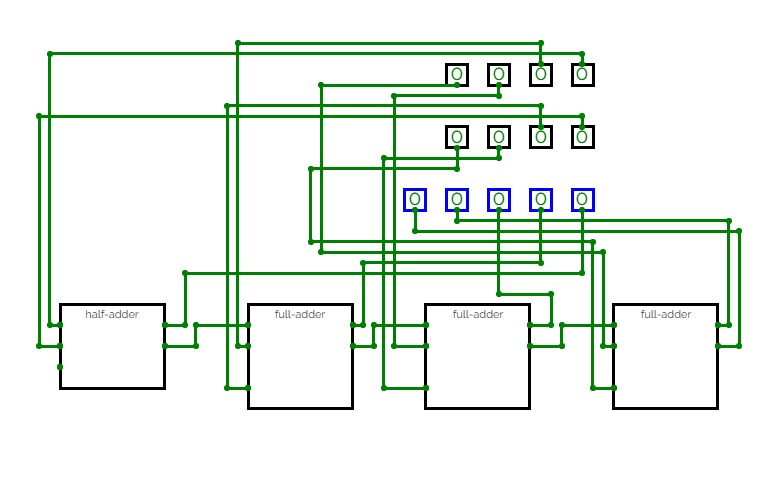
half-adder
half-adder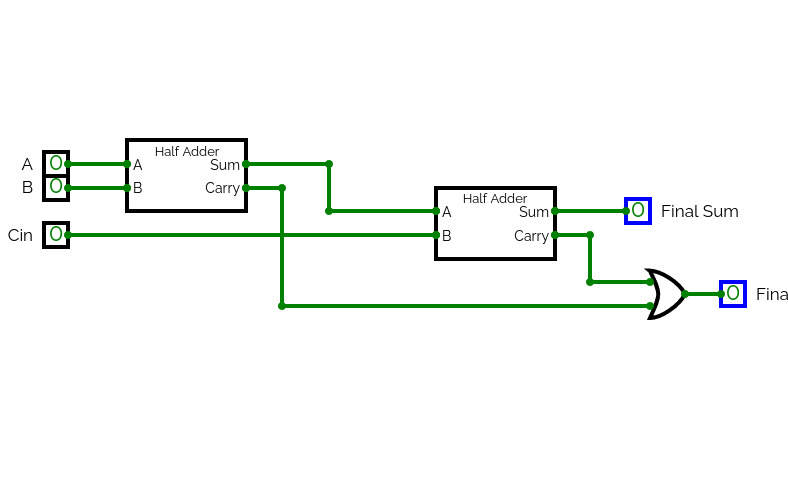
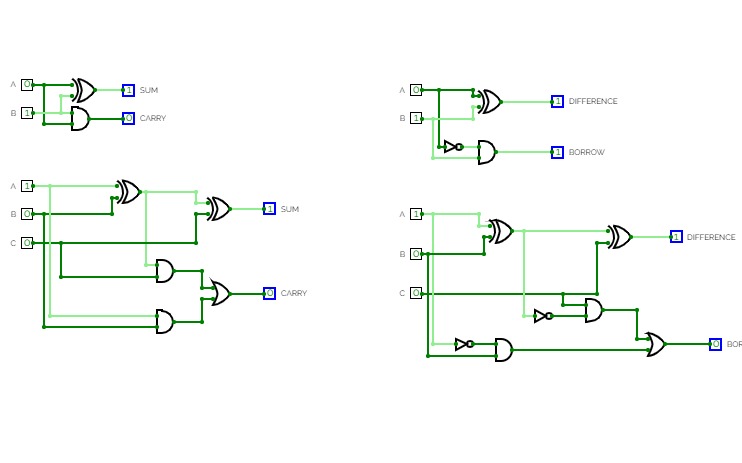
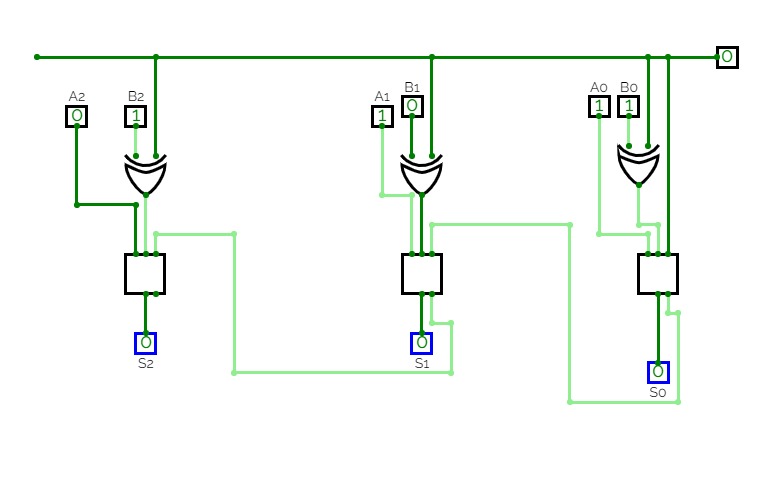
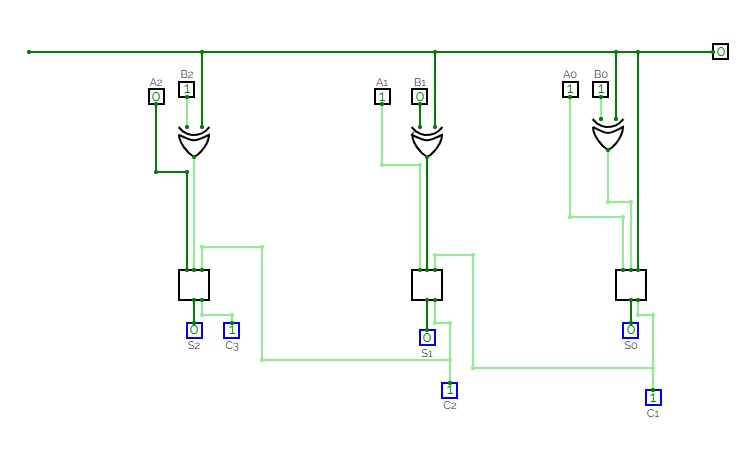
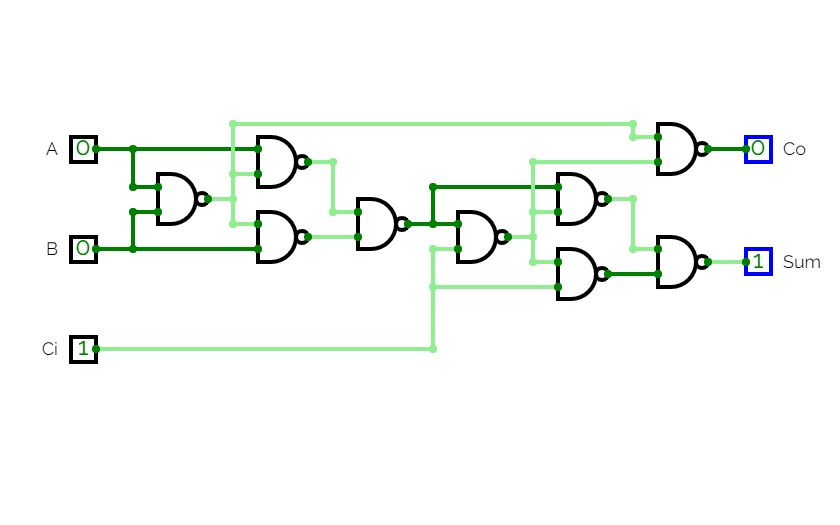
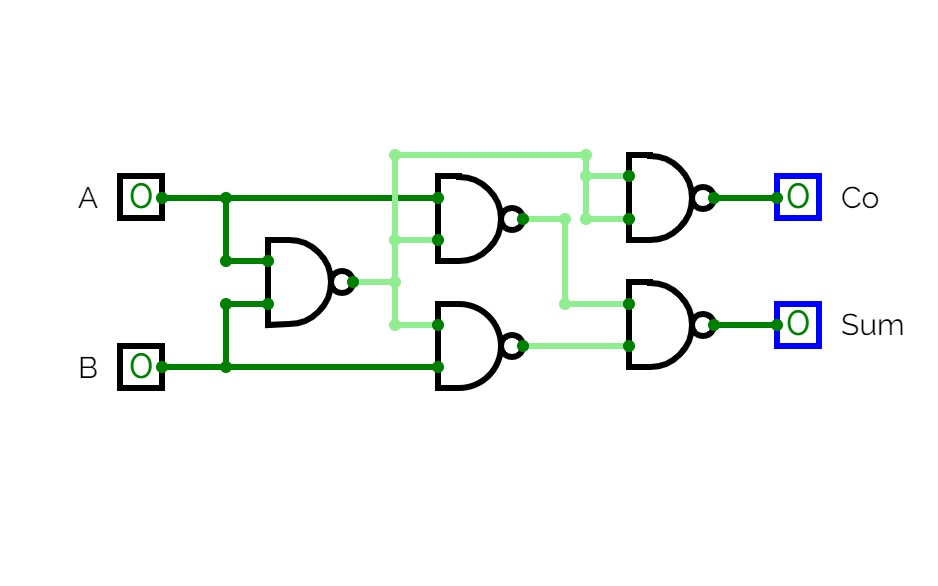





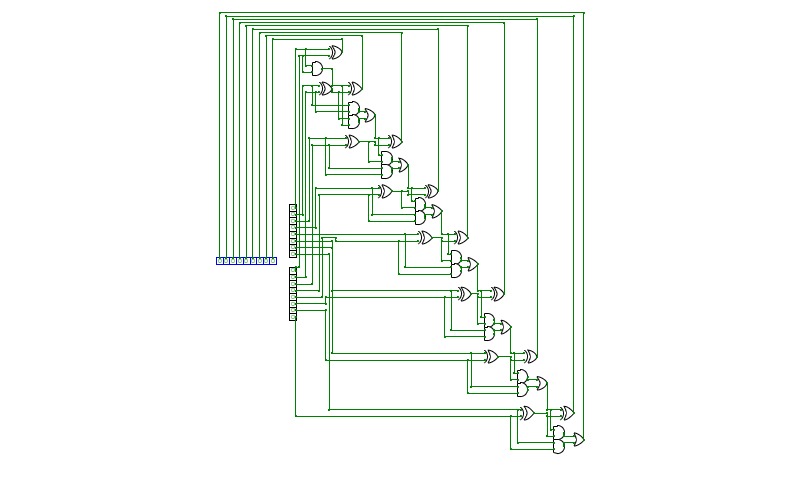

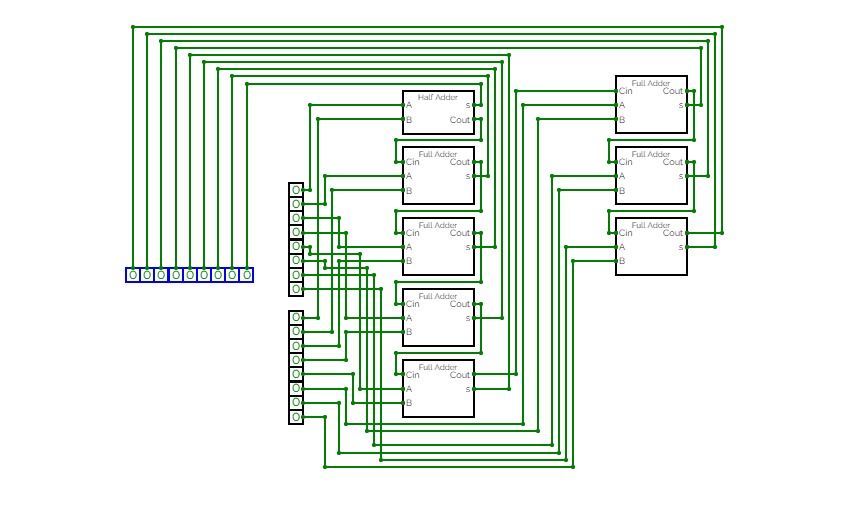

ALU- David Arsovski
ALU- David ArsovskiThis is a 4-bit ALU designed for the college course Logic Design.
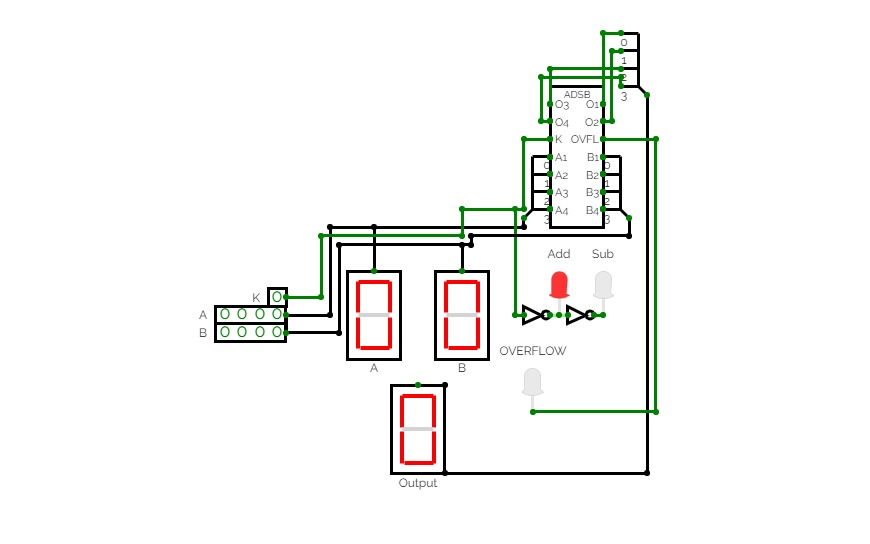
4-Bit Adder Subtractor
4-Bit Adder SubtractorA 4-Bit Adder-Subtractor. It adds and subtracts
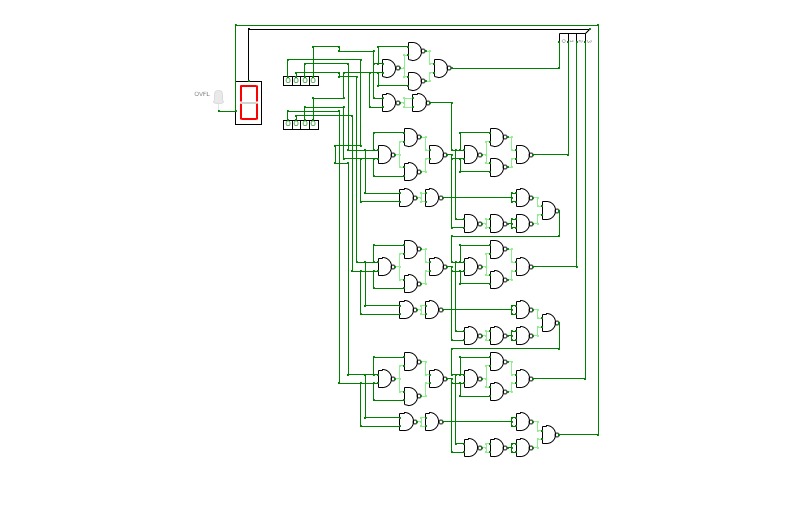
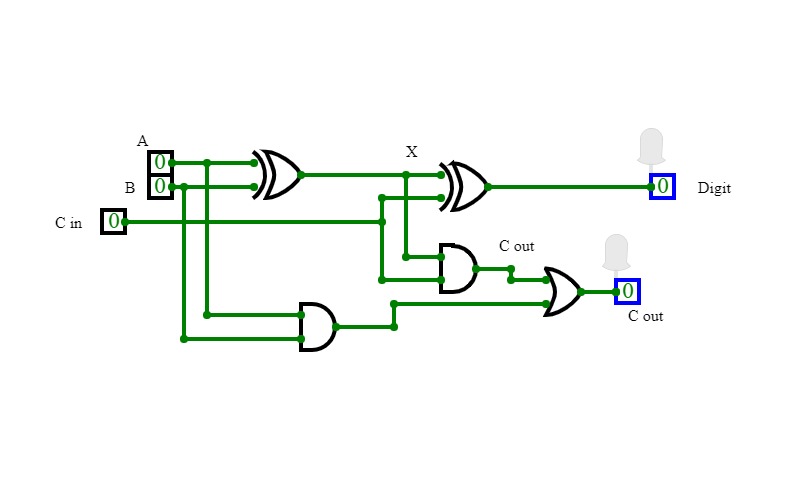
Adders
Adders
MineSweeper
MineSweeperMinesweeper: The game

Binary Adders
Binary AddersA collection of binary adders with Binary, Hex, and Decimal input and output representation
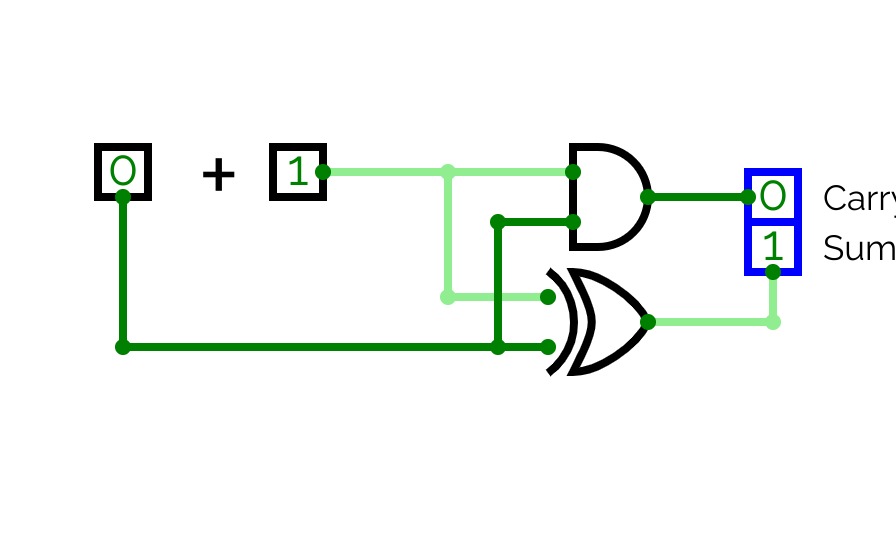
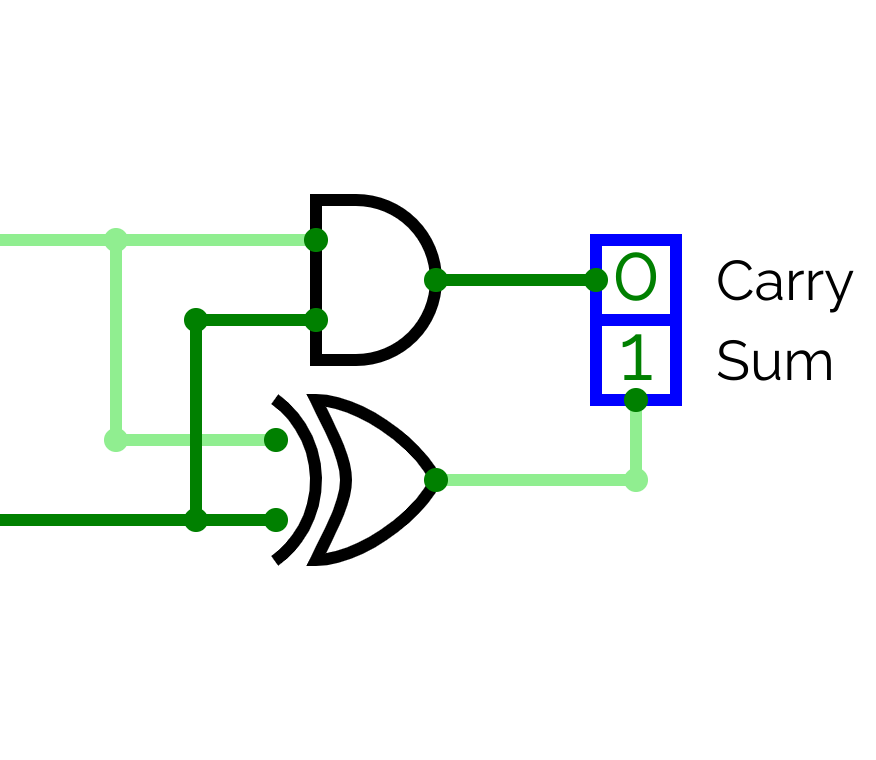
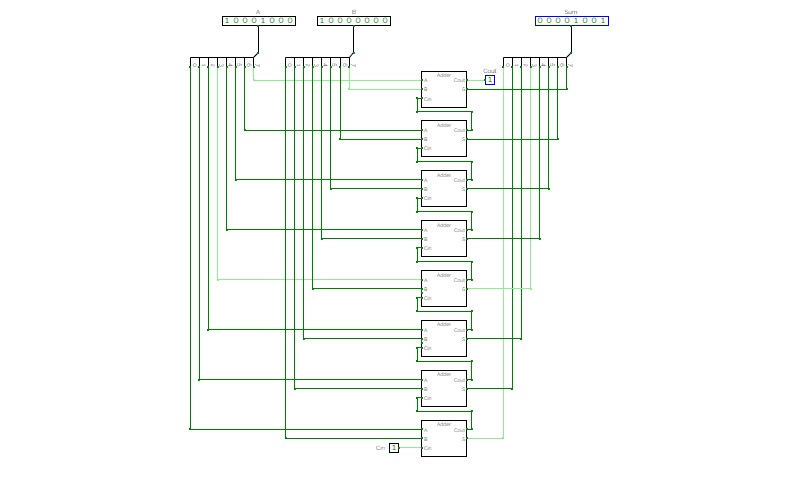
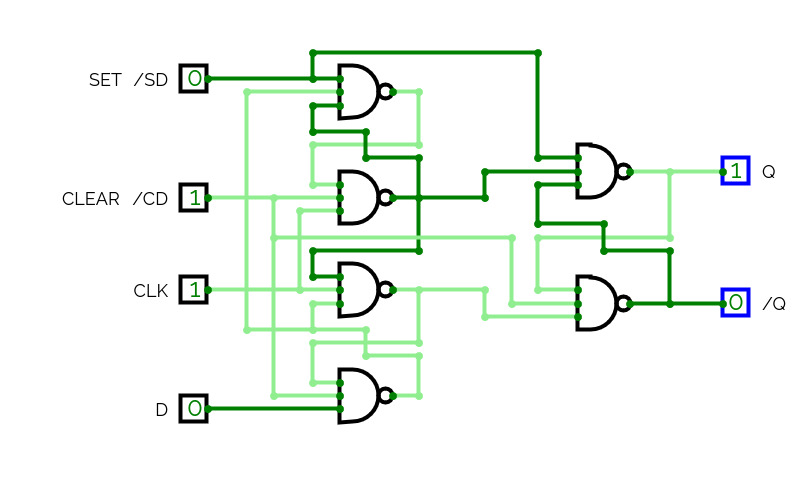
D-FLIP-FLOP
D-FLIP-FLOP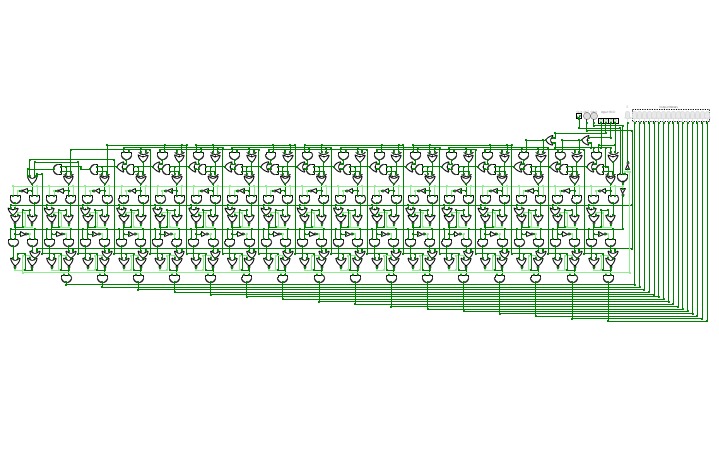

Serial BCD to binary
Serial BCD to binaryHello,
I have designed a special converter. Converts a BCD or Binary Coded Decimal number to 16-bit binary logical number. The special feature is the surprising sequential entry of numbers!
This conversion method uses a small number of logic gates and the operation is cyclical, so a clock is essential. Each BCD value entry is equal to one cycle. The converter consists of a register called the Accumulator, a 16-bit full adder and a wire connection that correctly multiplies the number by 10. A small control unit is also needed to monitor the system.
An Accumulator is a type of register, usually the first one used to store results.
The device works by adding a value from 0 to 9 to each BCD input, storing it in a register and then multiplying by 10. The cycle is repeated for each entry. so, for example, the number 123 in the BCD value 0001 0010 0011 is sent sequentially to the converter. The first number sent will be 0001. The adder will add 0001, then store the value in a register and multiply it by 10 in the binary form 1010, and the result will be 1010. We will then send a second BCD number 0010. This number will be added to the previous stored number 1010 and the resulting number will be 1100. This number is again stored in the register and multiplied by 10 according to the current time, the result will be 1111000. Then send a third BCD value 0011, which is added to the stored value 1111000 to get 1111011. Now read our final result 1111011!
This converter design is quick and easy. Unlike the others, it converts sequential BCD input values and contains a small number of logic gates. Dabble Double algorithms exist for this conversion, but they behave differently.
I have attached a diagram of how the device works below. I hope it will help you with your planning!
INSTRUCTIONS:
1. Reset the device before use!
(RST = Reset button)
2. Enter the BCD value!
(Inpu BCD)
3. After each entry, send the value!
(SND = Send)
4. Each entry is equal to one tick of the clock!
(CLK = Clock)
5. The error will be logged!
(E = Error)
6. Read the binary number!
(Output binary)
If you like my project, please give me a star (the button is on the bottom right), because it means a lot to me!
I hope you like the plan. I hope you enjoy the experience.

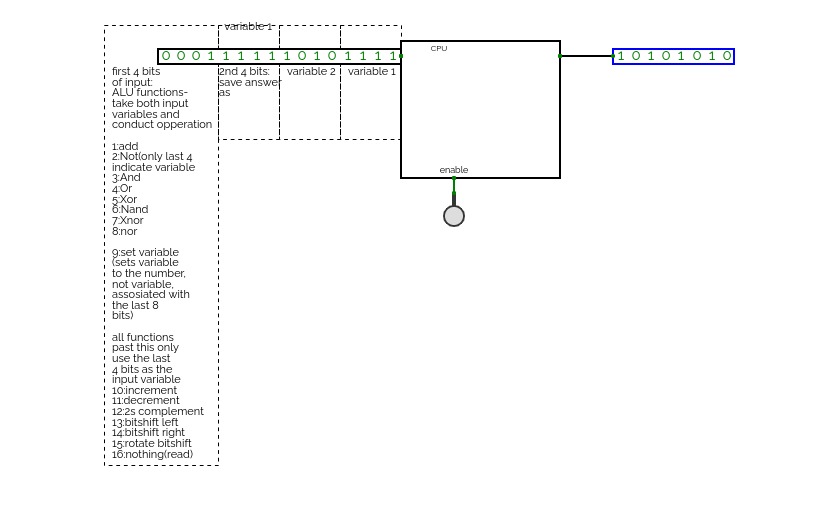
A CPU! this took me a while to figure out, mostly how to get it to run comands, but I eventually found a solution of using 4 bits as function indicators, 4 as where to save the output, 4 as the 2nd input, and 4 as the first input!
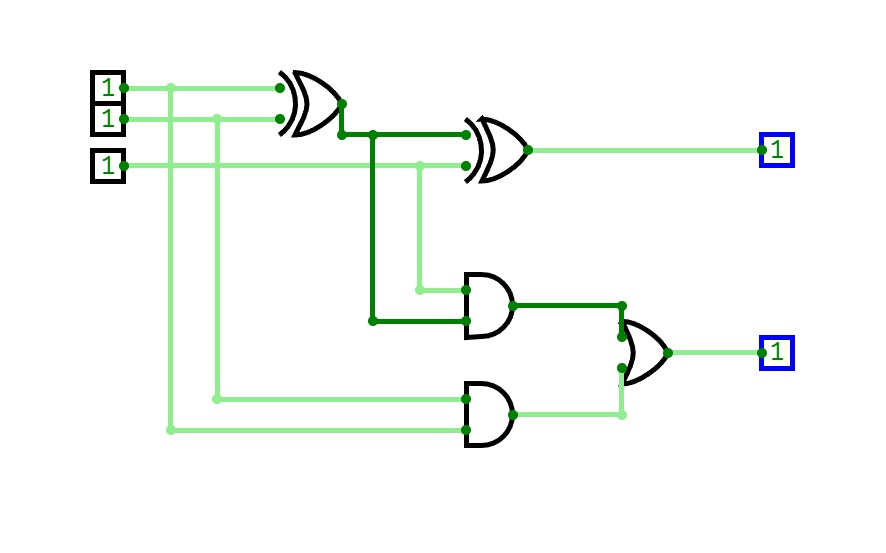
Circuits
CircuitsThis is my first diagram of a half adder and a Adder that uses half adders in its construction

Half adder and substractor
Half adder and substractor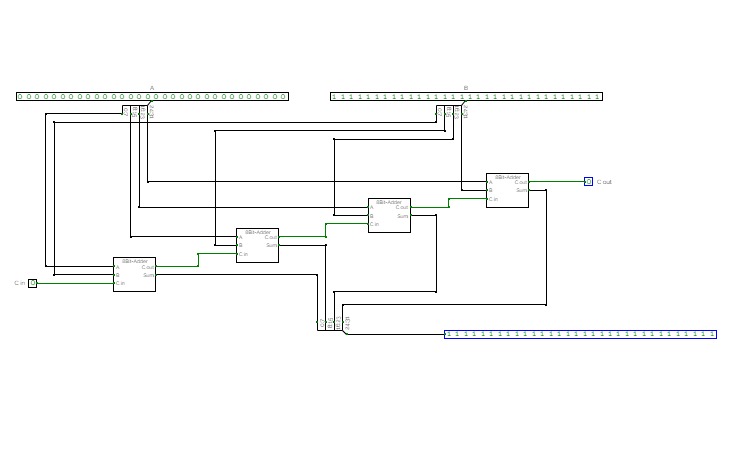
AdderPractice
AdderPractice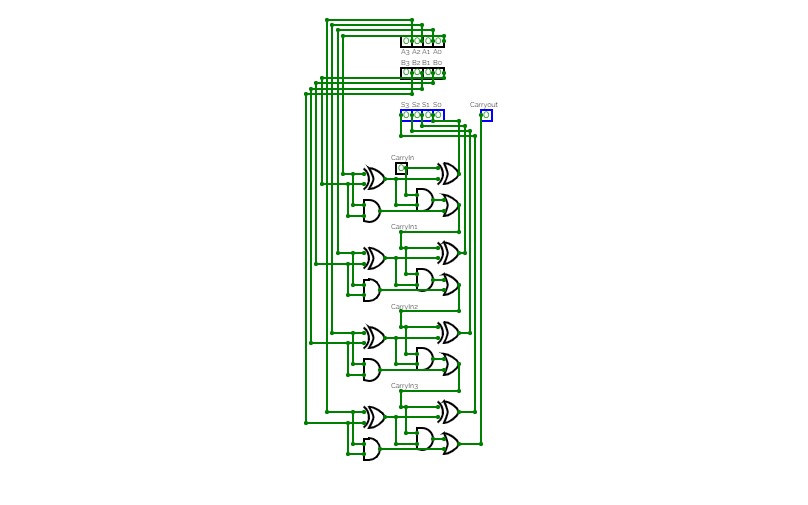
4 Bit Full Adder
4 Bit Full Adder4 Bit Full Adder that can add any two 4 bit representable numbers and has a flag for CarryOut of the most significant bit
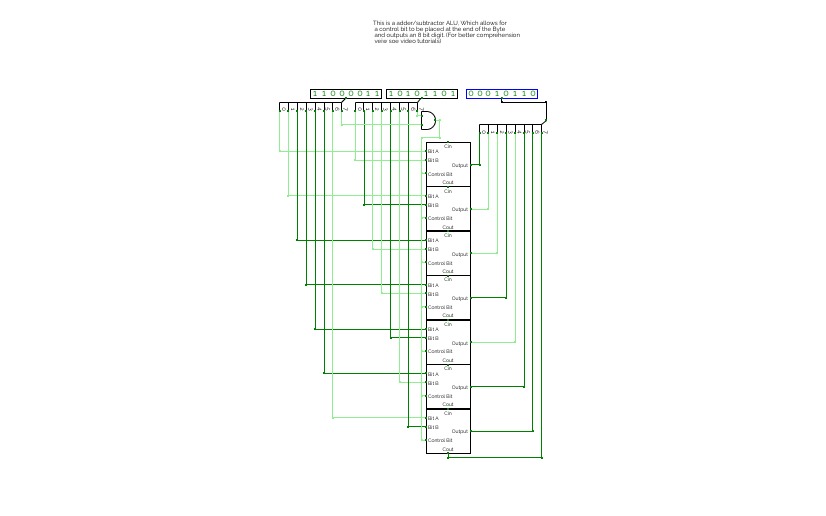
Features a single-bit adder and subtractor as well as a combination of the two. Also showcases a 4-bit adder/subtractor and an 8-bit ALU adder subtractor.
(If anything in the description is wrong please feel free to say so in the comments.

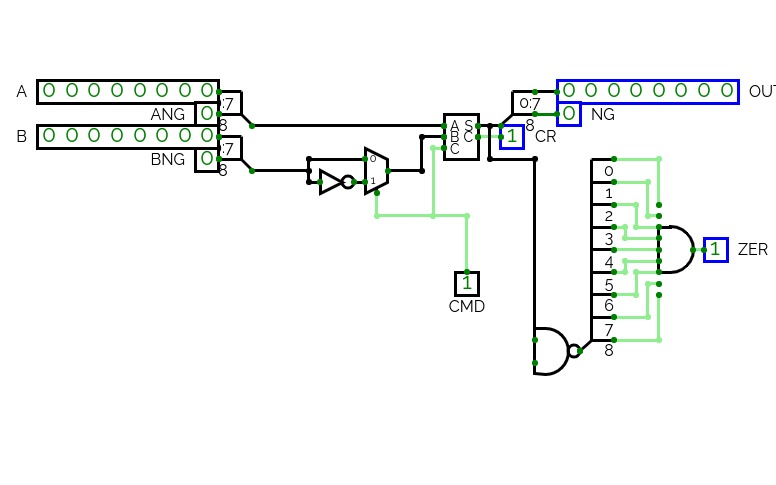

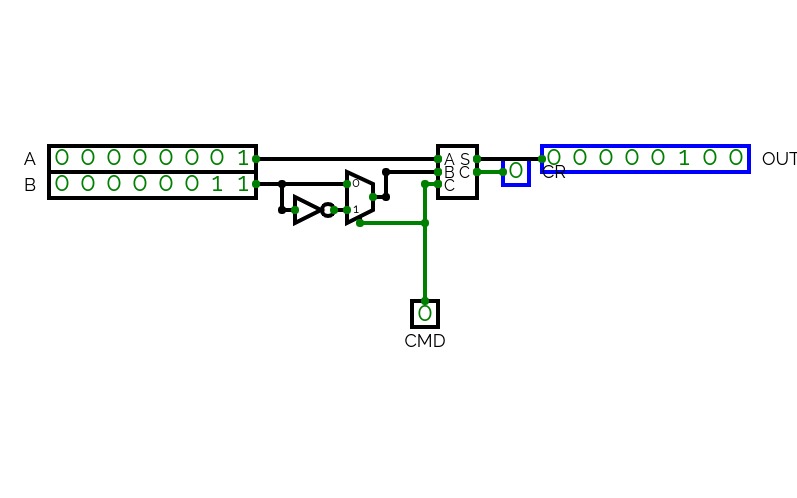

Femboy-8
Femboy-8
FEMBOY-8
Functional Electronic Machine Binary Operator Yes
8-bit CPU
Working on a NEW CPU: Femboy-16!
ASSEMBLER:
https://output.jsbin.com/wutikij
GPU:
https://circuitverse.org/users/214464/projects/cb-ppu
INSTRUCTION SET:
00: NOP - Nothing
01: HLT - Halt program
02: OUT [id] - Output the accumulator out of an output
03: LDI A, [d8] - Loads immediate 8 bit word into the accumulator
04: MOV [r], A - Move register to accumulator
05: MOV A, [r] - Move accumulator to register
06: INC [r] - Increment a register
07: DEC [r] - Decrememt a register
08: ADD [r], A - Add the accumulator from a register
09: SUB [r], A - Subtract the accumulator from a register
0A: AND [r], A - And the register and accumulator
0B: IOR [r], A - OR the register and accumulator
0C: XOR [r], A - XOR the register and accumulator
0D: NOT [r] - NOT a register
0E: SRR [r] - Barrel shift accumulator right
0F: SRL [r] - Barrel shift accumulator left
10: JUP [d8] - Jump to a location
11: JPP [r] - Jump to a register value
12: JPL A, [d8] - Jump if accumulator is less than 0
13: JZO A, [d8] - Jump if accumulator is 0
14: JPG A, [d8] - Jump if accumulator is greater than 0
15: JLE A, [d8] - Jump if accumulator is less than or equal to 0
16: JGE A, [d8] Jump if accumulator is greater than or equal to 0
17: JNZ A, [d8] Jump if accumulator is not 0
18: CLR [r] - Clear a register
19: INP [id] - Store INPUT id in accumulator
1A: MOV pA, [r] - Move the value at address A register r
1B: MOV [r], pA - Move register r into address A
1C: MOV [p], A - Move a value in a pointer to the accumulator
1D: MOV A, [p] - Move the accumulator to a location
1E: MLT [r], A - Multiply register r by the accumulator
1F: DIV [r], A - Divide register r by accumulator
REGISTERS:
00: REGISTER 1
01: REGISTER 2
02: REGISTER 3
04: REGISTER 4
05: ZERO FLAG (R)
06: PC (R)
07: ALU Result (R)
Update Notes:
V4:
So this is the 4th iteration of my CPU lol... I added a few programs for you all to try out and you can even use an assembler now!
V5:
Long time since I updated this... But I've added a GPU! It's called "Color burst" and you can go try out some premade programs I have added on it! There's an assembler guide with GPU dev guide and I encourage you all to go try and make some graphical programs! Also more docs can be found on it's project page.
To-Do:
Increase amount of registers to 8
Make a simple command line
Make a simple operating system for the CPU
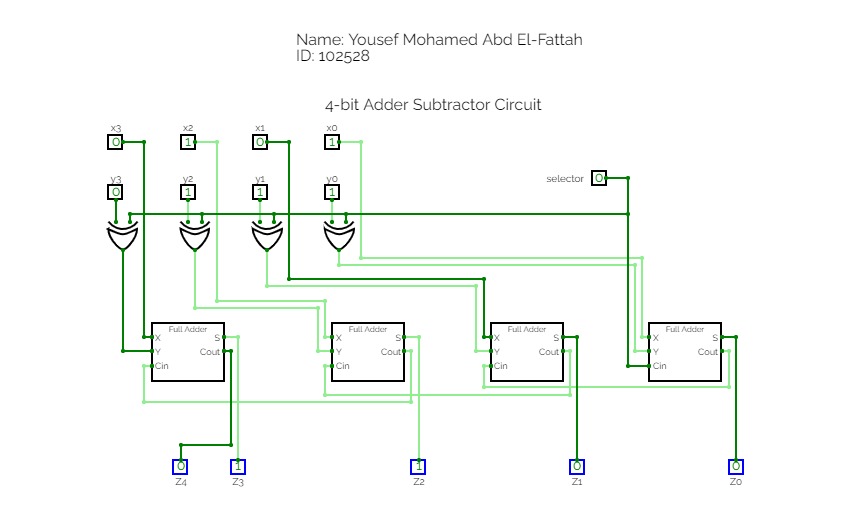
Adder subtractor Circuit detail explanation
Adder subtractor Circuit detail explanationCircuit Verse should be used only to create the project – online simulator https://circuitverse.org/simulator
All screenshots should include clear evidence for the student names and the date and time taken.
Start building the 4-bit adder subtractor circuit from the half adder until you reach the final circuit results.
Build the 1-bit half adder circuit and convert it into symbol (block).
Build the 1-bit full adder circuit and convert it into symbol (block).
Build the 4-bit adder circuit and convert it into symbol (block).
Build the 4-bit adder subtractor and convert it into symbol (block).
Build the final circuit
Build the 1-bit half adder circuit and convert it into symbol (block).
Write a detailed explanation about the full adders.
Insert your screenshot and the explanation here
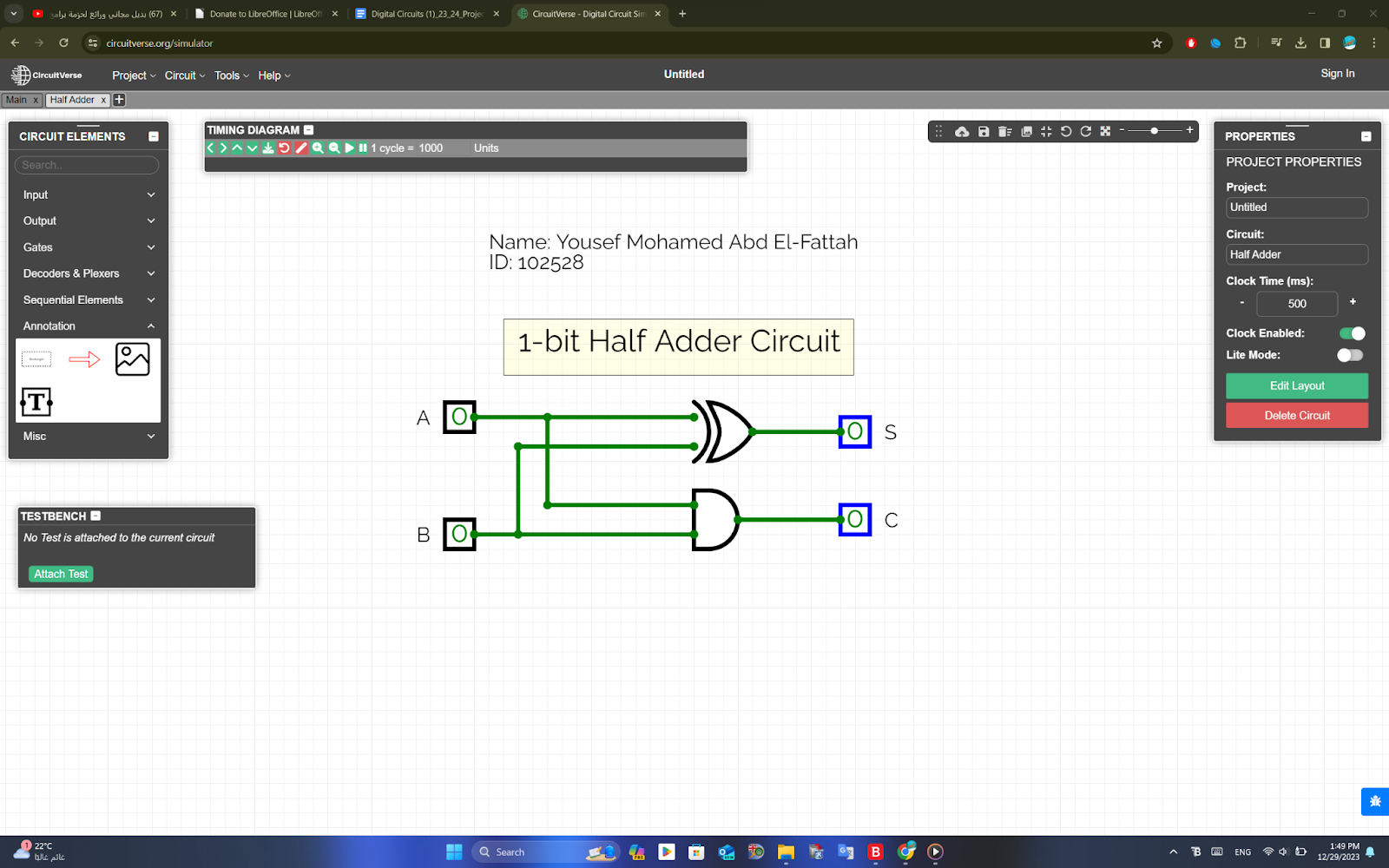
I want to sum 2 binary digits (A,B) and the sum of 2 binary numbers needs (at most) 2 output digits;
so from truth table:
A
B
Sum
Carry
0
0
0
0
0
1
1
0
1
0
1
0
1
1
0
1
Sum: S = (A.B’) + (A’.B) = A⨁ B
Carry: C = A.B
Build the 1-bit full adder circuit and convert it into symbol (block).
Write a detailed explanation about the full adders.
Insert your screenshot and the explanation here
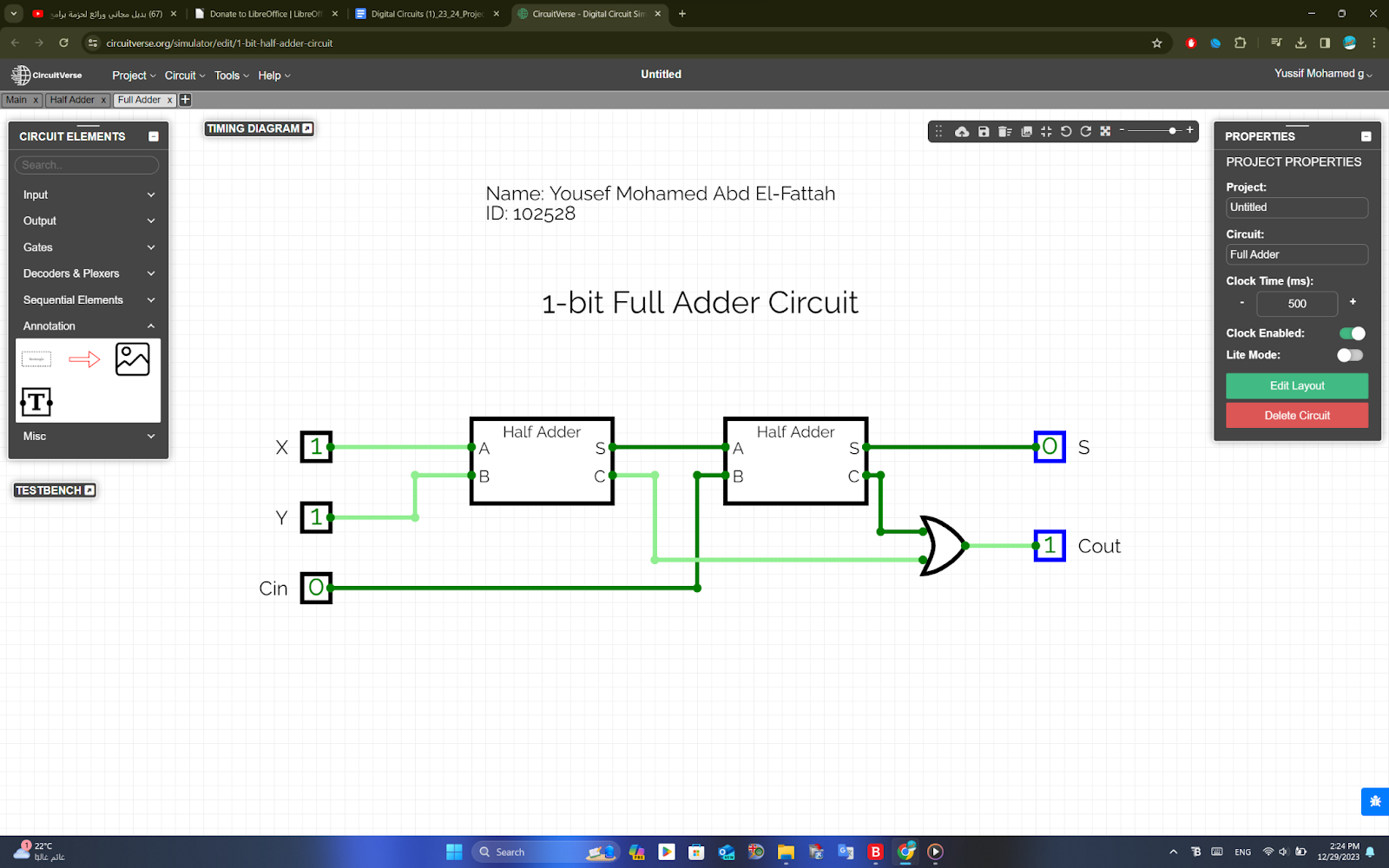
I want to sum 3 binary digits (X ,Y , Cin) and the sum of 3 binary numbers needs (at most) 2 output digits (S , Cout).
X
Y
Cin
Sum
Carry
0
0
0
0
0
0
0
1
1
0
0
1
0
1
0
0
1
1
0
1
1
0
0
1
0
1
0
1
0
1
1
1
0
0
1
1
1
1
1
1
Sum = (X’ .Y’ .Cin) + (X’ .Y .Cin’) + (X .Y’ .Cin’) + (X .Y .Cin)
= X’ .((Y’ .Cin) + (Y .Cin’)) + X .((Y’ .Cin’) + (Y .Cin))
= X’ .(Y⨁ Cin) + X .(Y⨁ Cin)’
= X ⨁ Y ⨁ Cin
Carry = (X’ .Y .Cin) + (X .Y’ .Cin) + (X .Y .Cin’) + (X .Y .Cin)
= Cin .(X⨁ Y) + X .Y
since: Sum [from Full Adder (F.A.)] = X ⨁ Y ⨁ Cin
= Sum1 [from Half Adder (H.A.)] ⨁ Cin
Carry [from Full Adder (F.A.)] = X .Y + Cin .(X⨁ Y)
= Carry1 [from Half Adder (H.A.)] + Cin .(X⨁ Y)
I can use 1 Half Adder to get [Sum1 from H.A. = X⨁ Y] and [Carry1 from H.A. = X.Y]
then I can use anther 1 Half Adder with (first Sum form H.A. & Cin) to get:
===> Sum =[(Sum1 from H.A.) ⨁ Cin] = X ⨁ Y ⨁ Cin <=== that’s the final Sum
and Carry2 [from second Half Adder (H.A.)] = Cin .(X⨁ Y)
If I passed the two Carry outputs (Carry1 & Carry2) through OR gate; I will get the final Carry:
===> final Carry = Carry1 + Carry2 = X .Y + Cin .(X⨁ Y) <=== that’s the final Carry
So, we can use 2 H.A. & OR gate to construct Full Adder.
Build the 4-bit adder circuit and convert it into symbol (block).
Write a detailed explanation about how it works.
Insert your screenshot and the explanation here
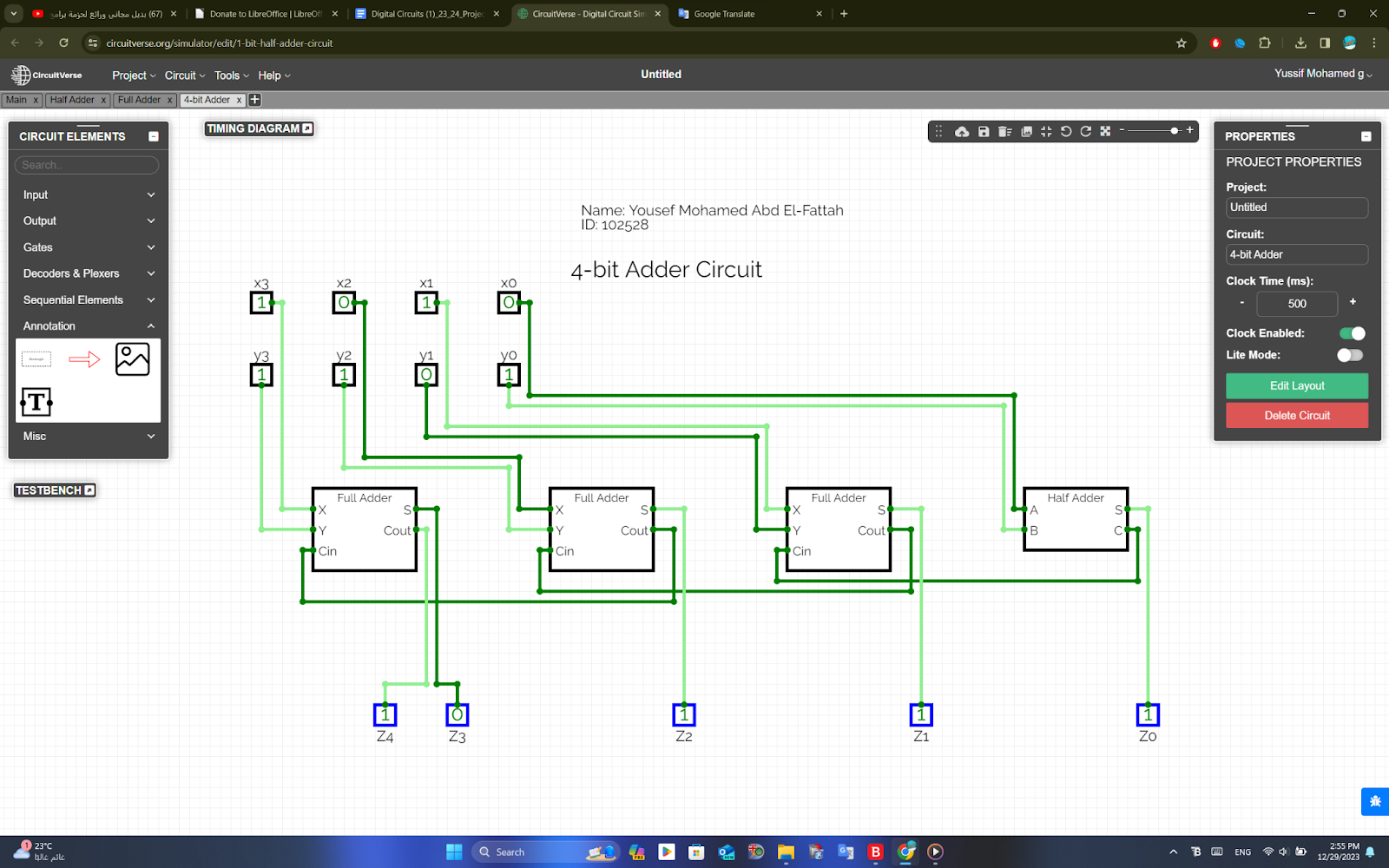
since Half Adder Circuit (H.A.) can sum 2 digits
since Full Adder Circuit (F.A.) can sum 3 digits at once
It’s generally used Full Adder (F.A.) Circuits to sum 2 digits (1-digit from input x & 1-digit from input y) and add to them the carry (in the third input digit) from previous sum operation.
Ofcourse first 1-bit adder doesn’t need 3 input digits (because of there is no Carry);
So I used H.A. Circuit in first 1-bit Adder.
Build the 4-bit adder subtractor and convert it into symbol (block).
Write a detailed explanation about how it works.
Insert your screenshot and the explanation here
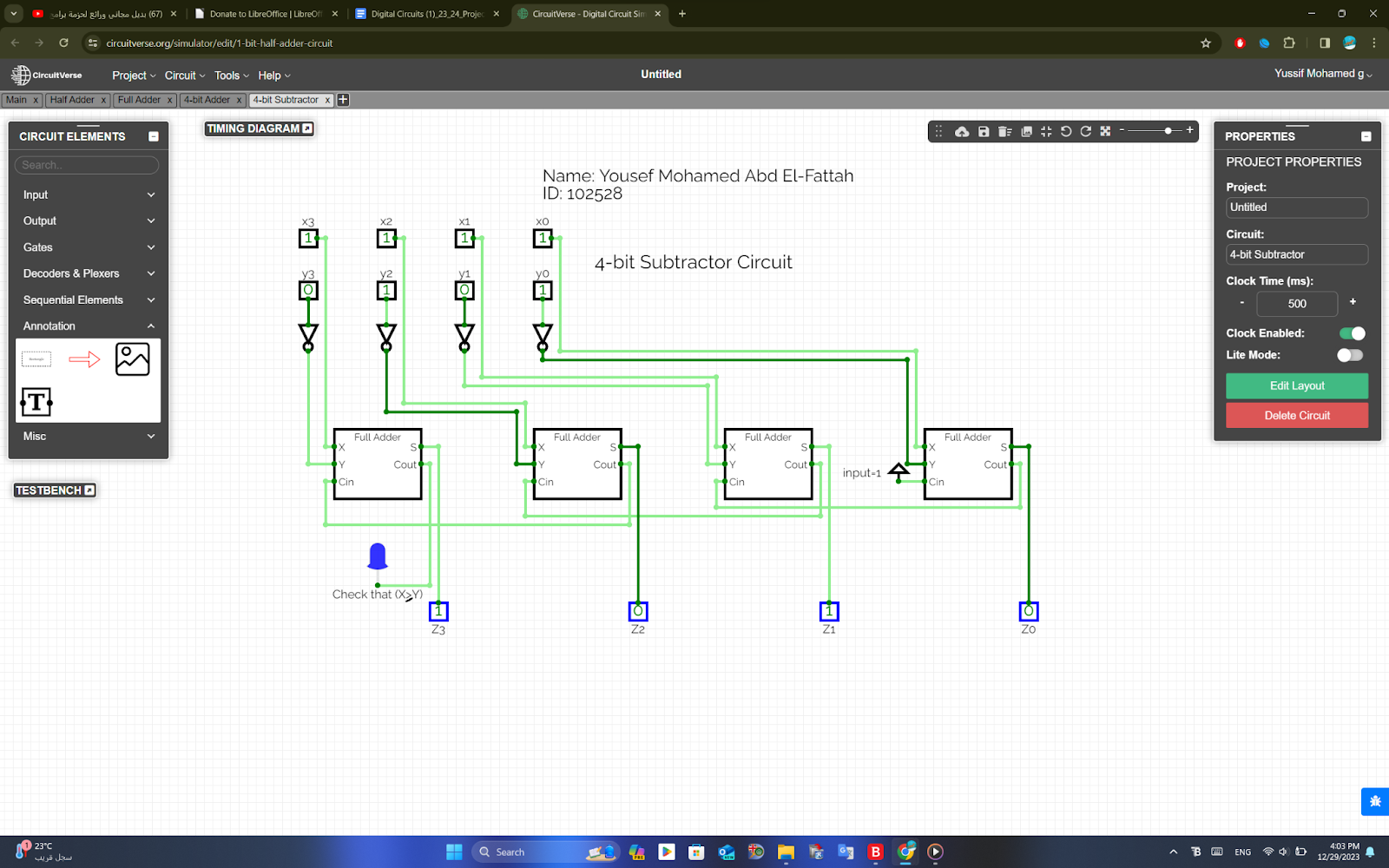
It’s preferred to subtract binary numbers (Z= X - Y) using the 2’s complement method; Which says that we find the 1’s complement to the -ve number (Y) and then add 1 to it;
After that we can use the new input of Y to sum it normally with X using a 4-bit Adder Circuit.
⇒ The complement of every digit of Y = Y’ ⇒ Y’ = {y0’ , y1’ , y2’ , y3’}
so every digit of Y enters on NOT gate to become Y’
⇒ Then add 1 (as a carry) to the Sum of first 1-bit Full Adder(F.A.)
∴The output Z = X - Y [but X must be >= Y]
Build the final circuit
Include screenshots with 4 different random examples and explain each one:
2 addition
2 subtraction
Write detailed explanation about how it works and how you did it.
Insert your screenshots and the explanation here
HOW I DID THIS CIRCUIT:
The Circuit works in 2 options. When I keep [selector = 0] the Circuit is a 4-bit Adder and when I keep [selector = 1] the circuit is a 4-bit Subtractor.
∵The difference between 4-bit adder & 4-bit subtractor is in
1)the input Y (which is converted to Y’ in a 4-bit Subtractor)
2)& the third input digit in the first bit Full adder.
∴For input Y problem:
we need to find the equation that converts Y to Y’ (the 1’s complement) when the [selector = 1]. (i’ll use y0 digit to explain on)
selector
y0
f(y0)
0
0
0
0
1
1
1
0
1
1
1
0
f(y0) = selector ⨁ y0
⇒ ∴the problem of Y is solved when we connect every digit of Y with selector using X-OR gate.
∴For the problem of the third input digit in the first 1-bit Full adder:
we need to keep [the third input digit = 0] when the wanted operation is sum (selector=0) and keep [third input digit = 1] when the operation is subtraction (selector=1)
⇒ ∴ The third input digit in first bit Full adder = selector
Screenshot 1
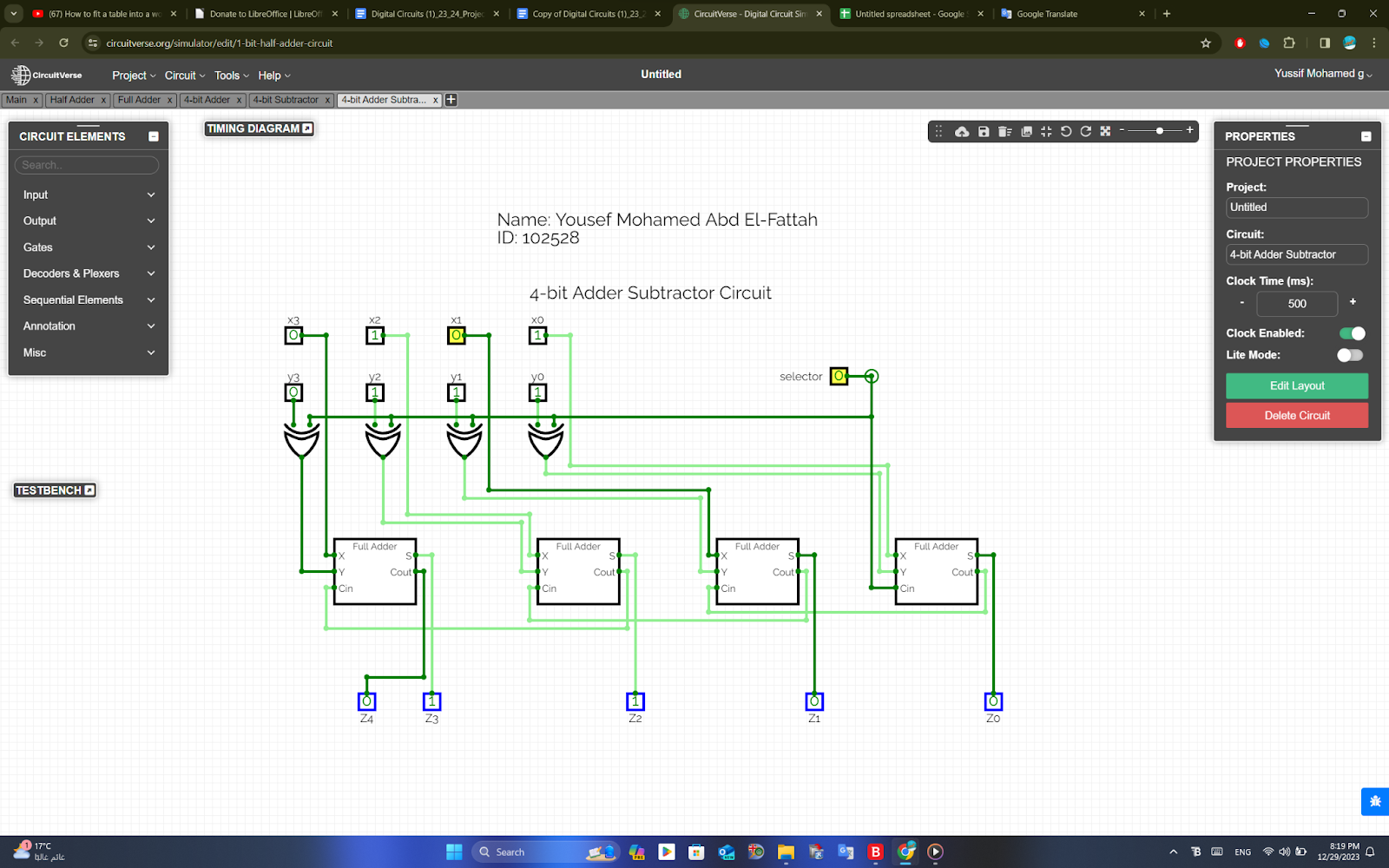
When the input X=(0101) :{x3=0 , x2=1 , x1=0 , x0=1}
& when the input Y=(0111) : {y3=0 , y2=1 , y1=1 , y0=1}
∵ selector = 0 ∴ The operation is summing (Z = X + Y)
∴ Z0 = sum of three input digits (x0 , y0 , Cin)
Z0= x0 + y0 + selector = 1 + 1 + 0 = 0 [& 1-carried to next bit Full Adder]
Z1= x1 + y1 + Cin = 0 + 1 + 1(carry)= 0 [& 1-carried to next bit Full Adder]
Z2= x2 + y2 + Cin = 1 + 1 + 1(carry)= 1 [& 1-carried to next bit Full Adder]
Z3= x3 + y3 + Cin = 0 + 0 + 1(carry)= 1 [& no carry]
Z4= last carry = 0
∴ Z = 01100
Screenshot 2
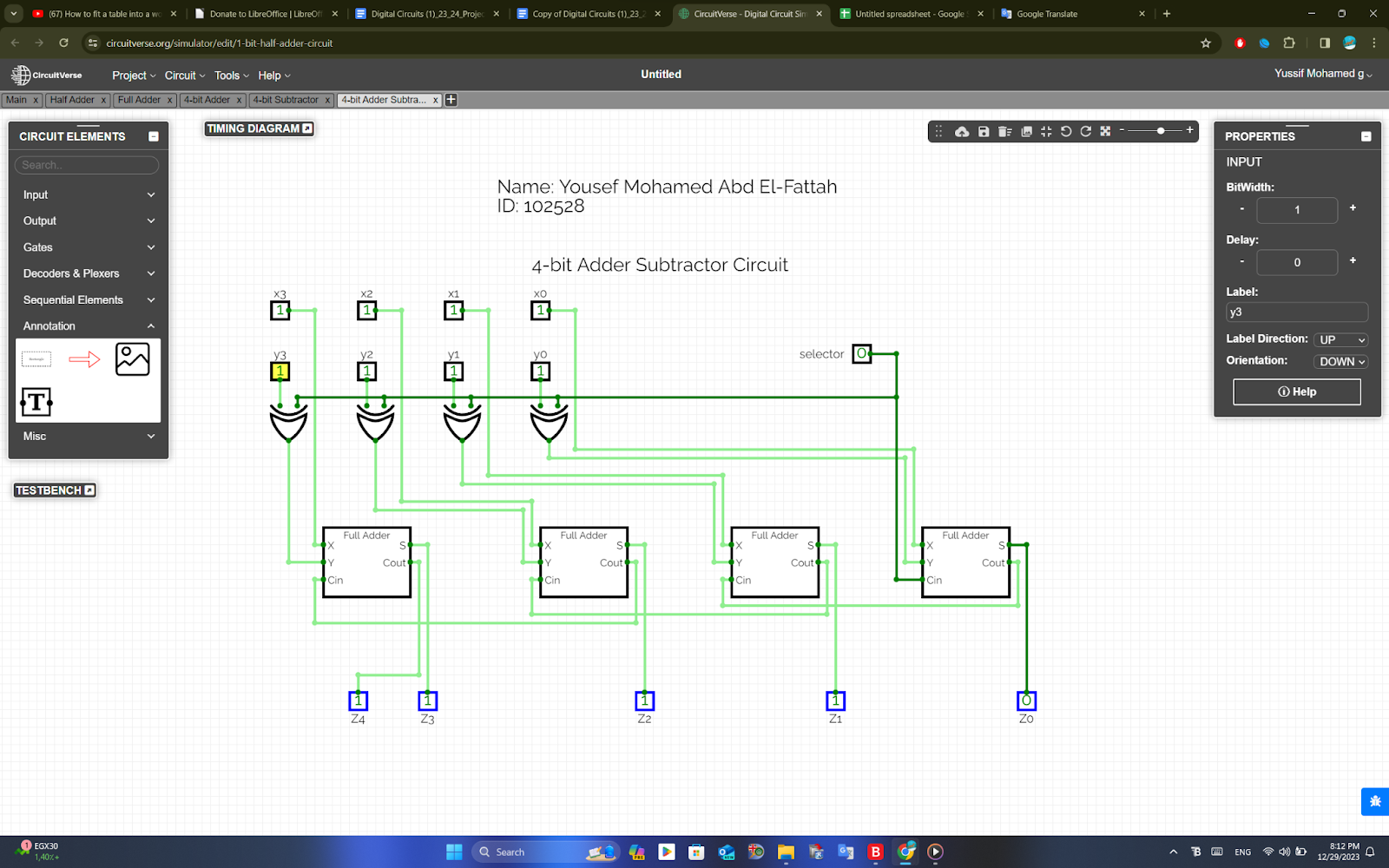
When the input X=(1111) :{x3= 1 ,x2= 1 ,x1= 1 ,x0= 1}
& when the input Y=(1111) : {y3= 1 ,y2= 1 ,y1= 1 ,y0= 1}
∵ selector = 0 ∴ The operation is summing (Z = X + Y)
∴ Z0 = sum of three input digits (x0 , y0 , Cin)
Z0= x0 + y0 + Cin = 1 + 1 + selector = 0 [& 1-carried to next bit Full Adder]
Z1= x1 + y1 + Cin = 1 + 1 + 1(carry) = 1 [& 1-carried to next bit Full Adder]
Z2= x2 + y2 + Cin = 1 + 1 + 1(carry) = 1 [& 1-carried to next bit Full Adder]
Z3= x3 + y3 + Cin = 1 + 1 + 1(carry) = 1 [& 1-carried to next bit Full Adder]
Z4= last carry = 1
∴ Z = 11110
Screenshot 3
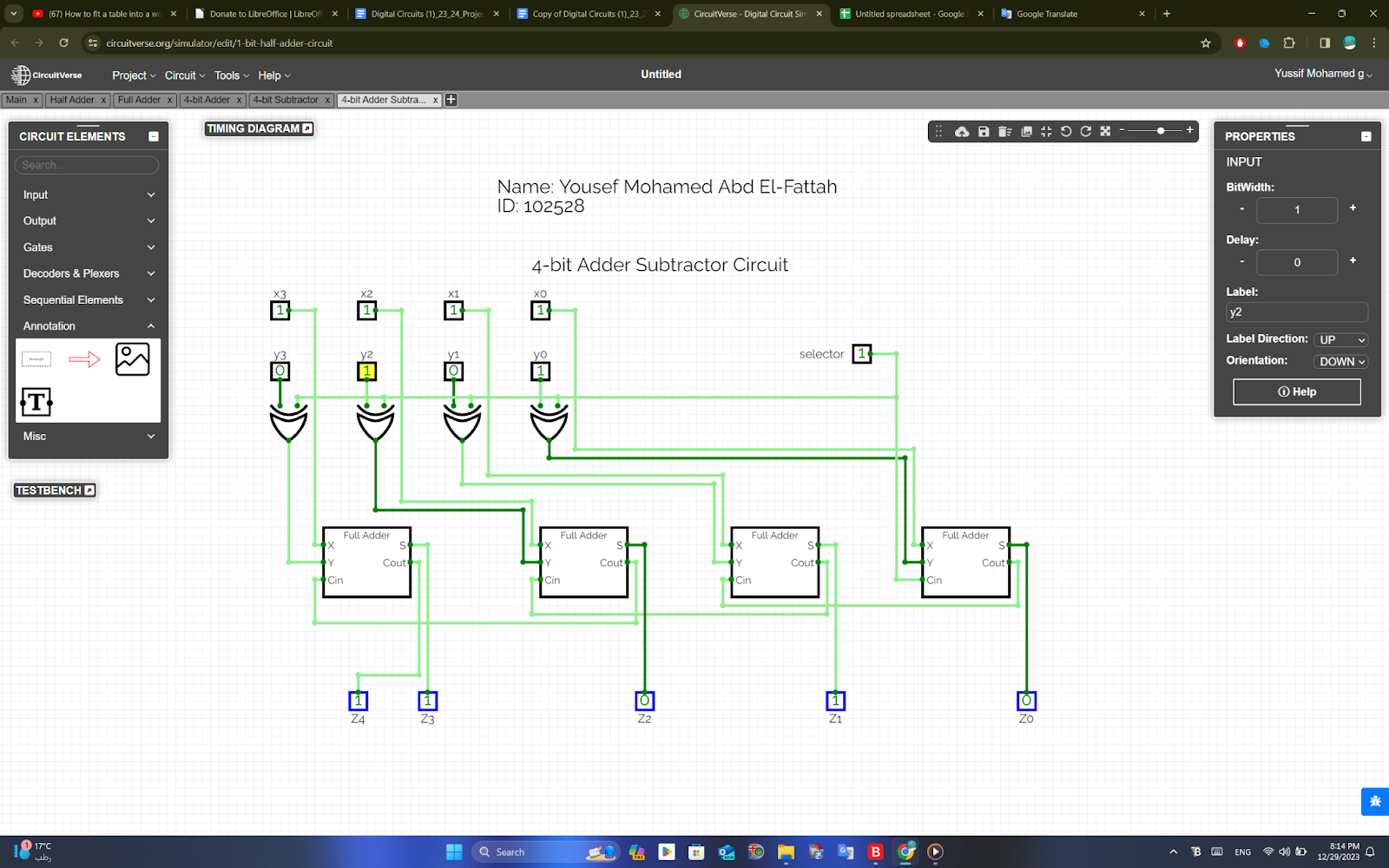
When the input X=(1111) :{x3= 1 ,x2= 1 ,x1= 1 ,x0= 1}
& when the input Y=(0101) : {y3= 0 ,y2= 1 ,y1= 0 ,y0= 1}
∵ selector = 1 ∴ The operation is subtract (Z = X - Y)
the circuit Subtracts using 2’s complement method:
∴ 1’s complement of Y = Y’ = 1010: {y3’= 1 ,y2’= 0 ,y1’= 1 ,y0’= 0}
∴ Z0 = sum of three input digits (x0 , y0’ , Cin)
Z0= x0 + y0’ + Cin = 1 + 0 + selector = 0 [& 1-carried to next bit Full Adder]
Z1= x1 + y1’ + Cin = 1 + 1 + 1(carry) = 1 [& 1-carried to next bit Full Adder]
Z2= x2 + y2’ + Cin = 1 + 0 + 1(carry) = 0 [& 1-carried to next bit Full Adder]
Z3= x3 + y3’ + Cin = 1 + 1 + 1(carry) = 1 [& 1-carried to next bit Full Adder]
Z4= last carry = 1 (note: we ignore last bit (Z4) in subtract operation & it have to = 1)
when [Z4 = 1] that means [X>=Y]
∴ Z = 1010
Screenshot 4
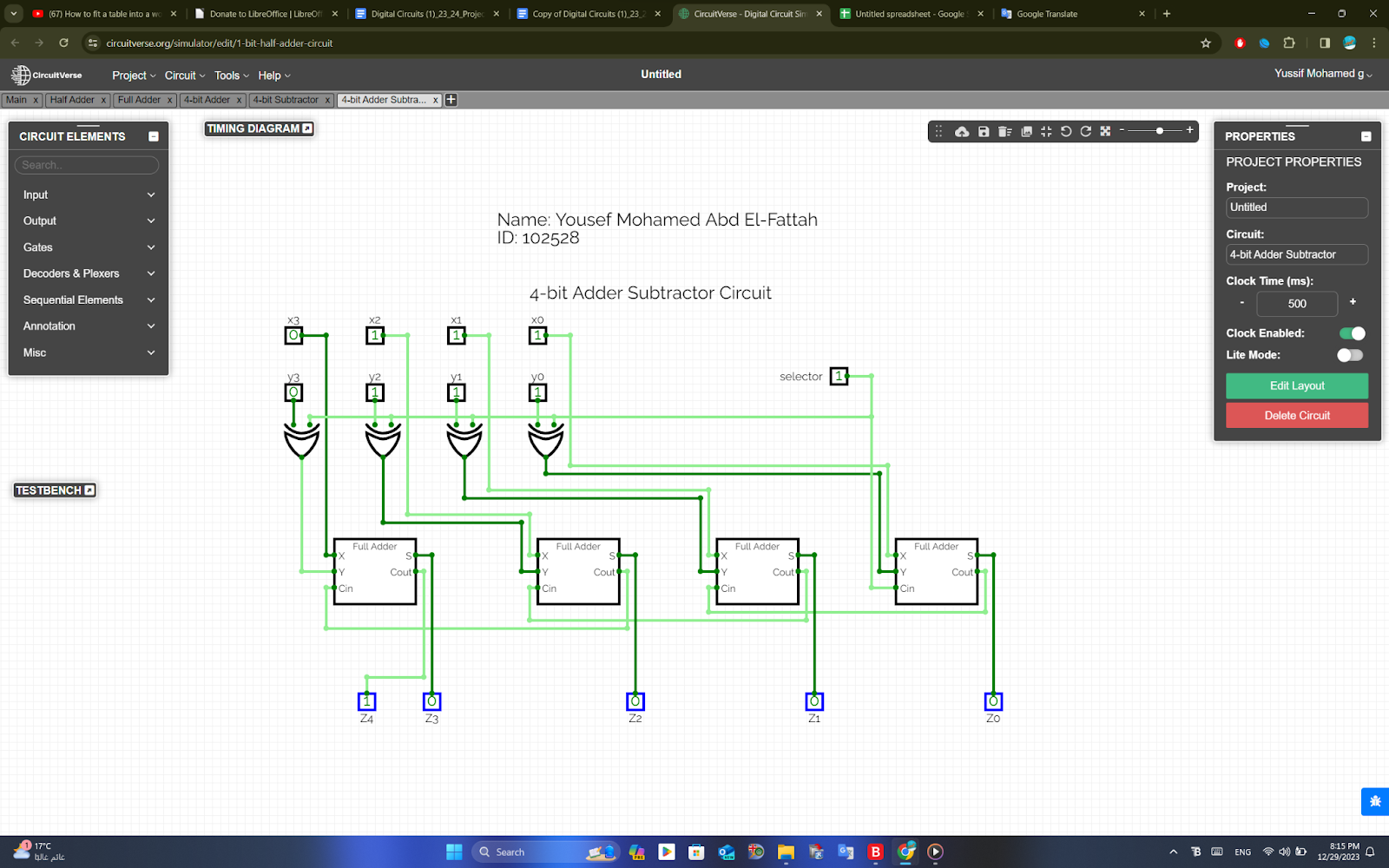
When the input X=(0111) :{x3= 0 ,x2= 1 ,x1= 1 ,x0= 1}
& when the input Y=(0111) : {y3= 0 ,y2= 1 ,y1= 1 ,y0= 1}
∵ selector = 1 ∴ The operation is subtract (Z = X - Y)
the circuit Subtracts using 2’s complement method:
∴ 1’s complement of Y = Y’ = 1000: {y3’= 1 ,y2’= 0 ,y1’= 0 ,y0’= 0}
∴ Z0 = sum of three input digits (x0 , y0’ , Cin)
Z0= x0 + y0’ + Cin = 1 + 0 + 1(selector)= 0 [& 1-carried to next bit Full Adder]
Z1= x1 + y1’ + Cin = 1 + 0 + 1(carry) = 0 [& 1-carried to next bit Full Adder]
Z2= x2 + y2’ + Cin = 1 + 0 + 1(carry) = 0 [& 1-carried to next bit Full Adder]
Z3= x3 + y3’ + Cin = 0 + 1 + 1(carry) = 0 [& 1-carried to next bit Full Adder]
Z4= last carry = 1 (note: we ignore last bit (Z4) in subtract operation & it have to = 1)
when [Z4 = 1] that means [X>=Y]
∴ Z = 0000
Untitled
Untitled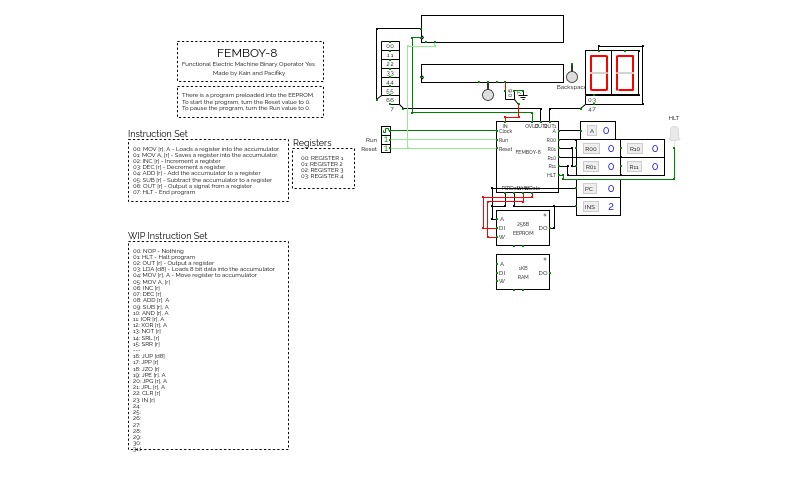
Functional Electronic Machine Binary Operator Yes - 8-bit cpu
This is a work in progress right now.
INSTRUCTION SET:
00: MOV [r], A - Loads a register into the accumulator.
01: MOV A, [r] - Saves a register into the accumulator.
02: INC [r] - Increment a register
03: DEC [r] - Decrement a register
04: ADD [r] - Add the accumulator to a register
05: SUB [r] - Subtract the accumulator to a register
06: OUT [r] - Output a signal from a register
07: HLT - End program
REGISTERS:
00: REGISTER 1
01: REGISTER 2
02: REGISTER 3
04: REGISTER 4
Update Notes:
Final design before update of is a.
To-Do:
Add WIP instructions
Add the accumulator to a register address
Increase amount of registers to 8
Add Ram manipulation instructions
Add Input to CPU
Add more operations to the ALU
Add ASCII i/o
Make a simple command line
Make an assember
Make a simple operating system for the cpu
Add rgb output
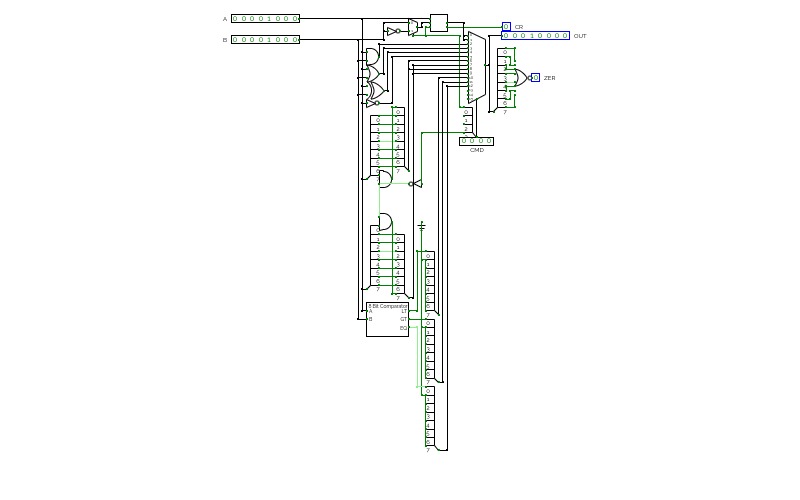
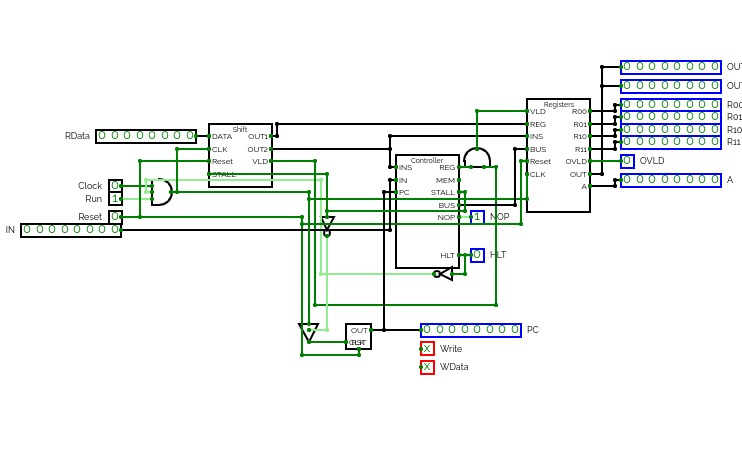
Functional Electronic Machine Binary Operator Yes - 8-bit cpu
This is a work in progress right now.
INSTRUCTION SET:
00: NOP - Nothing
01: HLT - Halt program
02: OUT [r] - Output a register
03: LDA [d8] - Loads 8 bit data into the accumulator
04: MOV [r], A - Move register to accumulator
05: MOV A, [r] - Move accumulator to register
06: INC [r] - Increment a register
07: DEC [r] - Decrememt a register
08: ADD [r], A - Add the accumulator from a register
09: SUB [r], A - Subtract the accumulator from a register
0A: AND [r], A - And the register and accumulator
0B: IOR [r], A - OR the register and accumulator
0C: XOR [r], A - XOR the register and accumulator
0D: NOT [r] - NOT a register
0E: SRR [r] - Shift register right
0F: SRL [r] - Shift register Left
REGISTERS:
00: REGISTER 1
01: REGISTER 2
02: REGISTER 3
04: REGISTER 4
Update Notes:
The instruction set now has 16 instructions with logic operations, loading, shift, and nop.
To-Do:
Add WIP instructions
Add the accumulator to a register address
Increase amount of registers to 8
Add Ram manipulation instructions
Add Input to CPU
Add more operations to the ALU
Add ASCII i/o
Make a simple command line
Make an assember
Make a simple operating system for the cpu
Add rgb output
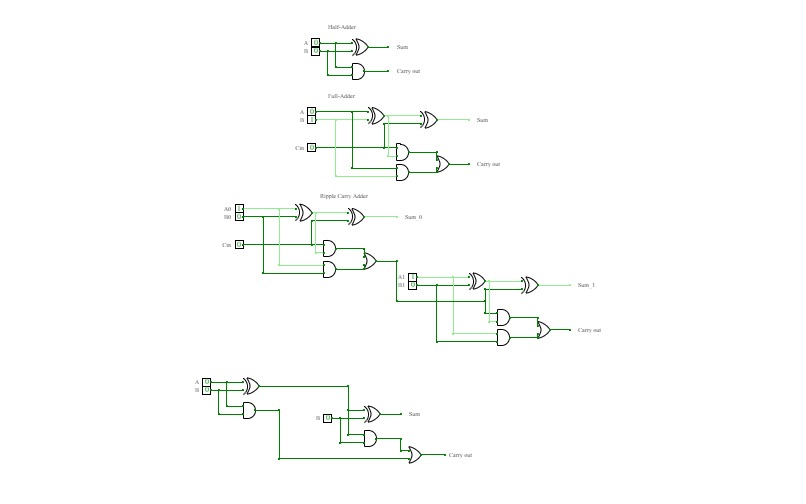
Half and Full Adders
Half and Full Adders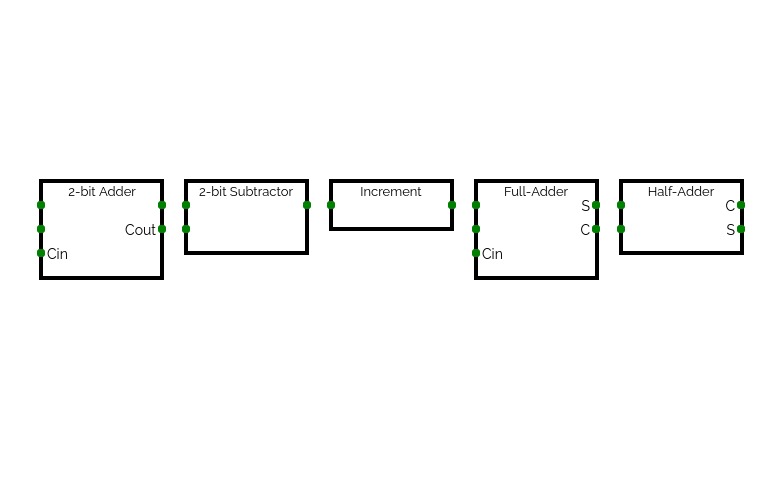
Simple Logic Gate Arithmetic
Simple Logic Gate Arithmetic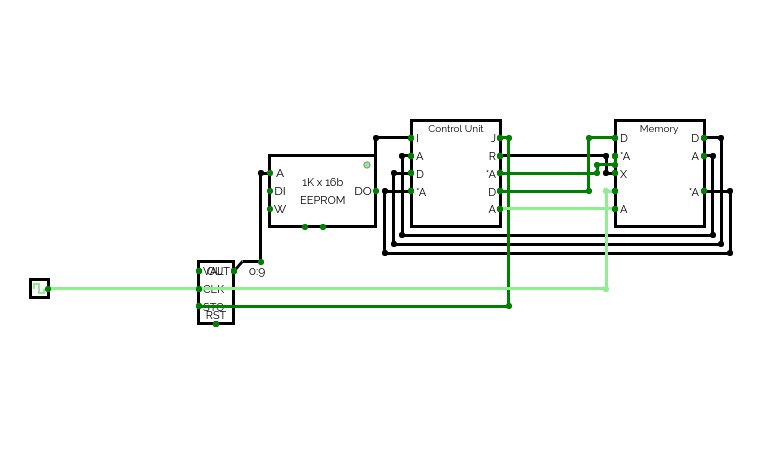
Half-Precision Simple FPU
Half-Precision Simple FPUJust a basic fpu with multiply, subtract, and add
FEMBOY-8v1.3
FEMBOY-8v1.3Functional Electronic Machine Binary Operator Yes - 8-bit cpu
This is a work in progress right now.
INSTRUCTION SET:
00: NOP - Nothing
01: HLT - Halt program
02: OUT [id] - Output the accumulator out of an output
03: LDI A, [d8] - Loads immediate 8 bit word into the accumulator
04: MOV [r], A - Move register to accumulator
05: MOV A, [r] - Move accumulator to register
06: INC [r] - Increment a register
07: DEC [r] - Decrememt a register
08: ADD [r], A - Add the accumulator from a register
09: SUB [r], A - Subtract the accumulator from a register
0A: AND [r], A - And the register and accumulator
0B: IOR [r], A - OR the register and accumulator
0C: XOR [r], A - XOR the register and accumulator
0D: NOT [r] - NOT a register
0E: SRR [r] - Shift register right
0F: SRL [r] - Shift register Left
10: JUP [d8] - Jump to a location
11: JPP [r] - Jump to a register value
12: JPL A, [d8] - Jump if accumulator is less than 0
13: JZO A, [d8] - Jump if accumulator is 0
14: JPG A, [d8] - Jump if accumulator is greater than 0
15: JLE A, [d8] - Jump if accumulator is less than or equal to 0
16: JGE A, [d8] Jump if accumulator is greater than or equal to 0
17: JNZ A, [d8] Jump if accumulator is not 0
18: CLR [r] - Clear a register
19: INP [id] - Store INPUT id in accumulator
1A: MOV pA, [r] - Move the value at address A register r
1B: MOV [r], pA - Move register r into address A
1C: MOV [p], A - Move a value in a pointer to the accumulator
1D: MOV A, [p] - Move the accumulator to a location
1E: MLT [r], A - Multiply register r by the accumulator
1F: DIV [r], A - Divide register r by accumulator
REGISTERS:
00: REGISTER 1
01: REGISTER 2
02: REGISTER 3
04: REGISTER 4
05: ZERO FLAG (R)
06: PC (R)
07: ALU Result (R)
Update Notes:
Welcome to the 3rd iteration of my Femboy-8 CPU! This might be the last version with 32 instructions.
To-Do:
Increase amount of registers to 8
Make a simple command line
Make an assember
Make a simple operating system for the CPU
Add rgb output
FEMBOY-8V1.4
FEMBOY-8V1.4Functional Electronic Machine Binary Operator Yes - 8-bit cpu
Working on a new CPU: Femboy-16
ASSEMBLER:
https://output.jsbin.com/wutikij
INSTRUCTION SET:
00: NOP - Nothing
01: HLT - Halt program
02: OUT [id] - Output the accumulator out of an output
03: LDI A, [d8] - Loads immediate 8 bit word into the accumulator
04: MOV [r], A - Move register to accumulator
05: MOV A, [r] - Move accumulator to register
06: INC [r] - Increment a register
07: DEC [r] - Decrememt a register
08: ADD [r], A - Add the accumulator from a register
09: SUB [r], A - Subtract the accumulator from a register
0A: AND [r], A - And the register and accumulator
0B: IOR [r], A - OR the register and accumulator
0C: XOR [r], A - XOR the register and accumulator
0D: NOT [r] - NOT a register
0E: SAR [d8] - Barrel shift accumulator right
0F: SAL [d8] - Barrel shift accumulator left
10: JUP [d8] - Jump to a location
11: JPP [r] - Jump to a register value
12: JPL A, [d8] - Jump if accumulator is less than 0
13: JZO A, [d8] - Jump if accumulator is 0
14: JPG A, [d8] - Jump if accumulator is greater than 0
15: JLE A, [d8] - Jump if accumulator is less than or equal to 0
16: JGE A, [d8] Jump if accumulator is greater than or equal to 0
17: JNZ A, [d8] Jump if accumulator is not 0
18: CLR [r] - Clear a register
19: INP [id] - Store INPUT id in accumulator
1A: MOV pA, [r] - Move the value at address A register r
1B: MOV [r], pA - Move register r into address A
1C: MOV [p], A - Move a value in a pointer to the accumulator
1D: MOV A, [p] - Move the accumulator to a location
1E: MLT [r], A - Multiply register r by the accumulator
1F: DIV [r], A - Divide register r by accumulator
REGISTERS:
00: REGISTER 1
01: REGISTER 2
02: REGISTER 3
04: REGISTER 4
05: ZERO FLAG (R)
06: PC (R)
07: ALU Result (R)
Update Notes:
So this is the 4th iteration of my CPU lol... I added a few programs for you all to try out and you can even use an assembler now!
To-Do:
Increase amount of registers to 8
Make a simple command line
Make an assember
Make a simple operating system for the CPU
Add rgb output
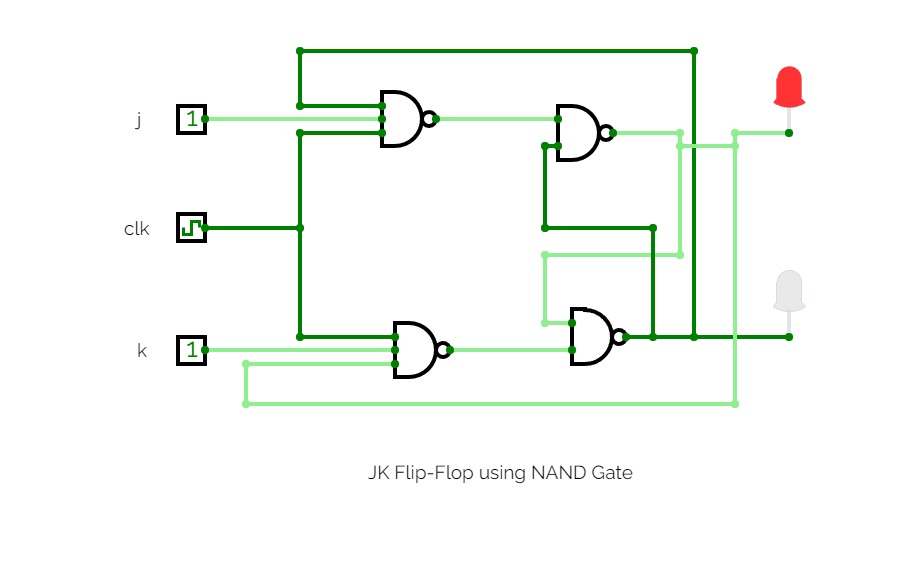
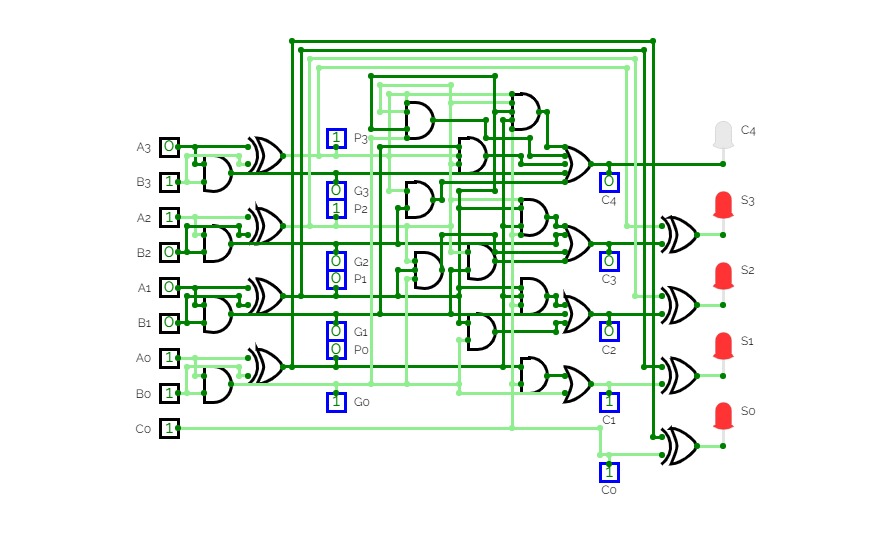
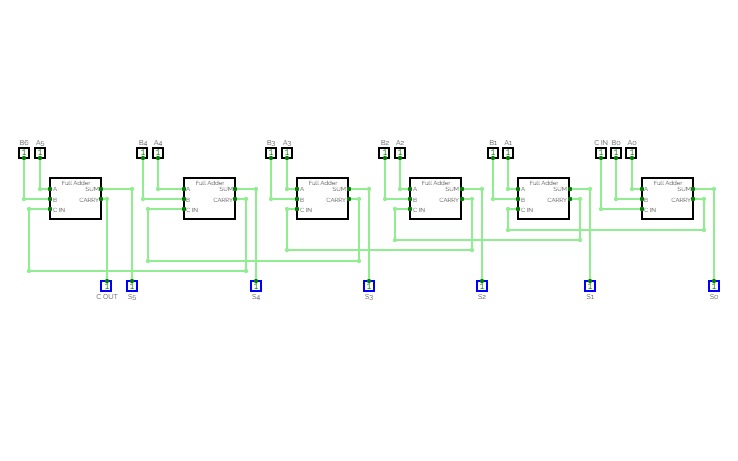

6-bit Ripple Carry Adder
6-bit Ripple Carry AdderTo create a ripple carry adder capable of adding two 6-bit binary numbers, you can connect multiple full adders in a cascaded manner. The carry output of one full adder is fed as the carry input of the next full adder in the chain.
Here's how a 6-bit ripple carry adder operates:
The least significant bits of the two 6-bit binary numbers (A0 and B0) are fed as inputs to the first full adder (FA0) along with a carry-in of 0 (since there's no carry from a lower significant position).
The sum output of FA0 gives the least significant bit of the final sum, and the carry output is fed as the carry-in to the next full adder (FA1).
FA1 takes the second bits of the binary numbers (A1 and B1) as inputs, along with the carry output from FA0 as the carry-in.
This process continues for the remaining full adders (FA2, FA3, FA4, FA5), with each full adder taking the corresponding bits of the binary numbers and the carry output from the previous full adder as inputs.
The sum outputs of each full adder collectively form the final sum, and the carry output of the most significant full adder (FA5) becomes the carry-out of the entire 6-bit ripple carry adder.
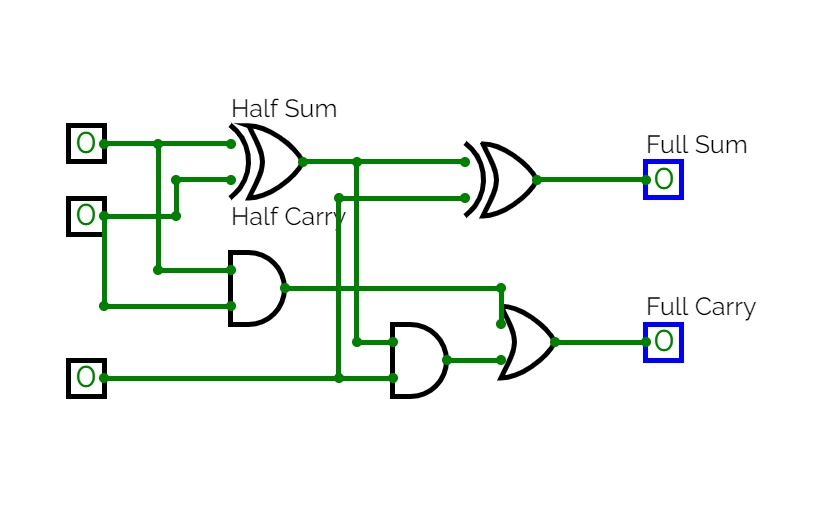
Adders
Adders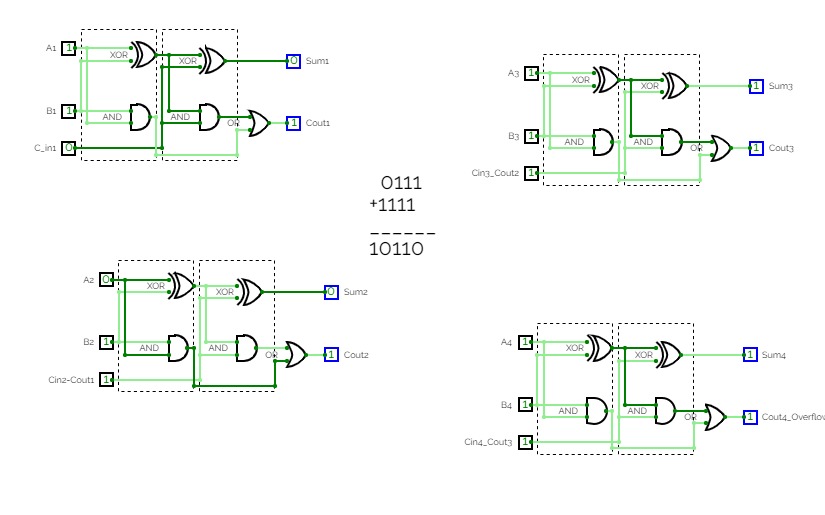
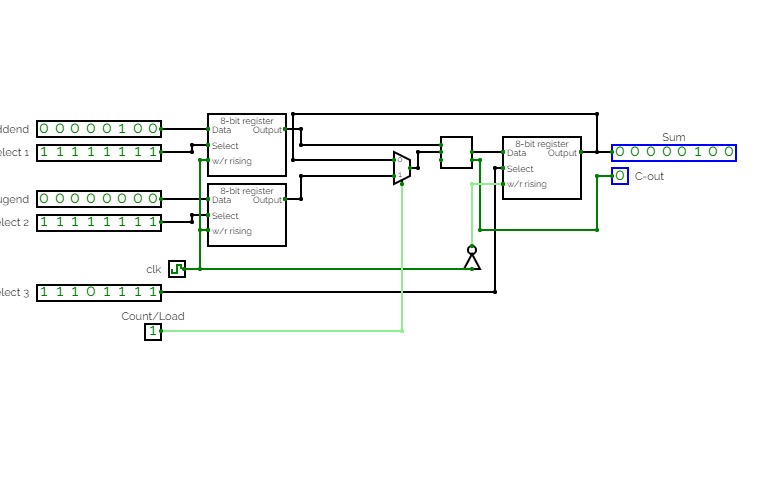
Adjustable 8-bit adder which either loads values from two different registers into an 8-bit adder or sequentially adds the current output value of the adder to the value stored in the first register. Practice for RAM unit application, register creation and organization, bit splitting and compression, and sequential logic.
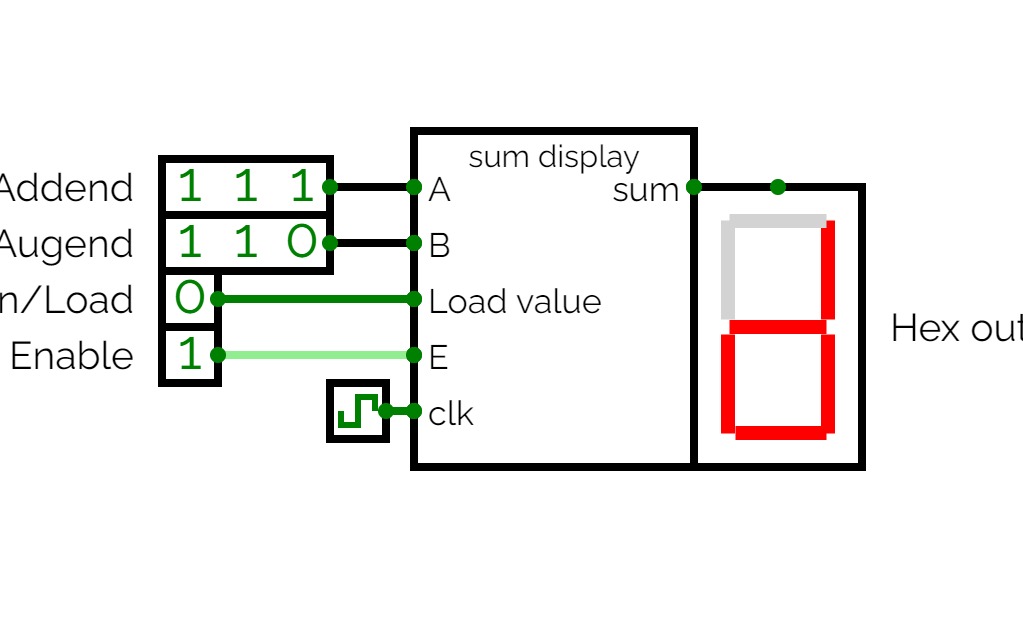
Untitled
Untitled3-bit sequential adder that saves the output sum to a 4-bit shift register and displays the output on a hex 7-segment display.



Half - Adder
Half - Adder
Full Adder
Full Adder

Somador/Subtrator Controlado
Somador/Subtrator Controlado
LAB MANUAL
LAB MANUAL

Kogge Stone
Kogge StoneA Kogge Stone adder